对抗知识焦虑,从看懂这条开始
App 下载
Dropbox用AI放大人力100倍,破解搜索瓶颈
检索增强生成|AI自动标注|企业文档搜索|Dropbox|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载检索增强生成|AI自动标注|企业文档搜索|Dropbox|大语言模型|人工智能
想象一下,你在公司的十亿份文档里搜一个内部工具,结果出来的全是饮料广告——这不是玩笑,是Dropbox工程师曾面临的真实困境。当企业文档库膨胀到数十亿级别,哪怕只把万分之一的内容传给大语言模型,都可能让系统过载。而决定搜索结果好坏的,恰恰是那些标注着「这份文档和用户查询到底有多相关」的标签。过去,这些标签全靠人工标注,成本高到离谱,速度慢到拖垮项目。直到2026年,Dropbox找到了破局的钥匙:让大语言模型当「标注助理」。但问题是,AI的判断真的靠谱吗?
先得搞懂一件事——检索增强生成(RAG)系统,就是先从海量文档里捞出相关内容,再喂给大语言模型生成回答的工具,相当于AI的「外置知识库」。而要让这个「知识库」好用,就得先训练一个「排序模型」:给每一对「用户查询-文档」打个分,分越高的文档越先被传给大语言模型。
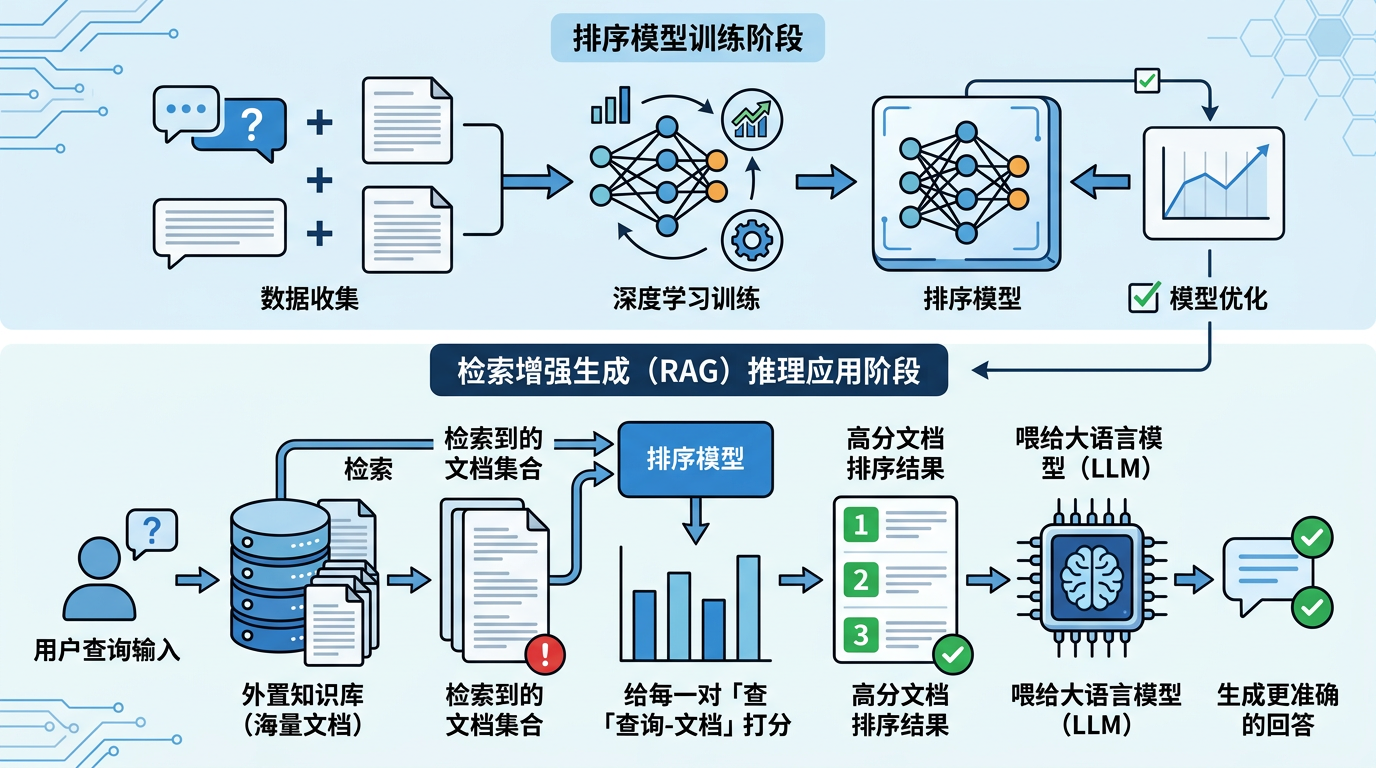
过去训练这个模型,全靠人工标注。但人工标注有多坑?一个标注员一天最多标几百对,成本是每千对几百美元,还容易出现「今天觉得相关,明天觉得不相关」的一致性问题。Dropbox的解决方案,是把人工和AI拧成了一个闭环:先让人类标注几百对高质量的「标准答案」,用这些答案校准大语言模型的判断标准;等AI学会了怎么打分,再让它去标几十万甚至几百万对。
这个流程被称为「人工校准的大语言模型标注」,直接把人工工作量放大了100倍。你可以把它想象成:老师先给学生改100篇作文,讲清楚评分标准,再让学生去改10000篇——效率翻了百倍,还能保证评分尺度一致。
