对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶大模型减负:剪90%数据还更安全
视觉数据处理|时空剪枝机制|中科院团队|ST-Prune|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视觉数据处理|时空剪枝机制|中科院团队|ST-Prune|自动驾驶|人工智能
想象一下:一辆自动驾驶汽车顶着6个摄像头,每秒要处理上万个视觉数据块——相当于同时读几十页密密麻麻的图片“文字”,还要实时判断要不要刹车、变道。这堆数据里,90%都是重复的马路、不变的楼房,真正关键的突然窜出的行人、变红的信号灯,反而可能被淹没在数据洪水里。2026年4月,中科院团队拿出了一个像给电脑装了智能垃圾清理插件的方案:不用重新训练模型,直接砍掉90%冗余数据,还能让系统对危险的反应更精准。这就是ST-Prune,一个专门给自动驾驶大模型“减负”的时空剪枝机制。
过去给自动驾驶大模型剪数据,就像闭着眼睛扔东西——不管是关键的行人还是重复的背景,全混在一起按统一规则删,结果常常是把救命的信息扔了,留了一堆没用的马路。ST-Prune的聪明之处,在于它读懂了自动驾驶场景的“专属冗余”:时间上,连续几帧里只有移动的物体才重要;空间上,6个环视摄像头拍的画面有大量重叠,同一个天桥可能被拍3次。
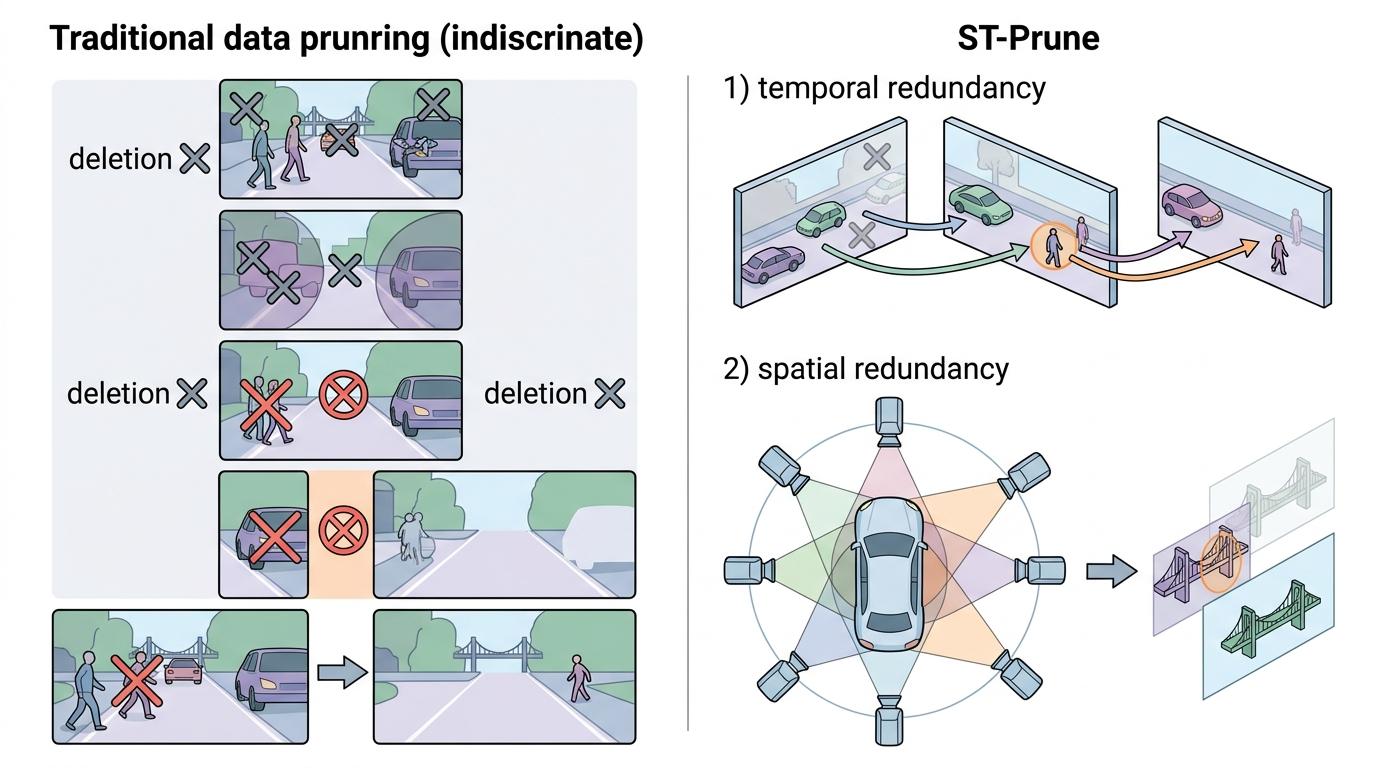
