对抗知识焦虑,从看懂这条开始
App 下载
让AI玩游戏,竟练出了通用推理能力
游戏数据训练|通用推理基准|Qwen2.5-VL-7B|视觉语言模型|复旦大学团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载游戏数据训练|通用推理基准|Qwen2.5-VL-7B|视觉语言模型|复旦大学团队|多模态视觉|人工智能
你或许见过AI解几何题、分析图表,但你见过AI靠玩数独、推箱子练出通用推理能力吗?2026年3月,复旦大学团队拿出了一份颠覆认知的研究:他们让视觉语言模型——那种能看懂图片又能理解文字的AI——在30款合成游戏里“练级”,结果不仅在游戏任务里表现亮眼,还在7个完全不相关的通用推理基准测试里,把Qwen2.5-VL-7B的成绩平均拉涨了2.33%。更离谱的是,用游戏数据练出来的模型,居然和专门啃几何题的模型表现不相上下。这背后藏着的,是AI训练逻辑的一次悄悄转向。
要让AI玩游戏练推理,首先得有足够多、足够靠谱的游戏题。过去人工标注多模态数据,不仅成本高到离谱,还很难保证逻辑的严谨性——毕竟一道推箱子的正确解法,得一步步对应到视觉画面的变化。
复旦大学团队的解法是Code2Logic:用大语言模型当“出题助手”,把游戏代码直接转换成带推理过程的问答数据。你可以把这个过程想象成:先让AI写出一款数独游戏的运行规则,再让它设计出“从当前盘面出发,下一步该填哪个数字”的问题,最后让游戏代码自动运行验证答案,连带着把“先看第三行缺7,再看第四列已有7,所以只能填在第三行第六格”的推理步骤也生成出来。
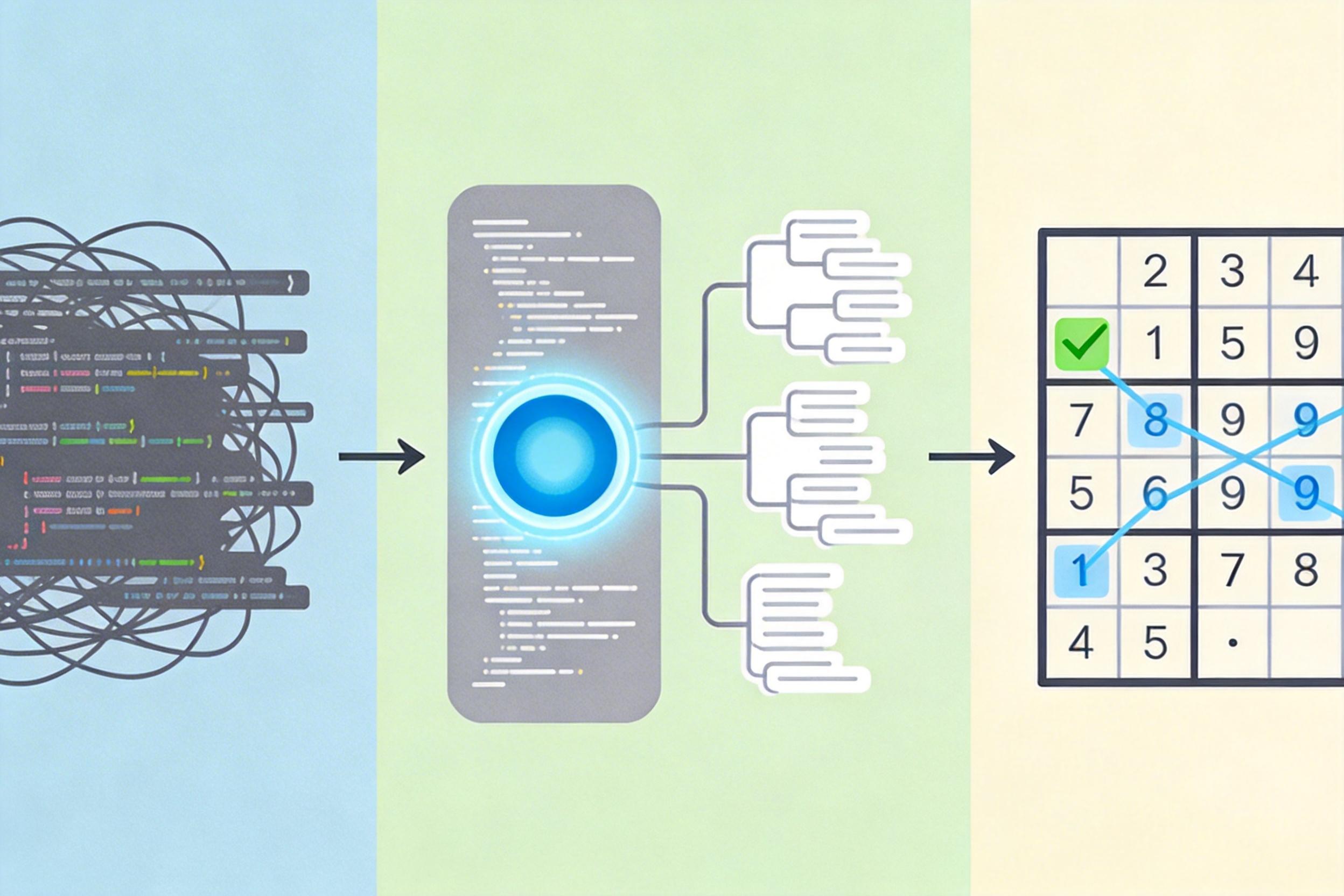
这套逻辑跑起来后,就有了包含14万条问答对的GameQA数据集——30款游戏覆盖3D空间推理、模式识别、多步决策等4类认知能力,还特意留了10款从未在训练中出现的游戏,专门测试AI的泛化能力。更关键的是,整个过程几乎不需要人工干预,成本只有传统标注的几十分之一。
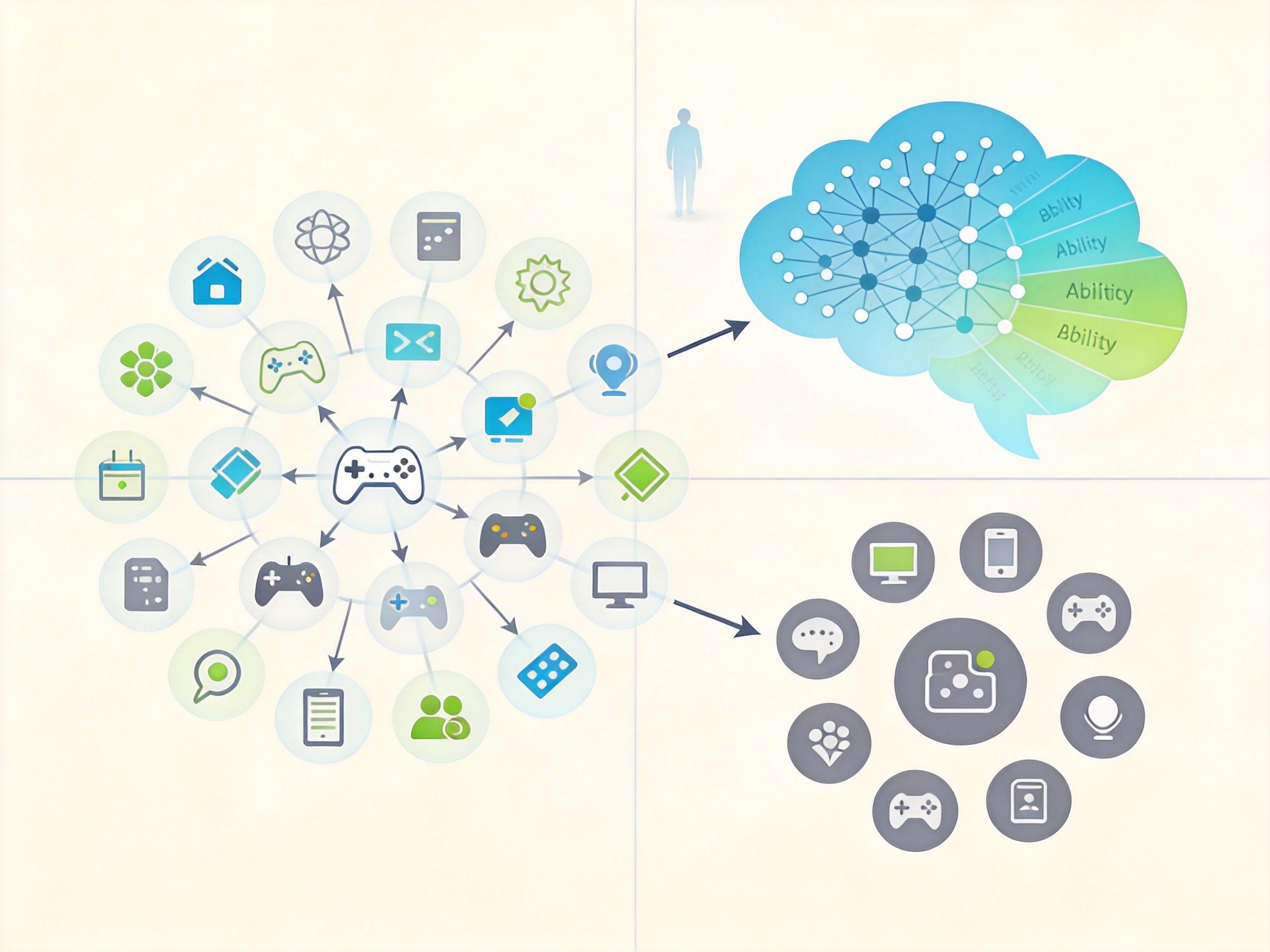
最让人意外的不是AI能玩游戏,而是它在游戏里练出的本事,居然能用到完全不相关的任务上。
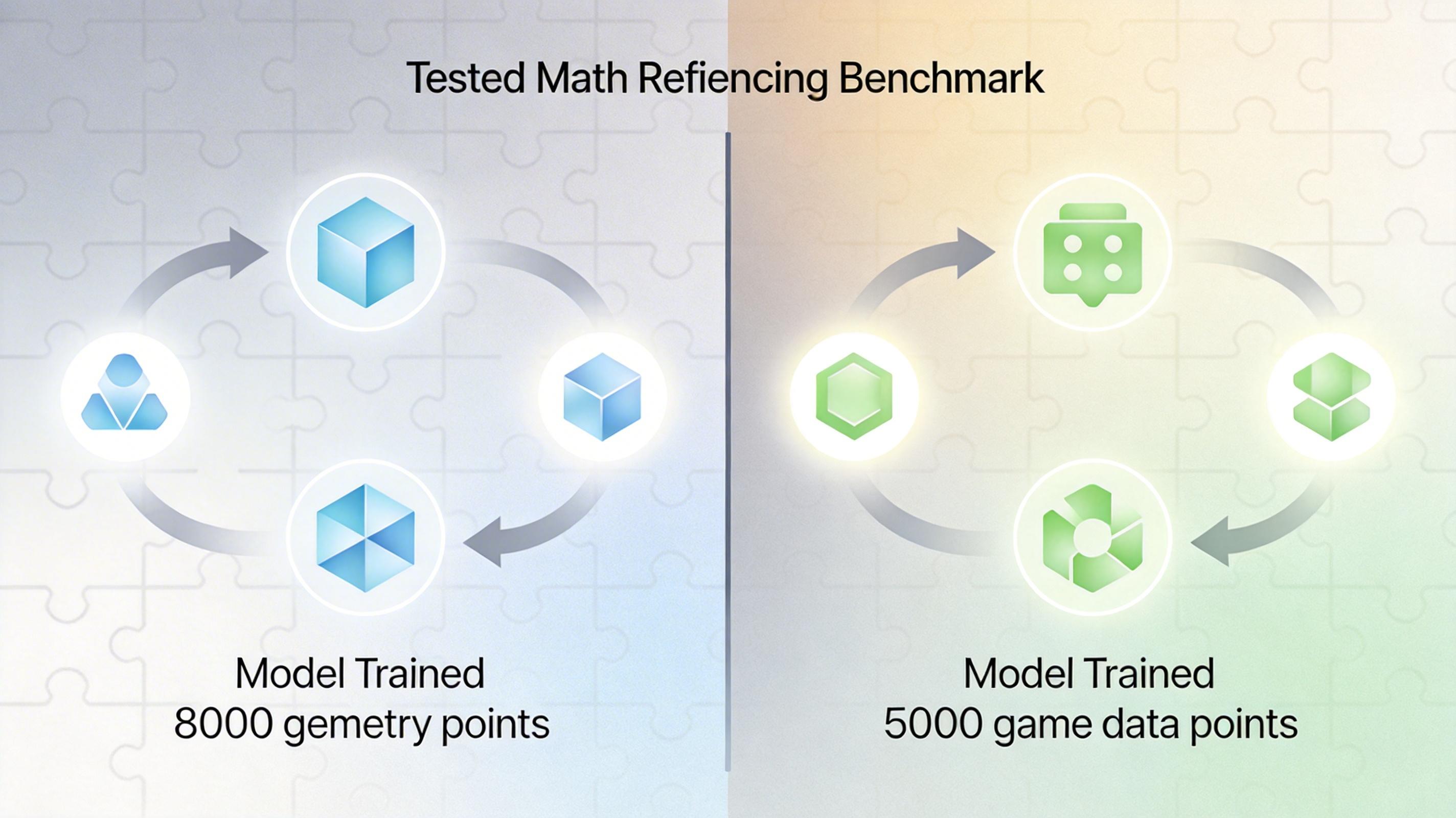
