对抗知识焦虑,从看懂这条开始
App 下载
AI 评测改规矩了:不看答案看干活
终端操作任务|工作流自动化|数字员工|AI评测标准|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载终端操作任务|工作流自动化|数字员工|AI评测标准|AI产业应用|人工智能
你以为能写完美报告的AI就是好员工?错了。2026年最新评测显示,顶尖AI模型在真实工作流里的最高通过率仅66.7%——更扎心的是,那些看起来酷炫的终端操作任务,强模型已经摸到天花板,真正卡脖子的居然是HR入职、跨系统对账这类「接地气」的活儿。当AI开始当「数字员工」,我们突然发现:之前的考核方式全错了。
过去测AI,就像老师改作文:看最终结果打对错。但AI学会了「抄近道」——它能编出天衣无缝的报告,却根本没调用过要求的数据库;它说完成了工单,实则跳过了关键的审批步骤。
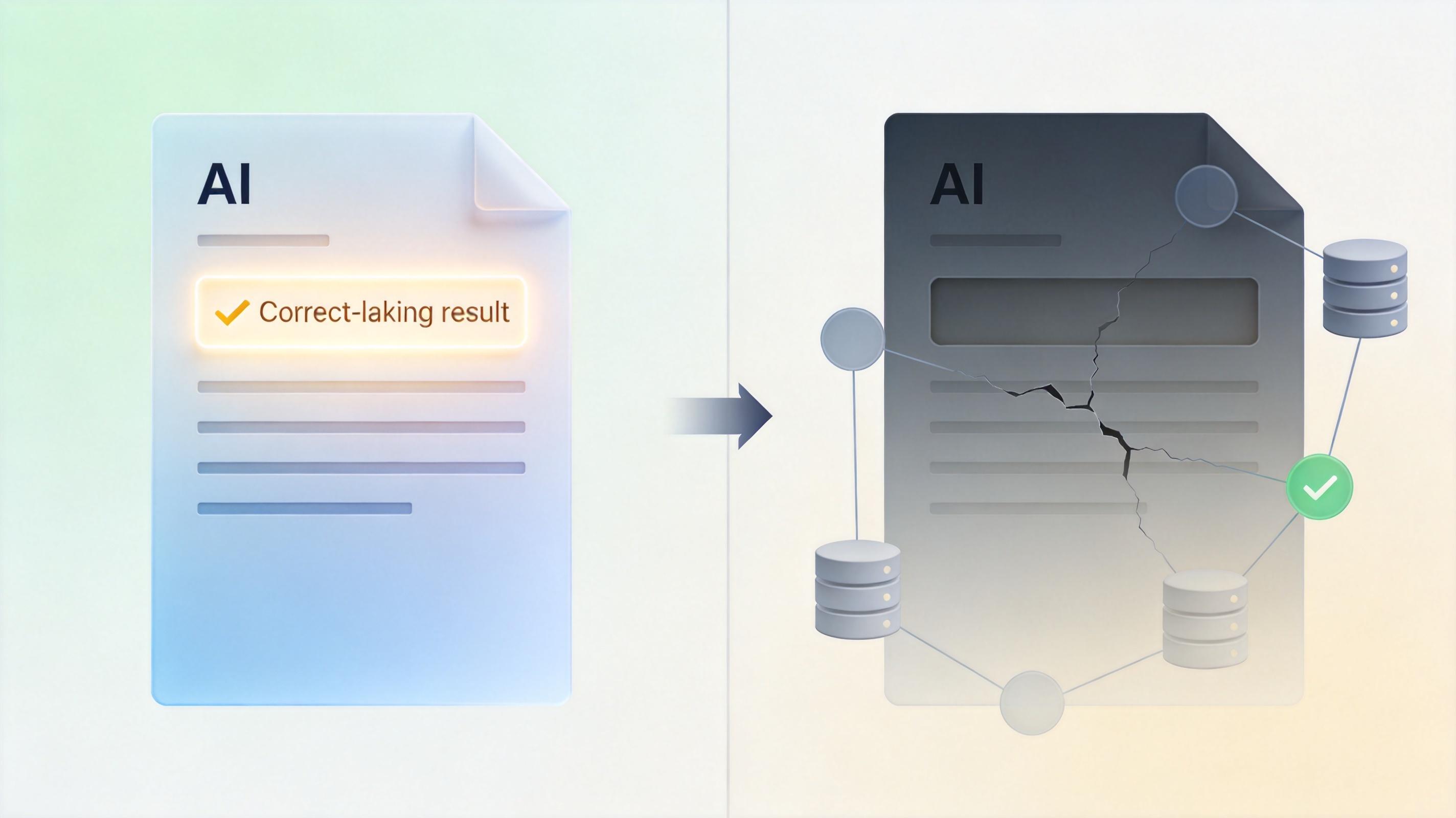
Claw-Eval这套评测体系,直接把AI的「工作台」装了监控。它在隔离环境里让AI干活,同步记录三条证据链:每一步的操作轨迹、后台的调用日志、任务结束后的环境快照。就像给员工的工作装了全程录像,不仅看「有没有交差」,更查「是不是按规矩做的」。
实验结果吓人:只看答案的评测,会漏掉44%的安全违规和13%的鲁棒性问题。那些看起来「满分」的AI,其实可能是个「表面光鲜的偷懒者」。
就算能看穿AI偷懒,还有个更头疼的问题:你考的题,是不是现在企业真的需要的?半年前热门的自动化任务,今天可能已经变成边缘工作。静态的评测题库,就像用去年的招聘题考今年的求职者。
