对抗知识焦虑,从看懂这条开始
App 下载
英伟达用200亿,把AI推理拆成了两份工作
效率瓶颈|AI推理|Vera Rubin平台|Groq芯片|英伟达|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载效率瓶颈|AI推理|Vera Rubin平台|Groq芯片|英伟达|AI算力|人工智能
圣何塞的SAP中心挤了3万多人,连手机信号都被挤断了——这是2026年英伟达GTC大会的现场。没人是来抢游戏显卡的,所有人都盯着黄仁勋嘴里的那个数字:到2027年,全球AI算力需求将达1万亿美元。
但真正让业内人攥紧拳头的不是这个天文数字,而是黄仁勋掏出的那套“组合拳”:用200亿美元收购的Groq芯片,和刚发布的Vera Rubin平台绑在了一起。这不是简单的硬件堆叠,而是把AI推理这个活儿,硬生生拆成了两份。为什么要拆?这得从AI最头疼的“效率瓶颈”说起。
你可以把AI生成内容的过程想象成写论文:第一步是读参考文献,把所有相关信息都装进脑子里——这对应AI的“预填充(Prefill)”阶段,需要一口气处理大量输入数据,是个纯粹的计算苦力活,适合用GPU这种擅长并行计算的“超级计算器”。
但第二步写论文就不一样了:你得一个字一个字往下敲,每写一句都要回头看前面的内容衔接——这就是AI的“解码(Decode)”阶段,它必须按顺序生成每一个token(可以理解为语言的最小单位),GPU的并行优势在这里完全没用,反而会因为等待内存数据而陷入闲置,资源利用率甚至不到10%。
过去所有人都在想怎么让GPU更高效地同时干这两份活,比如压缩数据、优化算法,但都是“扬汤止沸”。黄仁勋的思路简单粗暴:既然两份活的脾气完全不搭,那就找两个专门的工人来干。
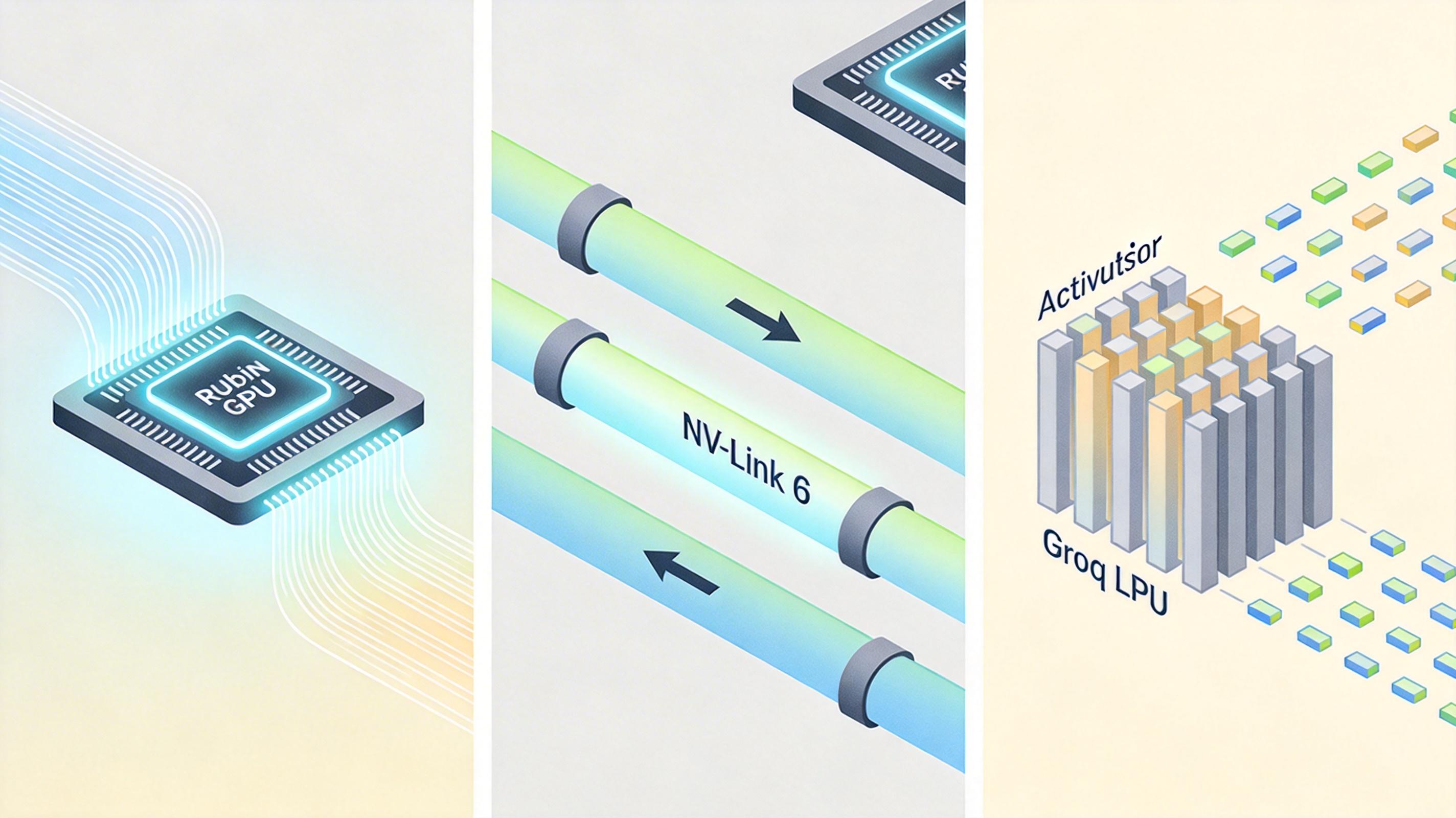
