对抗知识焦虑,从看懂这条开始
App 下载
AI不止会生成,推理才是破局关键
多模态检索|语义向量|腾讯微信|厦门大学团队|UME-R1框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载多模态检索|语义向量|腾讯微信|厦门大学团队|UME-R1框架|多模态视觉|人工智能
当你用AI搜“猫的图片”,它能一秒找出上万张;但你让它找“一只在追蝴蝶的三花猫,背景是老北京胡同”,它可能只会给你一堆猫的照片——这就是过去多模态AI的局限:只会“识别”,不会“推理”。直到厦门大学团队和腾讯微信联合推出的UME-R1框架出现,它让AI第一次学会了“先想再输出”:先推理用户要的是“三花、追蝴蝶、胡同”三个要素的组合,再生成精准的语义向量。在覆盖78项任务的测试中,它把多模态检索的准确率拉到了新高度。但更重要的是,它撕开了一道口子:AI的下一个里程碑,从来都不是生成更多内容,而是学会像人一样思考。
你可以把AI的“嵌入”理解成给万物贴标签:过去的判别式嵌入是给猫贴“猫”“动物”“可爱”这类标签,AI只能靠对比标签相似度来匹配内容——就像你在图书馆按书名找书,永远找不到内容相关的另一本。而UME-R1的生成式嵌入,是让AI先写一段关于这只猫的“推理笔记”:“这是一只三花猫,它在追蝴蝶,背景是灰瓦胡同,属于老北京生活场景”,再把这段笔记压缩成向量。
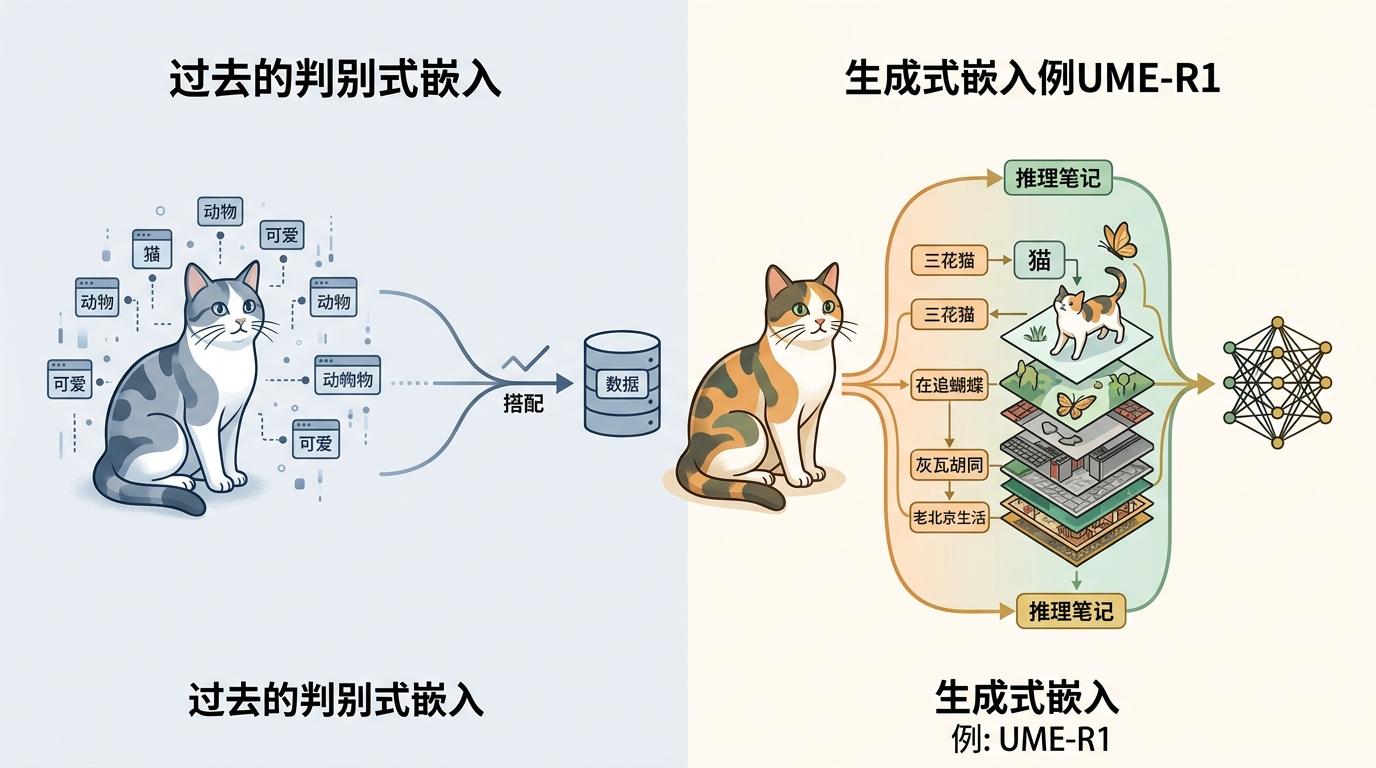