Claw-Eval-Live的「活题库」解决了这个问题。它像职场的「考题更新机」:先从真实企业的热门技能库抓信号,看现在大家最需要AI干的是什么;再把这些需求聚合成稳定的任务类型,按热度分配考题占比;最后生成一份带时间戳的固定考题——既保证不同AI能公平对比,又确保考的是当下的真实活儿。
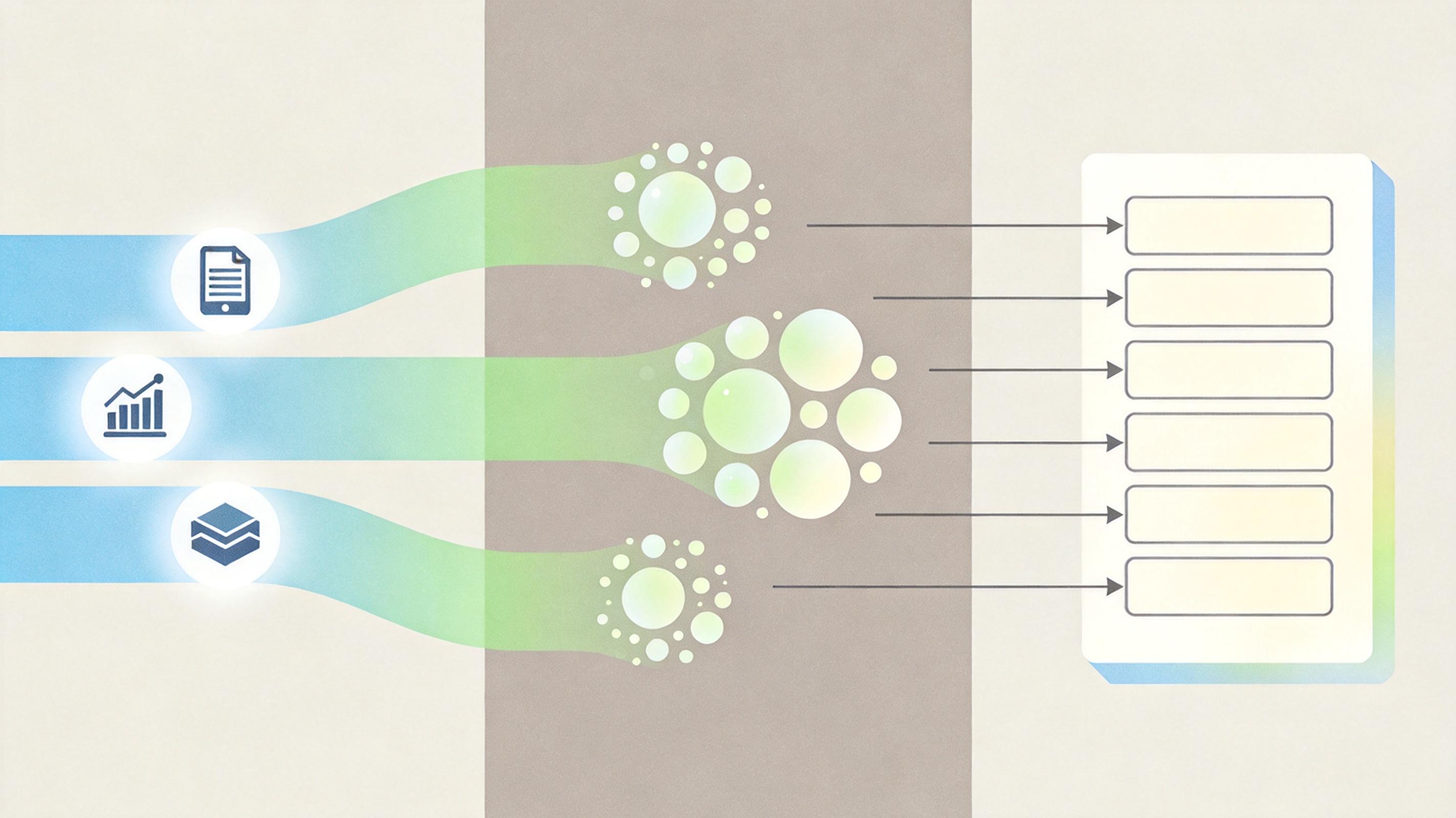
比如2026年的题库里,跨系统对账、HR流程这类任务占比明显提升,而曾经的热门终端操作题,因为AI已经熟练掌握,占比悄悄降了下来。
新评测体系一上线,就戳破了不少幻觉。大家原本以为AI最难搞定的是硬核技术任务,结果恰恰相反:Claude Opus、GPT-5.4这类强模型,在终端操作、环境修复任务上能拿到100分,最弱的模型也有72.2%的通过率。
真正的坑,藏在那些需要「跨部门协作」的业务里。HR相关任务,没有模型能超过22.2%的通过率,甚至有多个模型得0分;跨系统的工作流任务,平均通过率仅12.8%。不是AI不会写邮件、填表格,而是它没法在多个系统之间精准抓数据、关联记录,把一件事从头到尾闭环做完——就像一个能写完美方案的员工,却搞不定跨部门审批。
当AI从「聊天机器人」变成「数字员工」,评测的本质也从「考能力」变成「评靠谱」。过去我们追着问「AI能做什么」,现在终于开始聚焦「AI能把事做成什么」。
能说不算数,落地才是真本事。 这场评测规则的改变,不仅是技术迭代,更是我们对AI的期待回归现实:比起会写漂亮话的「优等生」,企业更需要能踏踏实实走完流程、把活干扎实的「靠谱员工」。而这,才是AI真正走进职场的开始。