团队用GRPO强化学习算法让模型在GameQA上训练后,拿7个域外通用推理基准测试来验成果:Qwen2.5-VL-7B在每个测试里都拿到了提升,平均涨了2.33%;更夸张的是,用仅5000条游戏数据训练的模型,和用8000条几何题数据训练的模型比,在数学推理基准MathVista上的表现居然不相上下。
人工分析了几百个案例后,他们找到了原因:Game-RL同时补全了AI的两块短板。视觉上,AI能更精准地识别游戏画面里的空间关系——比如推箱子时能分清箱子、墙和目标点的位置;文本推理上,AI能梳理出多步逻辑链——比如七巧板问题里,能一步步推导“先拼三角形,再补四边形”的步骤。这些能力刚好是通用推理的核心,自然能迁移到其他任务里。
还有个更值得琢磨的发现:训练用的游戏种类越多,数据量越大,AI的泛化能力就越强。用20款游戏训练的模型,比只用4款的模型在域外测试里表现好得多;把训练数据从5000条加到20000条,模型的成绩还在持续上涨。
不过,游戏训练不是万能的“AI补品”。
目前GameQA里的游戏都是规则明确、逻辑可验证的,但现实世界里的问题往往模糊复杂——比如一张照片里的“快乐”情绪,没法像数独答案那样用代码验证。团队也承认,现在的模型在处理细粒度视觉信息时还会出错,比如数不清游戏画面里的小物体数量;在超复杂的3D空间推理上,和人类的差距依然明显。
