对抗知识焦虑,从看懂这条开始
App 下载
AI把蛋白质研发周期从年缩到了周
酶筛选|蛋白数据库|上海交大团队|自动化实验室|蛋白质设计|合成生物学|AIGC|生命科学|人工智能
对抗知识焦虑,从看懂这条开始
App 下载酶筛选|蛋白数据库|上海交大团队|自动化实验室|蛋白质设计|合成生物学|AIGC|生命科学|人工智能
想象一下:你需要一个能在胃酸里稳定工作的酶,或是能精准绑定癌细胞的蛋白,以前得在实验室里试上几年,做上万次实验,运气好才能碰对方向。现在,只要对着AI说清需求,它就能在百亿级的蛋白数据库里筛出候选序列,再把设计方案直接传给自动化实验室,几天内就能拿到验证结果——甚至还能根据实验数据自动优化下一轮设计。这不是科幻,是上海交大团队打造的AI蛋白研发闭环已经做到的事。为什么这个闭环能把研发效率提上百倍?它到底改变了生物制造的什么规则?
蛋白质是生物世界的「功能芯片」,但它的设计难度远超人类制造的任何芯片——一个由100个氨基酸组成的蛋白,理论上有10^130种序列组合,比宇宙中的原子总数还多。传统的蛋白研发只能在自然进化的「存量」里微调,或是靠随机突变碰运气,就像在大海里捞一根针。

而AI的出现,把这根「针」的位置直接指给了科学家。以上海交大团队的平台为例,他们先攒下了近100亿条蛋白序列的「超级数据库」,每条序列都带着温度、pH值等65亿个环境标签——相当于给每根「针」都标上了它能在什么环境里干活。再用这些数据训练出AI大模型,它能像读懂语言一样读懂蛋白序列,直接根据产业需求设计出符合要求的蛋白:比如要更耐热的甜味蛋白,或是能穿透细胞膜的药物载体。
你可以把这个过程类比成「定制菜谱」:数据库是全球所有食材的档案,AI是能根据你的口味和食材特性直接出菜谱的厨师,而不是让你自己在菜市场里瞎逛。
光靠AI设计还不够——毕竟电脑里的蛋白再完美,也得在现实的试管里验证。以前这是两道完全割裂的工序:AI团队出设计,实验团队做验证,中间要靠人工对接,数据反馈慢则几周,快则几天,一轮迭代下来就是半个月。
现在的「对话式干湿闭环」,把这两道工序拧成了一个高速转动的轮子:AI在云端生成设计方案,直接通过接口传给自动化实验平台,机器人24小时不间断地完成基因合成、蛋白表达、功能测试,实验数据实时传回AI模型,模型立刻根据结果调整参数,生成下一轮更精准的设计。整个过程像两个人在实时对话:AI说「我设计了这个」,实验室答「它在pH3下活性不够」,AI马上回「那我调整这几个氨基酸试试」。