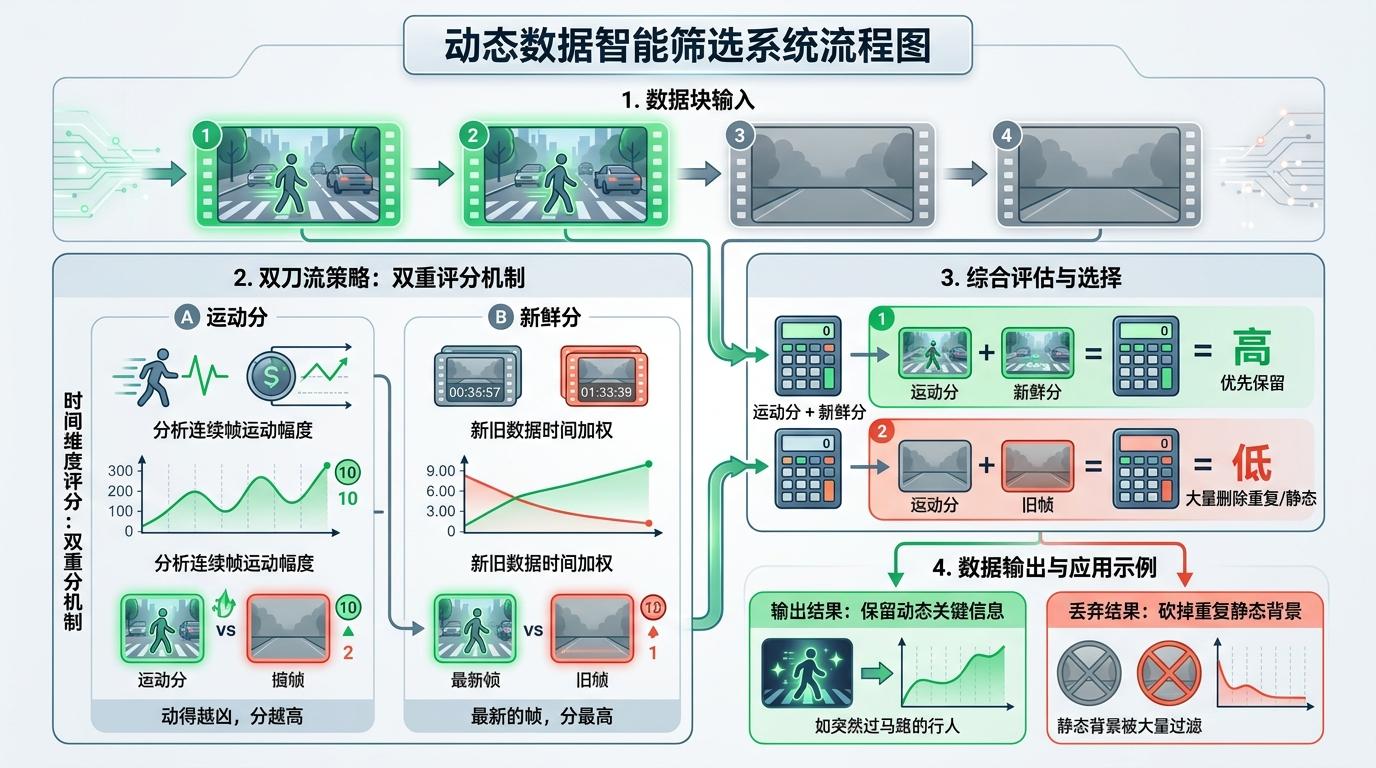
它用了一套“双刀流”策略:先在时间维度“挑动态”——给每个数据块算两个分,一个是“运动分”,看这个块在连续帧里动得有多厉害,动得越凶分越高;另一个是“新鲜分”,最新的帧数据分最高。两个分加起来,优先保留动得多、刚出现的信息,比如突然过马路的行人,直接把重复的静态背景全砍掉。
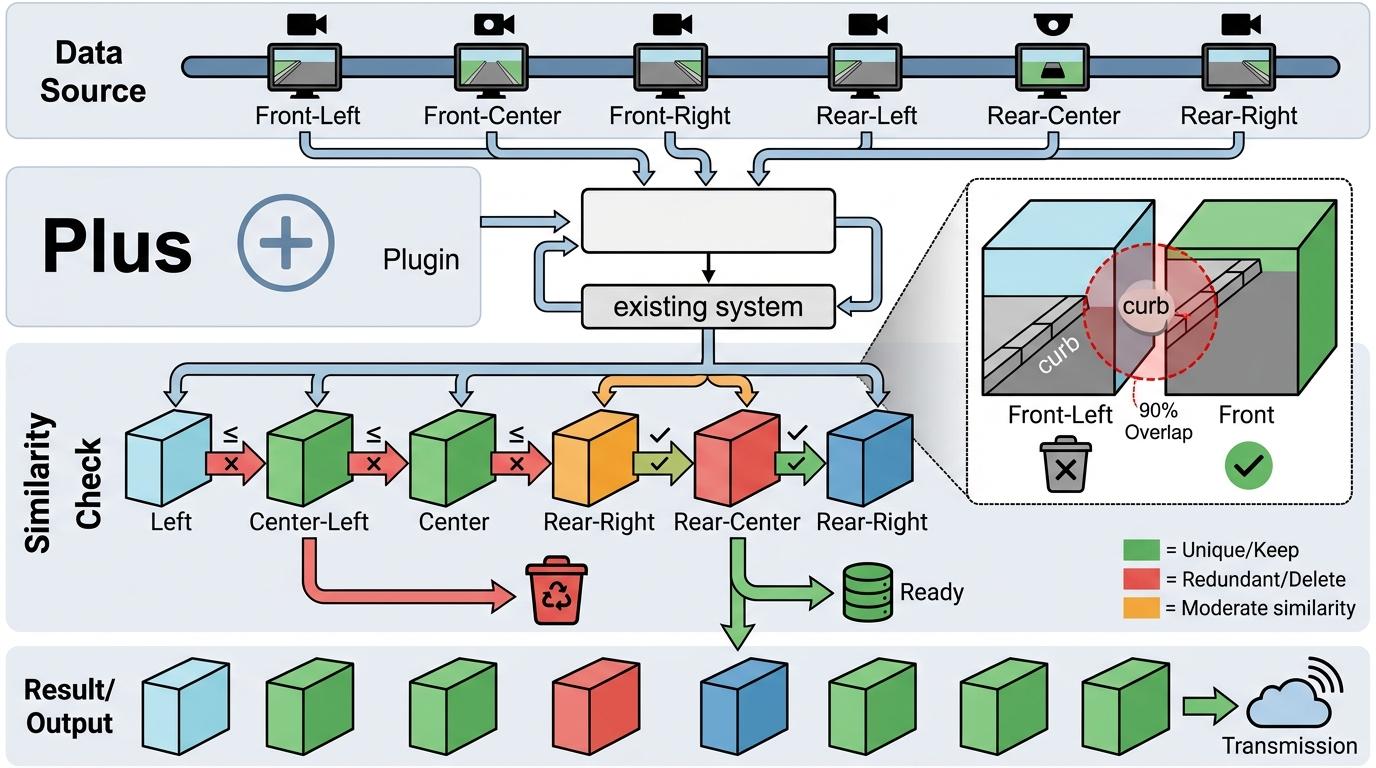
接着在空间维度“去重复”——利用6个摄像头的物理排列顺序,每个数据块只和左右相邻摄像头的比相似度,相似度越高说明越冗余,就优先删掉。比如前左摄像头拍的马路牙子,在前摄像头里也有几乎一样的,就只留一份。整个过程不用重新训练模型,像个插件一样直接插在现有系统上,即插即用。
中科院团队在四个主流自动驾驶测试基准上验证了ST-Prune的实力:当只保留25%的数据时,模型性能只比用全量数据时低0.28分,远甩其他剪枝方法几条街;就算只留10%的数据——相当于砍掉90%的冗余,ST-Prune的表现依然比其他方法用25%数据时还好。
在NuInstruct测试里,其他方法砍到10%数据时,误差直接飙到10以上,而ST-Prune的误差反而从3.50降到了3.49,相当于删了数据还变准了。这是因为它精准地删掉了干扰信息,让模型能更聚焦关键内容。效率上也实打实:保留10%数据时,推理速度提升了1.5到1.8倍,车载芯片的算力压力直接减轻大半。