更关键的是,游戏环境和真实世界之间还有一道“鸿沟”:AI在游戏里学的是代码定义的规则,而真实世界的物理规律、社会规则要复杂得多。比如AI能在推箱子游戏里规划最优路径,但让它理解真实世界里“箱子太重推不动”的物理限制,还需要额外的训练。
还有个潜在的风险:如果游戏数据的设计有偏差,AI可能会学到一些“游戏专属技巧”,反而影响在真实任务里的表现。比如有些游戏里的视觉元素有固定规律,AI可能会依赖这些规律答题,而不是真正理解逻辑。
当我们还在纠结AI能不能考过人类的数学题时,复旦大学的研究悄悄指出了另一条路:与其让AI在单一领域死磕,不如让它在更贴近人类认知过程的场景里“玩耍”。毕竟人类的推理能力,也是在玩积木、下跳棋、解决生活里的小问题中慢慢练出来的。
游戏训练的本质,不是让AI变成游戏高手,而是给它提供了一个低成本、高可控的“认知训练场”——在这里,AI能像人类一样,在试错中理解空间、逻辑和因果关系。
游戏不是终点,是AI理解世界的新起点。 未来的AI或许不用再啃枯燥的几何题,而是在更丰富的虚拟互动里,慢慢练出像人类一样的通用推理能力。