对抗知识焦虑,从看懂这条开始
App 下载
拖一下鼠标,视频里的物体就换道
物理规则模拟|视频物体编辑|KTH团队|Adobe研究院|TrajectoryMover技术|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载物理规则模拟|视频物体编辑|KTH团队|Adobe研究院|TrajectoryMover技术|AIGC|人工智能
你有没有过这样的念头:把视频里滚向桌角的苹果,悄悄挪到桌面中间继续转;或者让投篮偏出的篮球,换个角度空心入网?以前这只能靠重拍或逐帧抠图,折腾好几天都未必自然。但现在,你只需要在视频第一帧画两个框——红框圈住要改的物体,绿框标上新起点——AI就能自动生成一段全新视频:物体从新位置出发,保持原来的运动节奏,还会智能适应新环境的物理规则,比如滚到洞边会掉下去,碰到墙会反弹。这不是特效软件的新功能,而是Adobe研究院和KTH团队刚推出的TrajectoryMover技术。但你可能想不到,这项看似简单的功能,背后藏着AI训练的经典死局——以及一个硬核到离谱的破局方案。
AI学新技能的逻辑很像人类:得先看足够多“正确答案”。但TrajectoryMover要解决的问题,偏偏没有现成的“答案”——现实中根本找不到两段只有一个物体轨迹不同、其他完全一致的视频。没有成对的“问题-答案”数据,AI根本不知道“移动物体轨迹”到底要做什么。
团队没有退而求其次用近似数据,而是直接动手造了一个“平行视频宇宙”——TrajectoryAtlas合成数据流水线。这个流水线像全自动电影工厂:输入3D场景、3D物体模型和虚拟摄像机,就能批量生成成对的“轨迹平移”视频对。比如在同一个客厅场景里,让篮球从沙发左边和右边分别滚落,用物理引擎模拟重力、碰撞,最后渲染成两段除了篮球起点不同、其他完全一致的视频。
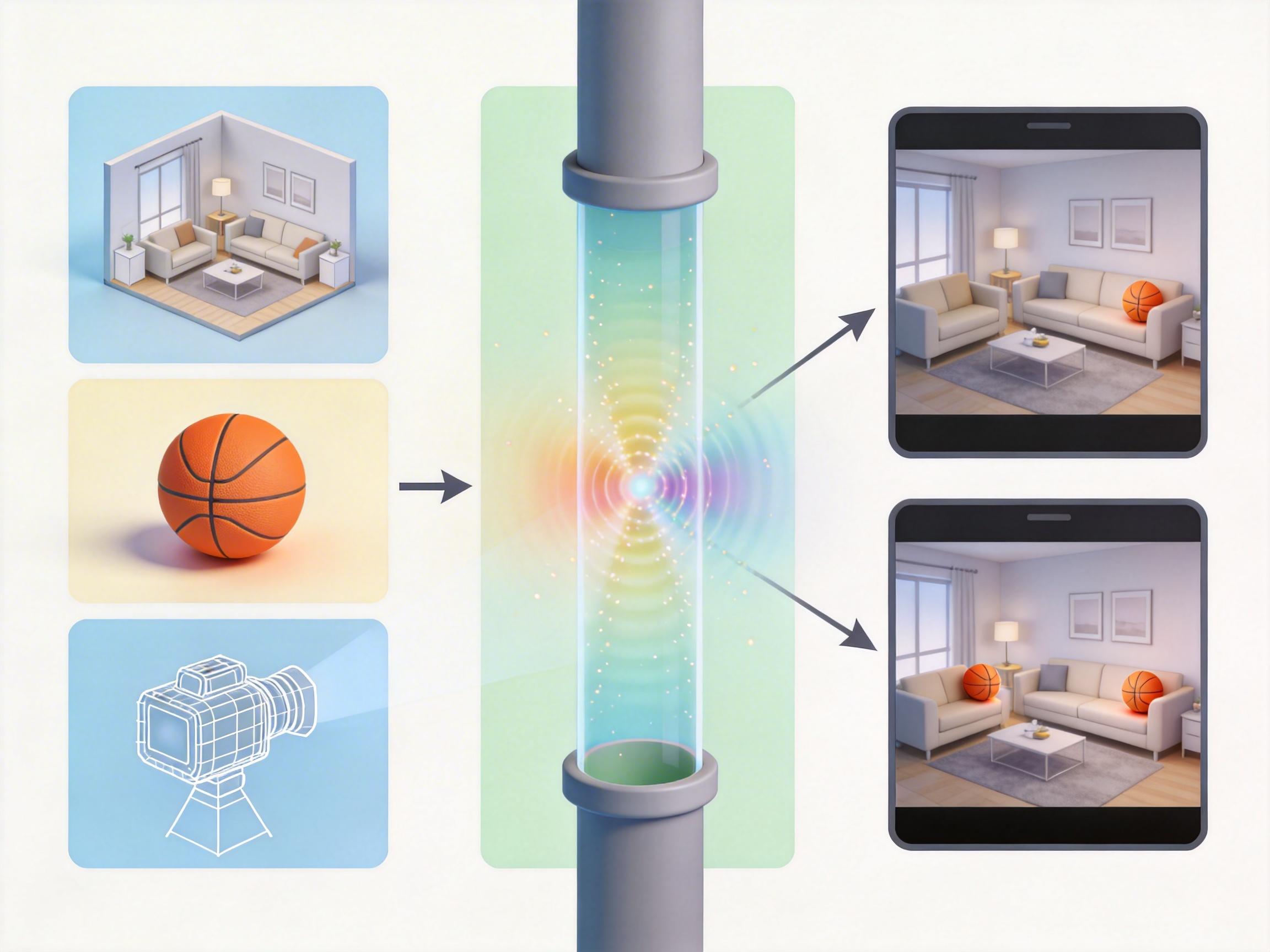
为了让AI能应对复杂情况,他们还加了两个关键设计:一是模拟掉落、抛出、滚动、拖动等5种运动类型,确保AI见过各种运动逻辑;二是“在线场景修改”——随机删掉物体运动路径上的非结构性障碍物,比如地上的玩具、散落的书本,让AI既能学习无阻碍的纯粹平移,也能理解有障碍时的物理交互。最终这个“宇宙”产出了2.1万对1280×720分辨率的视频,每段81帧,成了AI的“教科书”。
有了数据,接下来是训练模型。团队选了现成的强大视频扩散模型Wan2.1-T2V-1.3B——它已经看过海量真实视频,知道“正常的视频该是什么样”。但直接用合成数据微调,很容易让AI“学偏”:生成的视频会像游戏CG一样假,完全脱离真实世界的质感。
