对抗知识焦虑,从看懂这条开始
App 下载
机器人跑赢人类半马,却困在数据荒漠里
步态控制|360度摄像头|液冷系统|半马赛道|人形机器人|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载步态控制|360度摄像头|液冷系统|半马赛道|人形机器人|具身智能|人工智能
2026年北京亦庄的半马赛道上,一台人形机器人以50分26秒冲过终点——这个成绩比人类世界纪录还快了7分钟。它的关节带着液冷系统的余温,360度摄像头扫过欢呼的人群,步态稳得像个职业运动员。但没人会真的把它当成对手:这台能跑赢人类的机器人,在工厂流水线里只会做固定动作,在舞台上的武术表演憨态百出,连自主捡起地上的螺丝刀都要试十几次。它的身体已经追上了人类,智能却还停留在蹒跚学步的阶段。这背后藏着一个比机器人跑步更棘手的难题。
具身智能——就是让AI附着在机器人这类物理载体上,像人一样感知、行动和学习——的核心,从来不是跑得有多快,而是有多“懂”这个世界。就像人类的智能来自从小到大的摸爬滚打,机器人的智能也需要海量真实世界的“练习数据”:比如拿起水杯时的力度反馈、在湿滑地面走路的重心调整、识别不同材质的物体该怎么抓握。
但这些数据,比大语言模型的文本数据难搞一万倍。ChatGPT可以爬取整个互联网的书籍、帖子当练习册,机器人却必须真刀真枪地在现实里试错:碰碎100个杯子,才知道怎么拿稳第101个;摔200次跤,才学会在瓷砖地上怎么落脚。采集一小时这样的真机数据,成本至少200元,还要调动视觉、触觉、力觉等十几种传感器。
更关键的是,现在整个行业凑起来的高质量真机数据,也就50万小时——而要等到机器人的智能“涌现”,也就是像大语言模型那样突然具备举一反三的能力,业内估算至少需要1亿小时。这就像一个小学生,刚学了100个汉字,就要写一篇高考作文。
为了填满这个数据黑洞,行业拼出了一个“数据金字塔”:最顶端是金贵的真机数据,每一秒都带着真实物理世界的反馈;中间层是仿真数据,在虚拟环境里让机器人无限次练习,成本只有真机的十分之一;最底层是人类视频数据,从互联网上扒取人类的动作视频,让机器人先“看会”再“学会”。