但AI不是完美的评分员。研究显示,大语言模型在相关性标注里普遍存在「过度评分」偏差——给不相关的文档打高分,而且哪怕判错了,它自己还信心满满,置信度能飙到98%。比如在Dropbox内部,「diet sprite」是一款性能工具,但如果不给AI提供上下文,它会直接把这个词和饮料挂钩,把相关的技术文档标成不相关。
Dropbox的应对办法,是给AI开了个「上下文外挂」:让它在判断前先额外检索相关文档,搞懂内部术语的真实含义。同时,他们会专门盯着那些「AI判断和用户行为打架」的案例——比如AI说某篇文档不相关,但用户偏偏点了进去;或者AI说相关,用户却直接跳过。这些案例是最好的「错题集」,能帮AI快速校准判断标准。
他们还用上了自动提示工程工具DSPy,不用人工写提示词,系统会自动调整提示的结构和示例,让AI的判断更精准。就像给评分老师不断优化评分细则,减少主观偏差。
直接用大语言模型做实时标注,就像用超级跑车拉货——性能够强,但成本太高,还容易堵车。Dropbox的做法是,用大语言模型生成的标注数据,去微调一个轻量级的小模型。比如用10亿参数的LLaMA模型,经过微调后,它的标注速度比大模型快17倍,成本降低19倍,准确率却能和大模型持平。
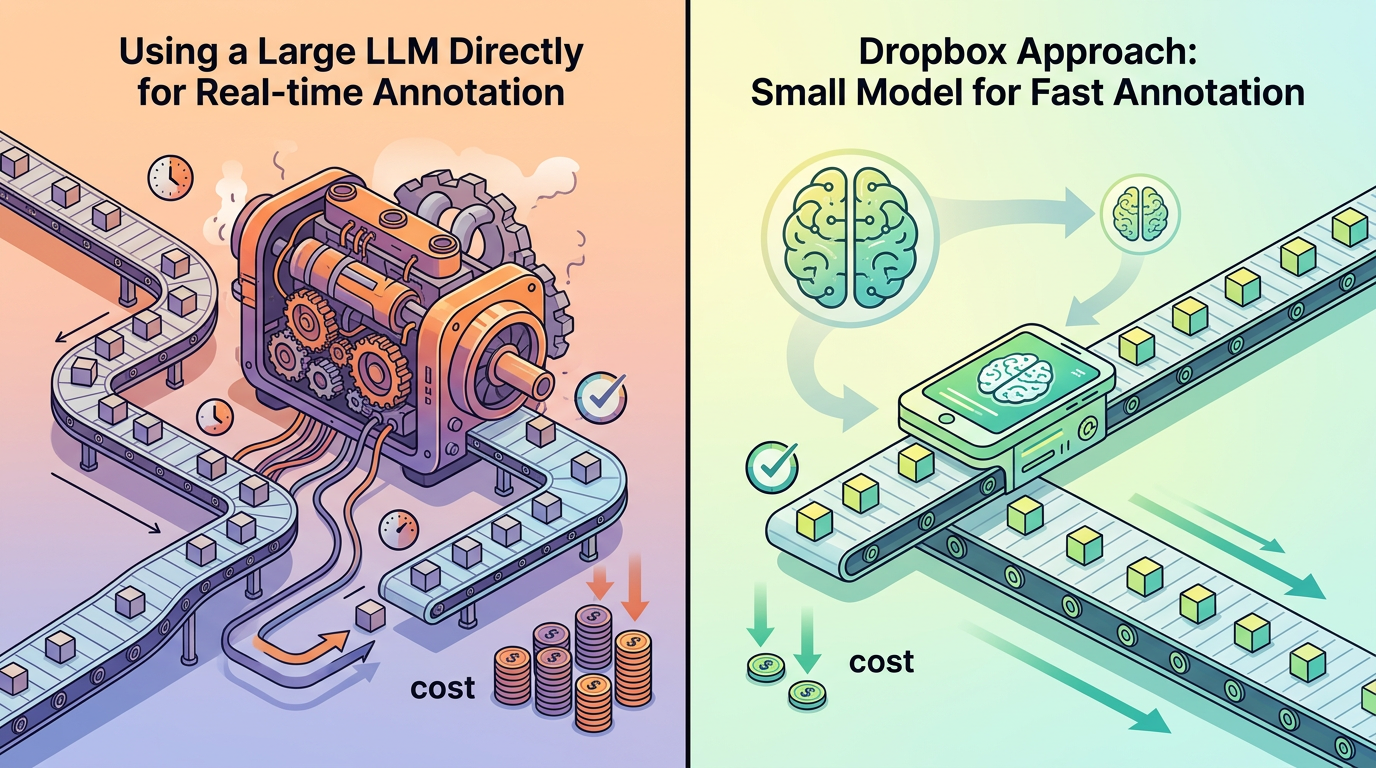
这个轻量级模型就像专门负责拉货的卡车,虽然跑不过超级跑车,但胜在稳定、便宜、能批量运输。它能轻松处理企业级的大规模标注需求,而且可以部署在本地服务器上,不用怕敏感数据泄露。
我认为,这才是Dropbox方案里最被忽略的细节:他们没有把大语言模型当终点,而是用它当「数据工厂」,生产出训练小模型的原料,最终落地的是一个既高效又低成本的可量产系统。
当企业的文档库从百万级跃升到十亿级,传统的人工标注已经跟不上数据膨胀的速度。大语言模型的出现,不是要取代人类标注,而是要把人类的判断能力放大100倍、1000倍。
「人机协同,不是人指挥AI,而是互相校准。」这句话或许能概括这个方案的核心。人类给AI立规矩,AI帮人类干脏活累活,再用用户的真实行为给两者都纠错。在这个循环里,AI的偏差被不断修正,人类的效率被持续放大,最终让RAG系统能在十亿级的文档海里,精准捞出用户需要的那一页。
未来的企业搜索,不会是AI的独角戏,而是人和AI一起,在数据的迷宫里找出口。