他们用了一个叫“交替训练”的策略,完美解决了这个问题:70%的训练批次用合成数据学“轨迹平移”,30%的批次用真实视频做“无条件生成”——也就是让AI复习“怎么生成正常视频”。同时只微调模型的自注意力层和投影层,冻结其他大部分参数,相当于只给AI加装“轨迹控制模块”,不改动它原本的“真实感记忆”。
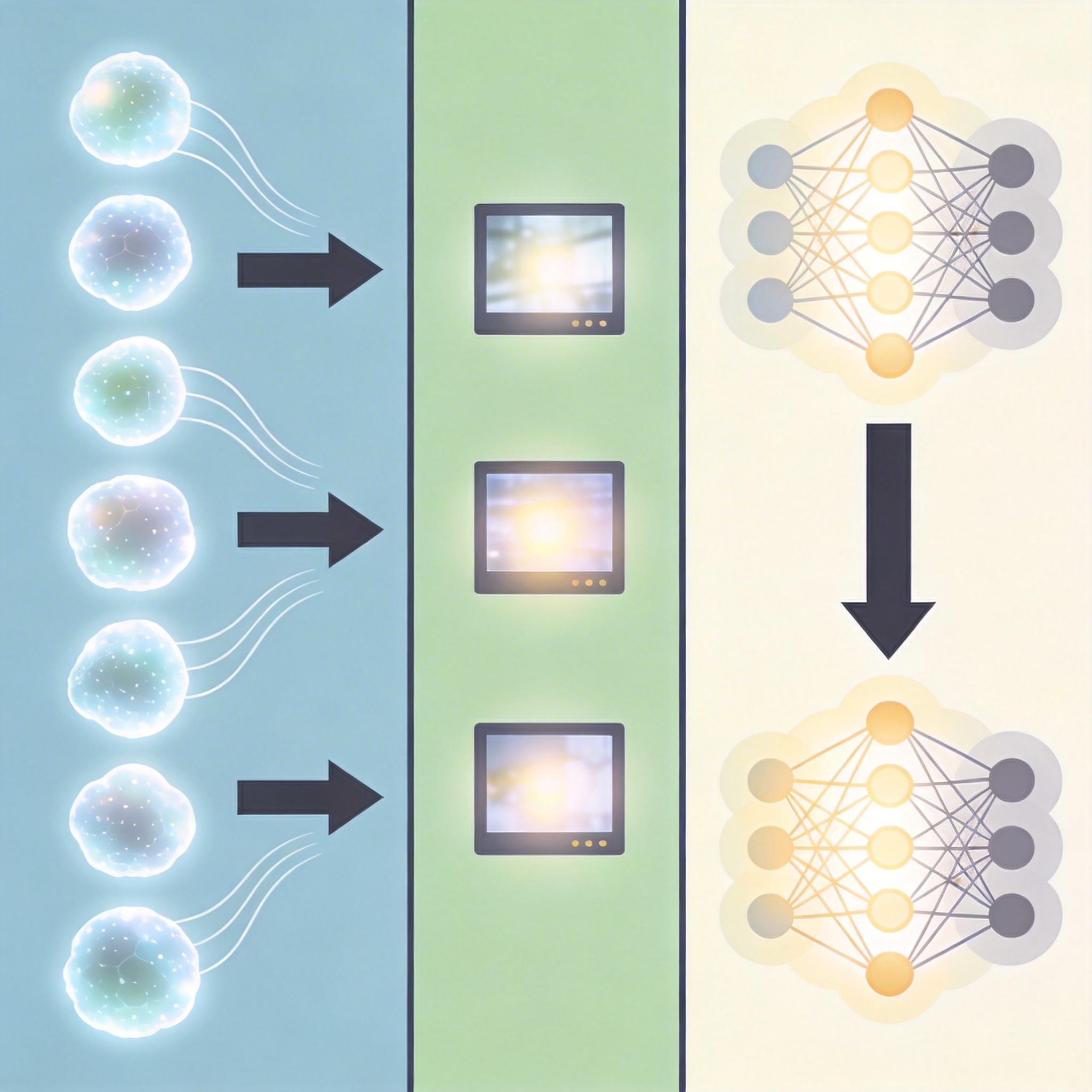
模型的输入方式也很巧妙:把源视频、红绿框控制图、目标视频(初始是纯噪声)的潜码在时间轴上拼接成一个长序列,就像把“参考样本”“指令”“空白画布”钉在一起给AI看。生成时只更新目标视频的潜码,相当于让AI盯着原视频和指令,一点点把噪声“画”成新视频。
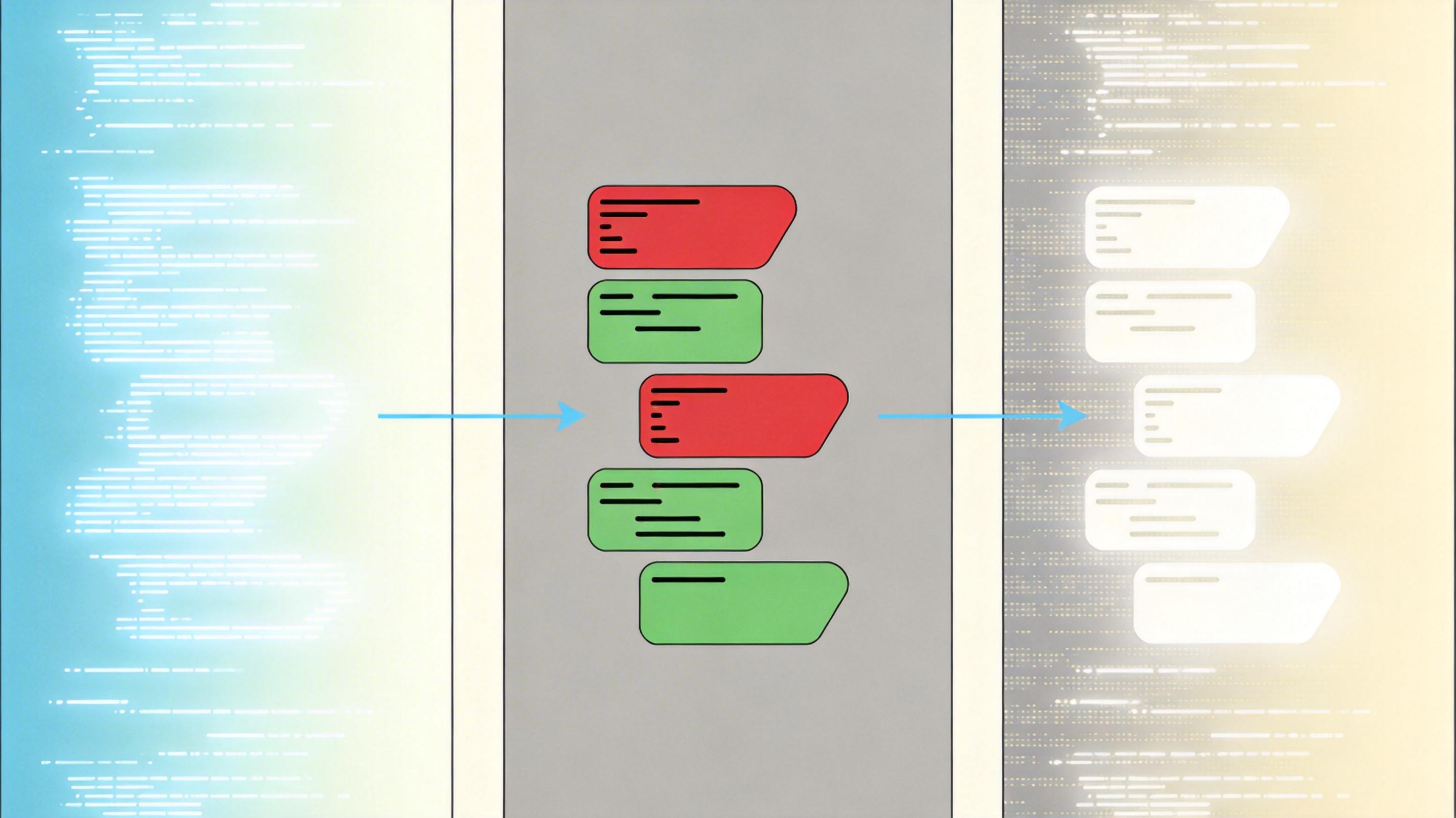
测试结果证明了这套方案的有效性:在背景保持、物体身份保持、轨迹跟随精度三项核心指标上,TrajectoryMover全面领先现有方法。人工评测中,它的得分是1.25,而其他方法要么是负数,要么接近0——用户一眼就能看出它生成的视频更自然。
