对抗知识焦虑,从看懂这条开始
App 下载
模型砍半还更准,车载3D感知的破局之道
点云配准算法|三维目标检测模型|激光雷达|点云数据|车载3D感知|智能制造|多模态视觉|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载点云配准算法|三维目标检测模型|激光雷达|点云数据|车载3D感知|智能制造|多模态视觉|前沿科技|人工智能
当你坐在自动驾驶测试车里,窗外的行人和车辆正被激光雷达转化为百万级的点云数据——这堆由三维坐标组成的“点群”,是汽车判断路况的核心依据。但你可能不知道,能精准识别这些点云的AI模型,大到根本装不进普通车载电脑。直到最近,长安大学和西安交大的团队拿出了一套反常识的方案:把大模型的“体重”砍掉5.2倍,识别精度反而还涨了0.55%。更狠的是,另一组研究者解决了点云配准的行业绝症——哪怕99.9%的数据都是噪声,他们的算法照样能精准对齐三维场景。这不是实验室里的玄学,而是能直接落地的车载感知革命。
你可以把三维目标检测模型想象成一个米其林三星厨师——能做出极致精准的“菜品”(识别三维目标),但厨房要占半层楼,还得配十几个助手(海量计算资源)。而车载电脑就像小区楼下的便民厨房,空间小、火力弱,根本容不下这位大厨。
传统的模型压缩思路,就像是让大厨用小锅炒菜,味道难免打折。惠飞教授团队提出的CLEAN框架,换了个思路:先让大厨把自己的“做菜秘方”(两阶段检测模型的知识)全教给一个学徒(单阶段轻量模型),而且不是只教菜谱,连“放半勺盐”这种隐性经验都传过去——这就是异构知识蒸馏,突破了只能在同类模型间传知识的局限。