这个过程分成两步:先用监督微调让AI学会写“推理笔记”,再用强化学习给笔记打分——如果生成的向量能精准匹配用户需求,就给高分,反之就扣分。测试数据显示,这种“先推理再嵌入”的方式,比传统方法在视觉文档任务上性能提升了11.1分,相当于把检索准确率从80%拉到了91%。
更关键的是,判别式和生成式嵌入可以互补:简单任务用判别式快速匹配,复杂任务用生成式深度推理。就像图书馆既有按书名检索的机器,也有能帮你找同类内容的馆员。
当AI开始“思考”,新的问题又来了:思考的步骤越多,占用的内存和计算资源就越大——就像你算一道复杂数学题,草稿纸写得越多,翻找起来越慢。过去AI做长链推理时,要把所有思考步骤都存在内存里,计算复杂度是序列长度的平方,这意味着推理1000步的时间是推理100步的100倍。
厦门大学团队的另一个研究给出了答案:用“状态转移推理框架”把思考过程压缩成一个“状态向量”。你可以把它理解成AI的“思考摘要”:每一步思考后,AI会把关键信息提炼成一个向量,而不是存下所有草稿。再配合线性注意力机制,AI不用再盯着所有历史思考步骤,只需要看这个“摘要”就能继续推理,计算复杂度直接从平方降到了线性。
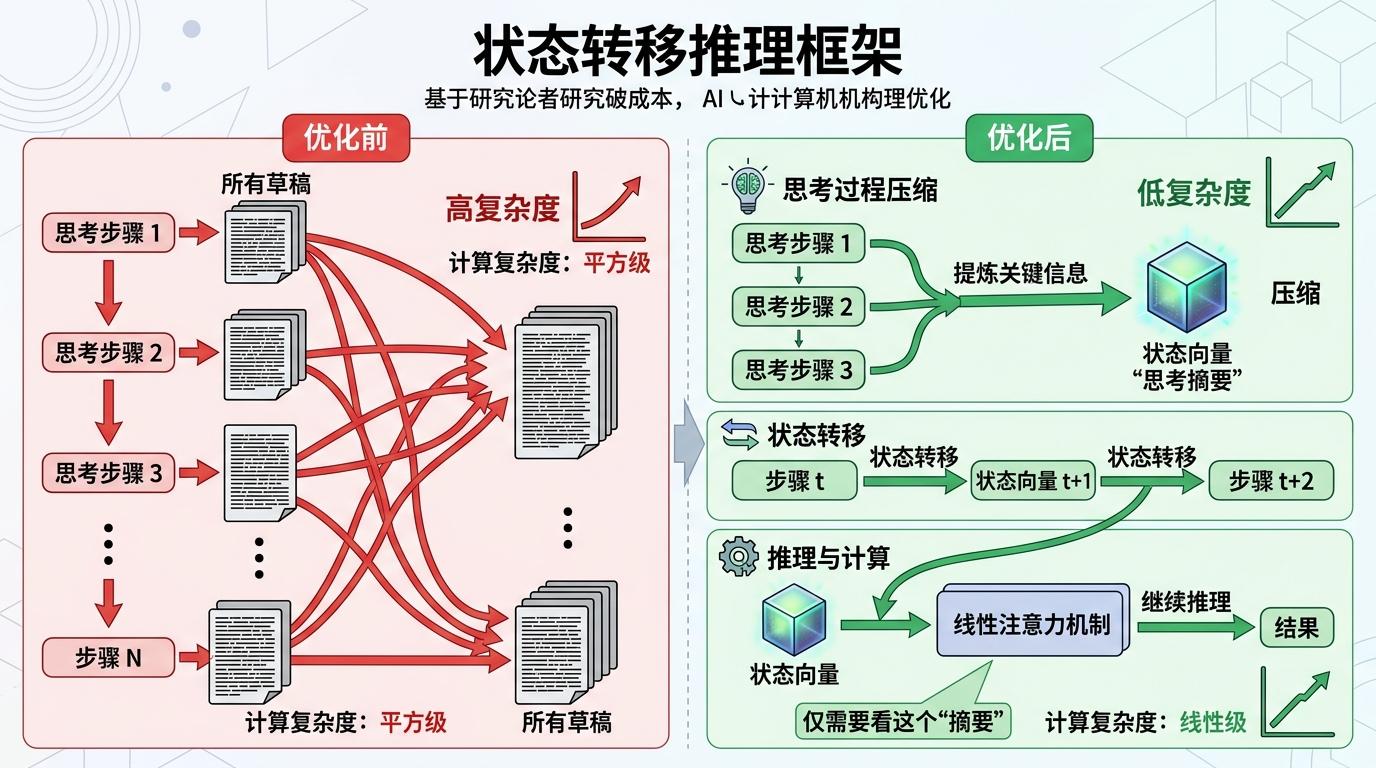
在数学、科学、代码等推理任务中,这个框架让推理速度提升了至少3倍,同时还能减少“无效思考”的干扰——就像你带着摘要开会,不会被无关的闲聊打断思路。不过这种方法也有局限:如果“摘要”提炼得不准,可能会漏掉关键信息,目前还需要更精准的状态压缩算法。