但它的能力边界也很清晰:目前只能处理刚体物体,对人物、动物这类非刚体的复杂变形还无能为力;轨迹平移的精度还有提升空间,偶尔会出现物体轻微形变或轨迹偏差;而且它完全靠合成数据训练,对真实世界视频的泛化能力还需要验证。
更值得关注的是,TrajectoryMover打开的是一个全新的视频编辑方向。未来,我们或许不用只局限于“平移”:可以直接拖拽轨迹上的任意点来弯曲路径,让球画出弧线绕过障碍物;可以让多个物体的轨迹联动,比如滚动的球撞飞另一个球;甚至可以用文字指令来控制——“让猫从沙发跳到茶几”,AI就能自动生成符合物理规则的运动视频。
TrajectoryMover的意义,不止于“拖一下就能改视频”。它让我们看到,当AI遇到“没有数据”的死局时,最硬核的解法不是妥协,而是亲手创造数据;也让我们意识到,AI的“智能”从来不是凭空出现,而是靠人类用最朴素的逻辑——“先给足够多的正确答案”——一点点喂出来的。
当我们习惯了用AI生成图片、视频,TrajectoryMover把AI的能力从“创造内容”推进到了“编辑运动”。它没有追求炫目的特效,而是解决了一个最接地气的痛点:让普通人也能轻松掌控视频里的运动逻辑。
数据不是终点,是创造力的起点。 未来的视频创作,或许不再是“拍什么”,而是“想让它怎么动”。