紧接着,团队还要给学徒做“精准抽脂”:不是随便切肉,而是盯着那些和目标类别相关的“肌肉”(关键特征通道),只切掉没用的脂肪。最后再加一道“过滤工序”,把学徒炒出来的重复菜品(冗余假阳性预测)去掉。
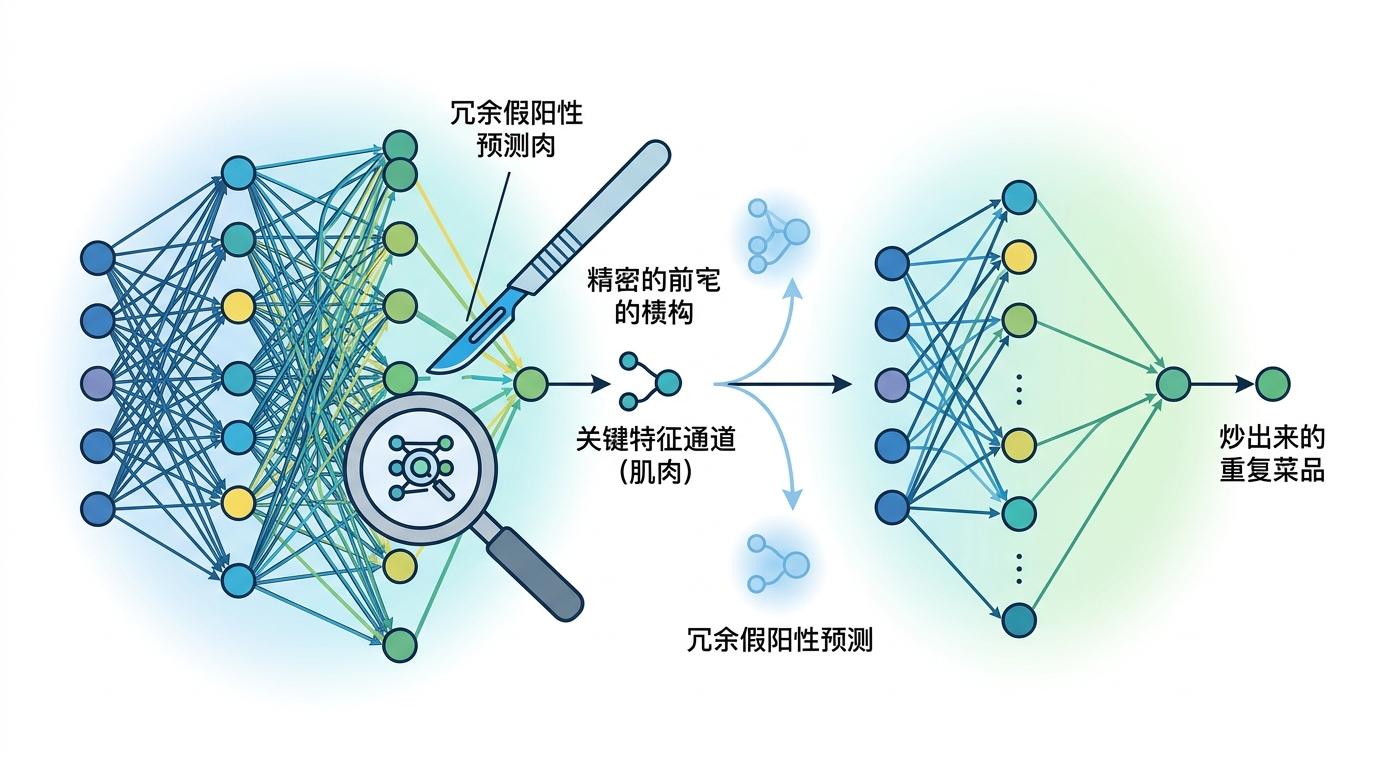
在Waymo的迷你数据集上,这套方法把常用的CenterPoint模型参数量砍到原来的1/5.2,精度反而还涨了0.55%。相当于让一个街边小吃摊,做出了米其林级别的味道,还比大厨出菜快三倍。
如果说三维目标检测是“认出眼前的车”,那点云配准就是“把前后两秒看到的街景拼成一张图”——这是自动驾驶建图和定位的核心。但现实中,激光雷达扫到的点云里,可能混着路边的落叶、飞过的鸟、甚至其他车的反射光,这些都属于“外点”(噪声)。极端情况下,外点能占到99.9%,就像在一万粒沙子里找一颗特定的珍珠。
传统方法要么像筛沙子一样慢慢找,要么依赖复杂的约束规则,计算量大到车载电脑根本扛不住。权思文副教授团队的SVOS方法,相当于给每粒沙子装了个投票器:先让每个候选点(珍珠候选人)自己投一票,然后让周围的点跟着投票,最后得票最高的就是真珍珠。
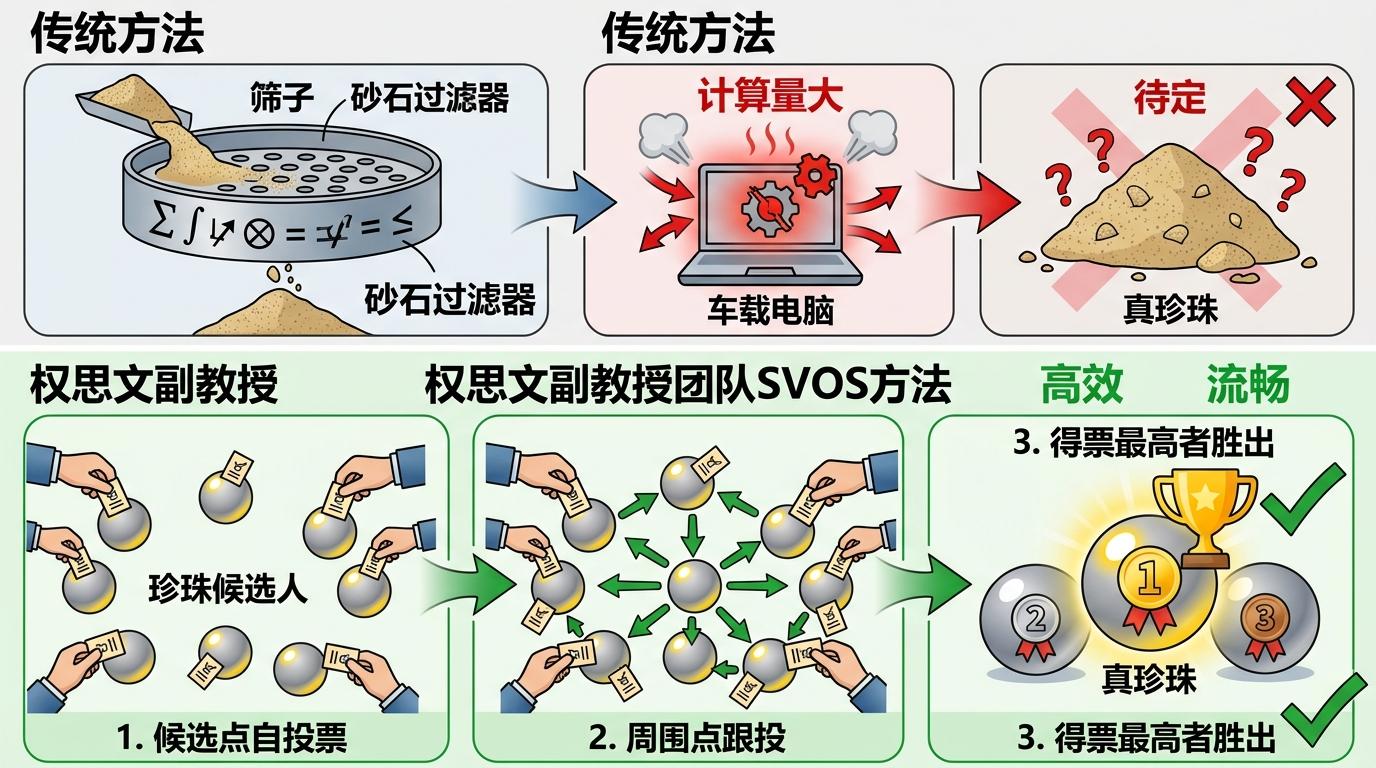
这个机制的聪明之处在于,它只用最简单的“邻居关系”(低阶图约束),不用搞复杂的全局规则——就像找熟人不用查整个城市的户籍,只要问他邻居认不认识就行。在3DMatch等标准数据集上,这套方法在配准精度和速度上都超过了现有最好的方案,哪怕99.9%都是噪声,也能精准找到那粒珍珠。