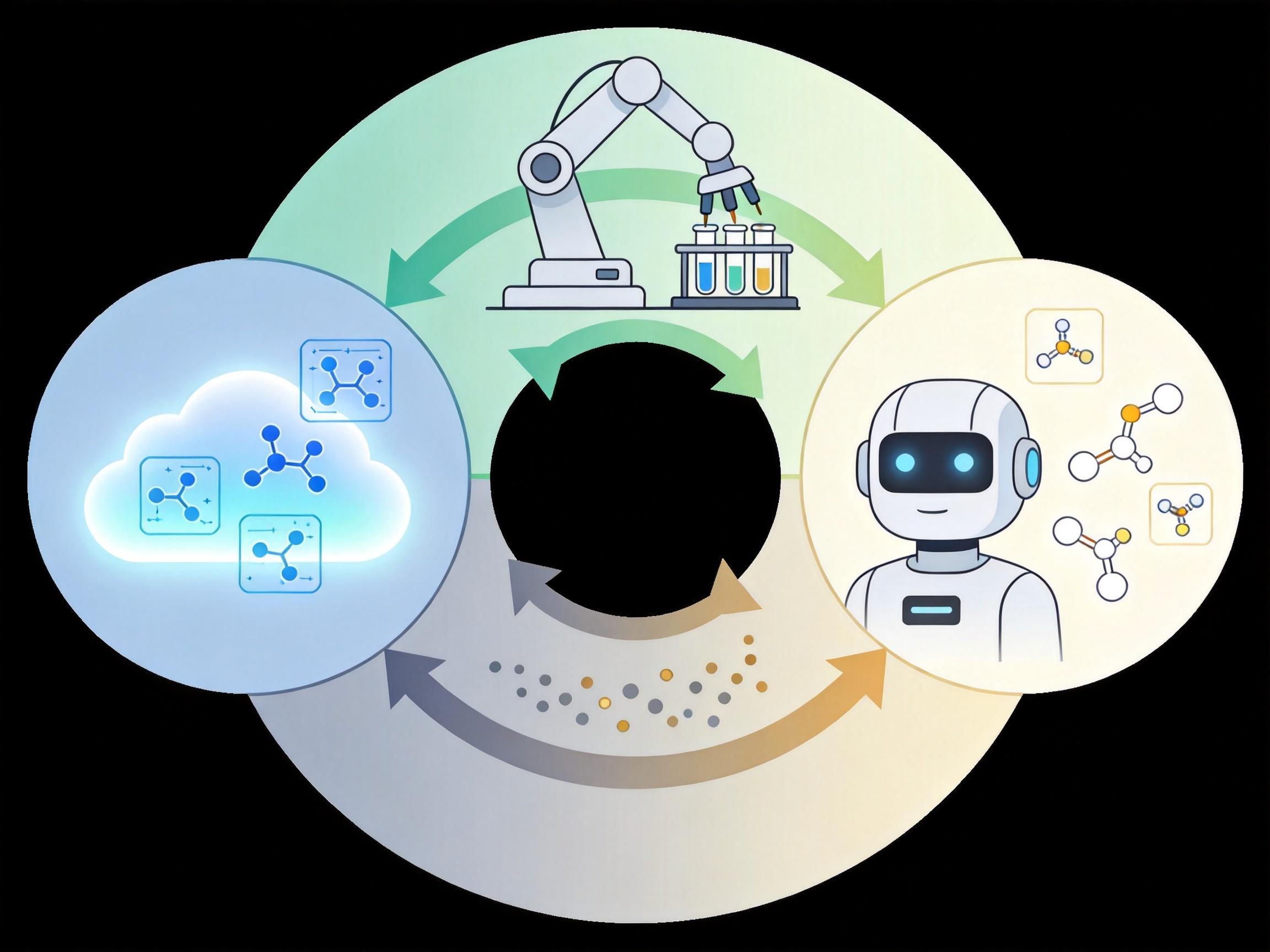
有团队用这套系统优化无细胞蛋白合成,6轮迭代就做了3.6万次实验,把生产成本降了40%,产量提了27%。更关键的是,科学家从以前的「实验操作员」,变成了「需求定义者」——不用再蹲在实验室加样,只需要告诉AI「我要什么」,剩下的交给闭环自己跑。
当然,这套系统也不是万能的:目前它还只能处理相对成熟的蛋白功能需求,对于需要复杂动态构象的蛋白,AI的预测精度还不够;而且自动化实验室的成本不低,中小团队很难复制。
过去,生物制造的逻辑是「先研发,后生产」:在实验室里磨出一个能用的蛋白,再花几年时间优化生产工艺,放大到工厂规模。而AI闭环正在把这个逻辑反过来——「设计即生产」。
因为AI在设计蛋白的时候,就已经把生产条件考虑进去了:比如会不会在发酵罐里容易降解,能不能用低成本的培养基大量表达。甚至有些平台已经能直接对接工厂的生产数据,让AI设计出的蛋白天生就适合工业化生产。这就像你定制家具的时候,直接让设计师按照你家电梯的尺寸来画图纸,不用等做好了再改。
这种范式的转变,正在重构整个生物制造产业:以前创新药的靶点发现要花5-10年,现在用AI闭环可能1-2年就能完成;以前农业里的固氮酶只能靠自然筛选,现在AI能设计出更高效的人工固氮酶,减少化肥使用。但这也带来了新的挑战:比如AI设计的「非天然蛋白」,如何制定统一的安全标准?海量的蛋白数据,如何保证隐私和产权?
当AI能像设计代码一样设计蛋白,当实验室能像工厂流水线一样自动验证,生物制造就不再是少数专家的「黑魔法」,而是能像软件编程一样快速迭代的创新工具。这背后的本质,是人类终于打破了自然进化的「速度限制」——以前自然要花几百万年才能筛选出的功能蛋白,现在我们用AI只要几天。
「设计即生产,验证即迭代。」这不仅是蛋白研发的新规则,更是生命科学走向产业应用的新起点。未来,我们或许能定制出分解塑料的酶,能设计出只杀癌细胞的蛋白,甚至能创造出自然界从未有过的生物功能——而这一切的起点,就是AI和实验室的那一句「对话」。