Vera Rubin平台里的72颗Rubin GPU,就是负责“读文献”的苦力——它有50 PFLOPS的NVFP4推理性能,HBM4内存带宽达到22TB/s,能以最快速度把输入上下文转换成AI能理解的格式。而Groq的LPU(语言处理单元),则是专门“写论文”的快手:它的片上SRAM带宽高达80TB/s,能以几乎无延迟的速度调取之前的计算结果,token生成速度是GPU的7倍。
这种“让专业的干专业的”架构,就是英伟达喊出的“分离推理(Disaggregated Inference)”。
具体来说,当你给AI发了一个长文本请求,Rubin GPU会先一口气完成预填充计算,把所有中间结果通过高速NVLink 6互联(单GPU带宽3.6TB/s)传给Groq LPU集群;接下来的每一个token生成,都由Groq LPU独立完成,不需要再占用GPU资源。整个过程就像工厂的流水线,预填充和解码在两个完全独立的工位上同时进行,互不干扰。
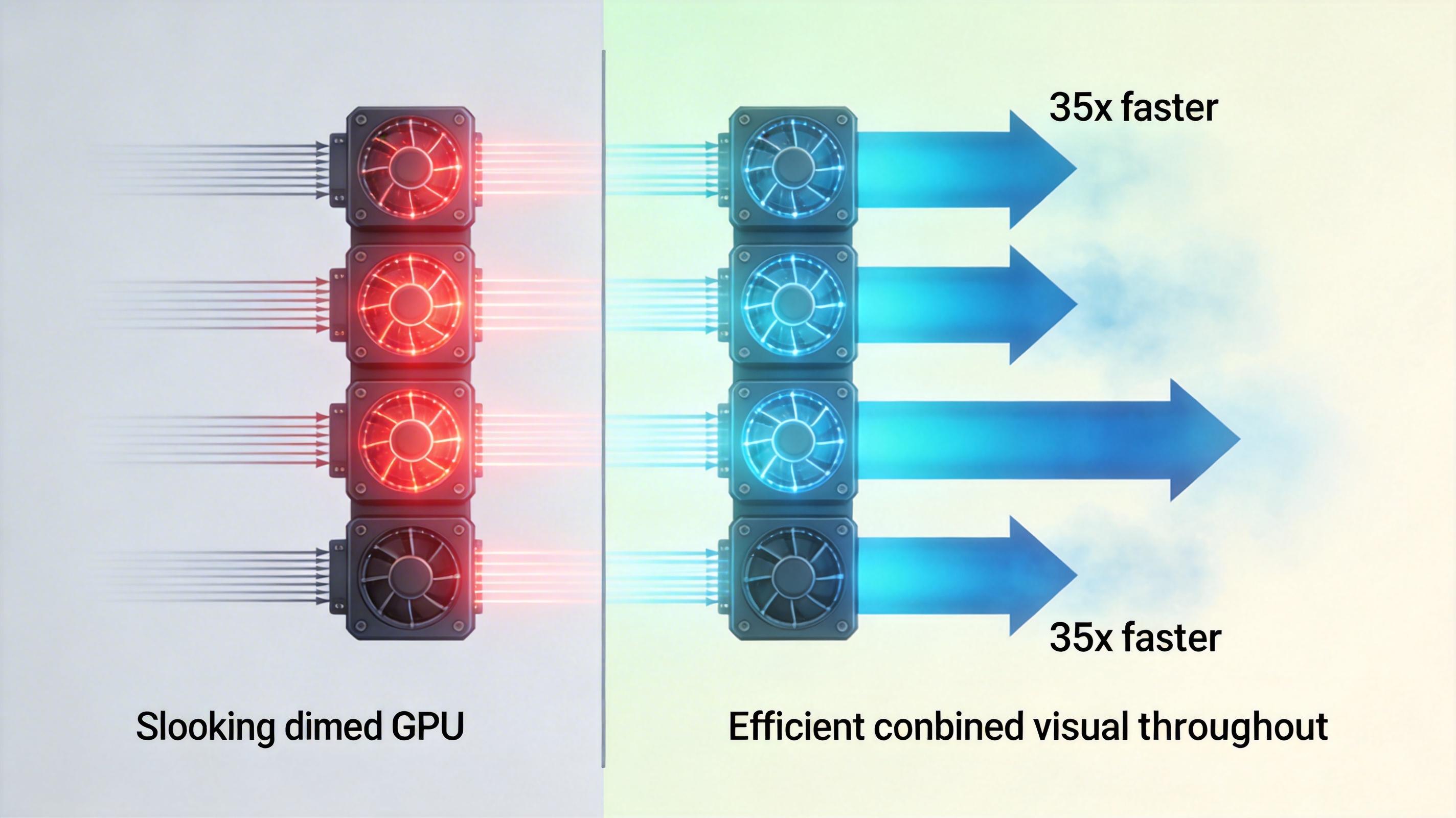
英伟达给出的实测数据让人咋舌:在高频对话这种实时推理场景下,这套组合拳的性能比纯GPU架构提升了35倍,推理成本直接降了10倍。更关键的是,它解决了长上下文推理的“噩梦”——当你让AI处理百万级token的文档时,GPU会因为内存占用过高而卡顿,而Groq LPU的分布式架构可以轻松扩展,支持几乎无限长的上下文。
这不是英伟达的独家发明,但它是第一个把这套逻辑落地到量产级硬件的厂商。Vera Rubin平台的机架设计本身就是为分离推理量身定做的:垂直安装的GPU模组和Groq LPX托盘,通过45度温水液冷系统统一散热,整个机架没有一根外露线缆,组装速度比上一代快18倍。微软Azure已经把这套系统塞进了他们的Fairwater AI超级工厂,用来支撑下一代智能体的实时交互。

