对抗知识焦虑,从看懂这条开始
App 下载
AI看懂图片的秘密,藏在这层看不见的空间里
高维特征点|文本编码器|视觉编码器|共享嵌入空间|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载高维特征点|文本编码器|视觉编码器|共享嵌入空间|多模态视觉|人工智能
你或许见过AI认出灵隐寺墙角的草书,或是识破那张像有人坐在椅子上的视觉陷阱——这些不再是简单的“看图说话”,而是AI跨模态推理的结果:它能把图像里的砖墙、山脉、草书,和文本世界里的“灵隐寺”“燕山山脉”“北京昌平”精准对接。这背后的核心,是一个看不见的“共享嵌入空间”。
多模态模型的本质,是把不同感官的信息翻译成同一种“语言”。视觉编码器先把图像拆成一个个高维特征点——比如灵隐寺飞檐的弧度、路灯草书的笔触,再把这些特征点映射到一个统一的高维空间里;同时,文本编码器也把“灵隐寺”“经纬度30.21°N,120.10°E”这些文字,转换成同一空间里的特征点。当两个模态的特征点在空间里靠得足够近,AI就完成了“图像”与“文本”的语义对齐。
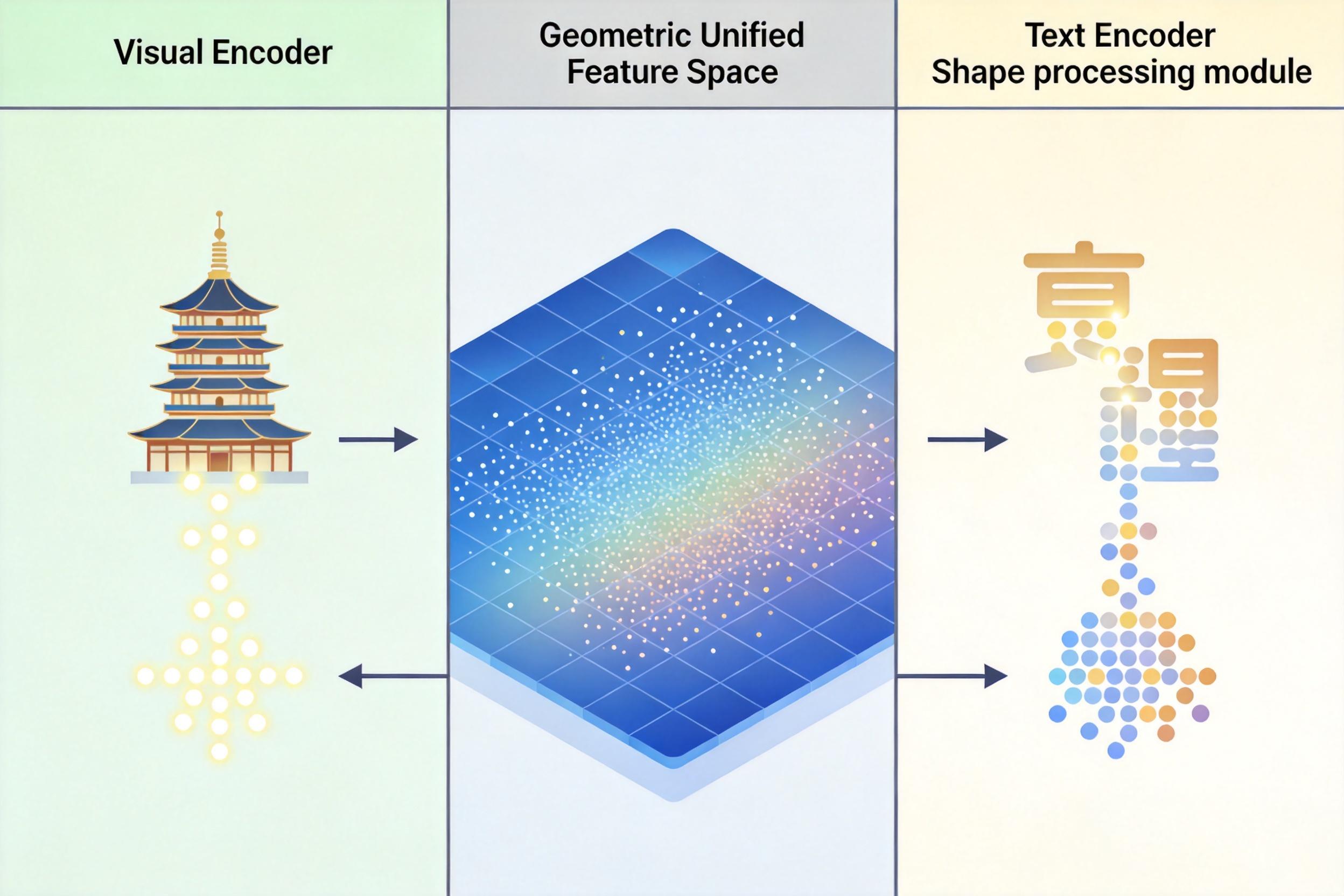
跨模态注意力机制则是这个空间里的“导航系统”。面对那张没有文字的北京郊区照片,AI会先扫描图像里的所有特征:灰砖民居的坡度、远处山脉的走向、路边槐树的形态,然后在共享空间里,把这些特征点和“燕山山脉”“北京昌平民居”的文本特征点一一比对,像侦探拼接证据链一样,推导出拍摄地点的范围。这个过程不是一次性完成的,而是通过链式思考一步步拆解:先识别建筑风格,再匹配山脉特征,最后缩小地理范围,和人类推理的逻辑几乎一致。
但这台“推理机器”也有自己的阿喀琉斯之踵。它可能会把左手的手相看成右手,也可能在数据不足时生成虚假信息——这就是多模态模型的“幻觉”问题。更棘手的是,共享空间里的“模态间隙”始终存在:图像和文本的特征点始终是两个相对独立的集群,就像说两种方言的人凑在一起,偶尔还是会有沟通误差。比如面对模糊的草书,AI可能会把“灵隐寺”误判成“灵隐祠”,因为这两个词在文本空间里的特征点距离很近。
这些挑战并没有阻碍技术的落地。在医疗领域,多模态模型已经能把CT影像和病历文本融合,辅助医生诊断阿尔茨海默症,准确率比单一模态模型提升近20%;在自动驾驶领域,它能同时处理摄像头、雷达和激光雷达的数据,在暴雨天识别被积水遮挡的路标。这些应用的核心,都是让AI像人类一样,用多种感官信息拼凑出完整的世界。
未来十年,我们或许会看到更“聪明”的多模态推理:AI不仅能识别图像,还能主动关联背后的知识——比如看到灵隐寺的飞檐,就能联想到吴越国的建筑规制;看到兔子的垂耳,就能解释这种性状的遗传逻辑。而那个看不见的共享嵌入空间,会变得越来越拥挤,越来越精细,最终成为AI理解这个复杂世界的核心枢纽。毕竟,人类对世界的认知,从来都不是单一感官的产物,AI也一样。