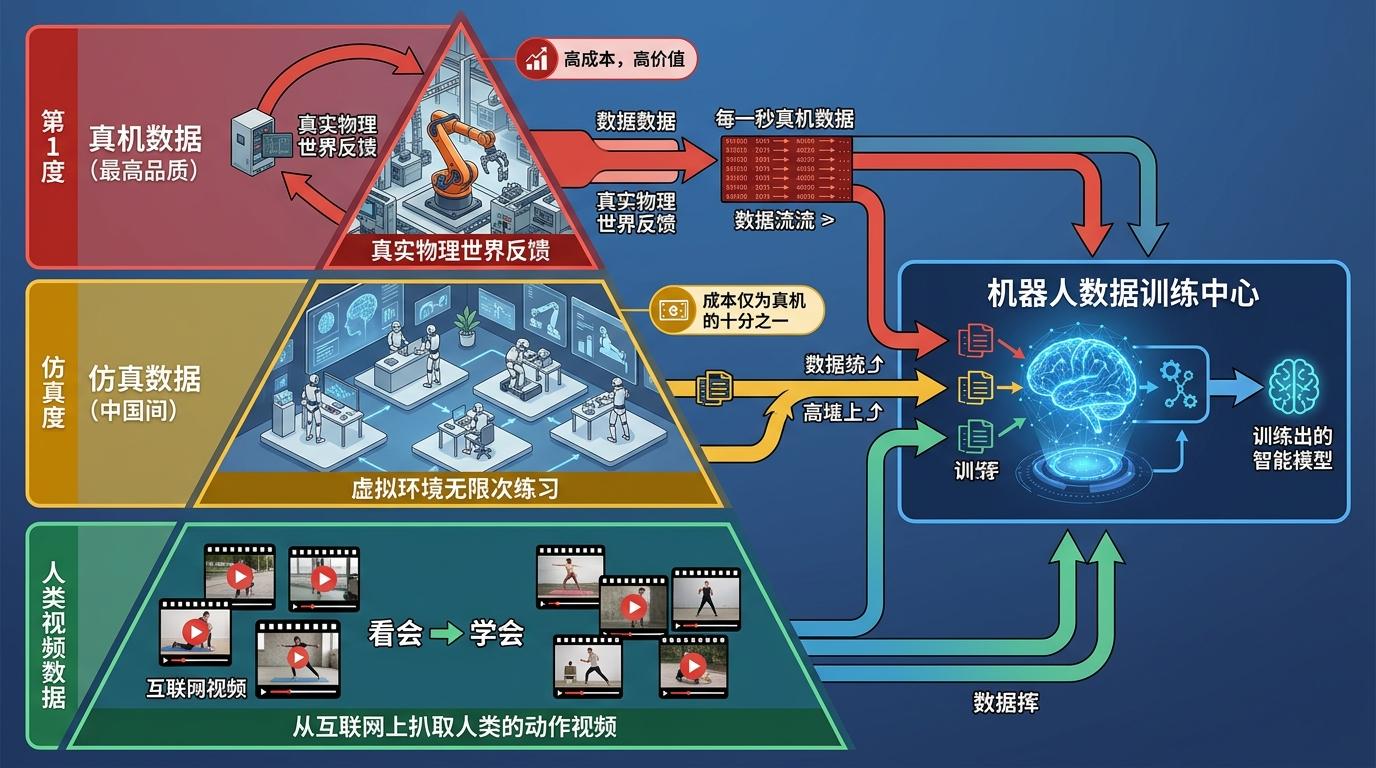
但这三层数据各有各的坎。真机数据不仅贵,还像一个个孤岛:不同企业用不同格式存储,标注标准也不统一,你家机器人“拿起杯子”的数据,放到我家机器人的模型里根本用不了。仿真数据虽然便宜,却永远和真实世界隔着一层——虚拟环境里拿稳的杯子,到了现实里换个材质就可能失手。人类视频数据倒是多,却没有触觉、力觉这些关键信息,机器人看1000次人类拿杯子,也不知道该用多大劲。
更要命的是,现在连怎么判断数据好不好都没标准。以前大家只看数据量,以为堆得越多越好,直到发现很多数据都是重复的“垃圾”——比如同一个机器人在同一个房间里拿了1000次同样的杯子,对智能提升毫无帮助。现在有人提出用“多样性熵”来衡量,看数据覆盖了多少不同场景、不同动作,但这套方法还在实验室里打转。
一些企业已经开始动手填这个坑。觅蜂科技计划在2026年产出千万小时级的数据,靠的是把真机采集、仿真生成和人类视频转化打包成流水线;Shutu科技的SynaData技术,能把互联网上的普通视频自动拆解成机器人能用的动作数据,成本降到了真机采集的千分之一。
但更聪明的思路,是提升数据的利用效率。极佳视界的团队发现,用几十万个小时的数据训练模型,每年要烧掉几千万的GPU费用,如果真要凑够1亿小时,成本根本扛不住。他们开始给模型“减肥”,优化架构让它能从更少的数据里学到更多东西——就像一个学霸,看一遍书就能记住,而不是靠死记硬背刷100套题。
还有人盯上了“失败数据”。北大发布的RoboMIND数据集里,专门收录了5000条机器人失败的轨迹:比如抓杯子时手滑了、走路时被电线绊倒了。以前大家都把这些数据当垃圾,现在发现,从错误里学东西,可能比从成功里学更快——就像人类摔过一次跤,下次就会注意脚下的石头。
当那台机器人冲过半马终点线时,全场的欢呼里藏着对未来的期待:总有一天,机器人能像人一样灵活、聪明,走进工厂、家庭,帮我们做所有不想做的事。但很少有人注意到,这台跑赢人类的机器人,其实还在数据的荒漠里蹒跚。
数据不是石油,挖出来就能用;它更像土壤,要先开垦、施肥、育种,才能长出智能的果实。机器人的智能涌现,始于数据的厚积薄发。这场关于数据的马拉松,才刚刚鸣枪起跑。