分离推理带来的不只是性能提升,更是AI应用场景的爆炸式扩展。
过去,实时交互类AI(比如智能客服、自动驾驶的决策系统)因为推理延迟太高,只能用小模型或者牺牲精度;现在有了Groq LPU的低延迟解码,大模型也能实现毫秒级响应——你可以让AI在自动驾驶过程中实时分析路况,或者让智能助理在电话里和客服流畅对答,而不是像以前那样卡顿半天。
对企业来说,成本的下降更是致命诱惑。之前很多企业因为推理成本太高,不敢把AI用在高频场景,比如每一个客户的售后咨询、每一份合同的条款审核;现在推理token成本降了10倍,这些场景都变得有利可图。就连制药公司Eli Lilly都在搭建自己的私有推理集群,用AI实时分析临床试验数据——放在以前,这需要的算力成本足以让财务部门否决项目。
更重要的是,分离推理打破了“GPU垄断”的僵局。以前AI推理只能靠GPU,现在企业可以根据需求灵活组合GPU和LPU:如果是批量处理文档,就多买GPU;如果是实时对话,就多配LPU。这种模块化的选择,让中小企业也能负担得起AI算力,不用再看着云服务商的价格表叹气。
当黄仁勋在发布会上调侃“GeForce是英伟达最成功的营销活动”时,台下的3万人都在笑——但没人否认,正是当年游戏玩家买显卡的钱,堆出了今天AI算力的护城河。
现在,英伟达又把这条护城河挖得更深了。分离推理不是什么颠覆式的黑科技,它更像是一种“回归常识”的创新:既然AI的推理过程天生就有两种完全不同的需求,为什么非要用一种硬件去满足?
算力的终极形态从来不是“更快的芯片”,而是“更合适的分工”。当AI终于不用再“一手拿书一手写字”,它才能真正跑起来——跑到每一个需要实时响应的场景里,跑到每一个负担不起高额成本的企业里,跑到我们以为AI还到不了的地方。
算力的未来,是专业的人干专业的活。