更难得的是,这套方法对超参数不敏感——不用反复调试复杂的参数,随便调调就能拿到不错的结果,工程师不用花几个月去适配。而且它的额外计算量极小,几乎不增加系统负担,完全符合车载设备对低延迟、高稳定的要求。
不过ST-Prune也不是完美的。它的空间剪枝模块依赖多摄像头的排列结构,要是换成单摄像头的场景,这部分就派不上用场。而且目前它的剪枝比例还是固定的,没法根据实时路况动态调整——比如在空旷的高速上可以多删点,在拥挤的市区就少删点。
未来的剪枝技术,得学会“随机应变”:比如根据实时路况自动调剪枝比例,在单摄像头场景下也能精准识别冗余;还要能适配更多不同结构的大模型,而不是只针对某几种。另外,现在的测试大多在实验室里,真正放到真实的车载芯片上,延迟、功耗表现还得再打个问号——毕竟实验室的算力和车载设备的算力,差的可不是一星半点。
更值得关注的是,ST-Prune的思路给自动驾驶算力优化指了一条新方向:与其一味追求更大的模型、更强的芯片,不如先把现有数据里的“水分”挤干。毕竟,对自动驾驶来说,不是数据越多越好,而是有用的数据越多越好。
当我们还在惊叹大模型的参数从百亿涨到千亿时,中科院团队用ST-Prune证明:有时候,做减法比做加法更重要。自动驾驶的终极目标从来不是处理海量数据,而是在正确的时间做出正确的决策——砍掉冗余,留下关键,才是通向安全高效的捷径。
算力瓶颈从来不是靠堆芯片就能解决的,真正的突破,藏在对场景的精准理解里。少即是多,精准胜过海量,这不仅是ST-Prune的核心逻辑,也是自动驾驶技术落地的必经之路。