这些技术看起来美好,但要走进现实,还得跨过几道坎。首先是成本:训练UME-R1这样的模型,需要海量的标注数据——光是生成“推理笔记”,就用了146万对样本,这对中小企业来说几乎是天文数字。其次是可解释性:虽然生成式嵌入能给出推理过程,但这个过程依然是“黑箱”里的计算,人类很难知道AI为什么会这么想,一旦出错,根本没法排查。
不过已经有了落地的尝试:亚马逊的Nova多模态嵌入系统,用类似的技术管理游戏广告素材,能精准匹配“角色被手指捏走”这种复杂需求,召回成功率达96.7%;Shopee的MRSE检索系统,靠多模态嵌入提升了18.9%的商品匹配度,直接带动了3.7%的核心指标增长。这些案例证明,只要把技术聚焦在特定场景,就能快速看到价值——毕竟,企业不需要AI会所有思考,只需要它能解决自己的具体问题。
过去我们总说AI像“鹦鹉学舌”,只会模仿人类的内容;现在我们发现,AI更像一个刚学会思考的孩子,虽然还会出错,但已经能自己推导逻辑了。UME-R1和状态转移框架的意义,从来都不是提升了几个百分点的准确率,而是让我们看到了AI的另一种可能:它可以不只是内容的生产者,更是逻辑的构建者。
推理驱动生成,生成反哺推理——这就是AI向智慧跃迁的核心逻辑。未来的AI,或许不会再给你一堆无关的图片,而是会先问一句:“你要的是三花猫追蝴蝶的胡同场景吗?我帮你找最匹配的。”