更重要的是,它的计算量极小,完全能在车载芯片上实时运行——相当于用计算器的算力,完成了超级计算机的活。
这两项技术的核心,其实都是同一个逻辑:在资源受限的环境里,不是简单给模型“瘦身”,而是把每一份计算资源都用在刀刃上。
过去大家觉得,要让AI在小设备上跑,就得牺牲精度——就像手机拍的照片肯定不如单反。但CLEAN和SVOS打破了这个惯性思维:CLEAN通过知识蒸馏,让小模型拥有大模型的“智慧”;SVOS通过投票机制,让简单算法拥有复杂算法的“判断力”。
当然,它们也不是万能的。CLEAN目前只针对点云检测模型,还没法直接用到多模态融合的系统里;SVOS在处理完全无重叠的点云时,性能还是会打折扣。但这些局限,恰恰是下一步的方向:比如把类别知识蒸馏用到多模态模型,或者给SVOS加个“预判断重叠度”的模块。
更值得注意的是,这两项研究都来自国内高校团队,而且都已经在顶级期刊TPAMI上发表——这意味着中国在车载三维感知的算法层面,已经走到了世界第一梯队。
当我们谈论自动驾驶时,总喜欢盯着激光雷达的分辨率、芯片的算力参数,却常常忽略:真正能让技术落地的,是那些在“资源受限”这个紧箍咒下的创新。就像在狭小的厨房里做出满汉全席,才是真正的厨艺巅峰。
CLEAN和SVOS的意义,不止是让车载感知更高效,更在于它们重新定义了“高效AI”的标准:不是用更多资源做更多事,而是用更少资源做对的事。未来的自动驾驶,不会是堆出来的“豪华配置”,而是像一个经验丰富的老司机,用最少的注意力,做出最精准的判断。
有限资源里,藏着真正的智能。