对抗知识焦虑,从看懂这条开始
App 下载
AI能“答”音频题,却可能没真“听”
听力体检|蚂蚁集团|香港中文大学|静音输入测试|音频-语言大模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载听力体检|蚂蚁集团|香港中文大学|静音输入测试|音频-语言大模型|多模态视觉|人工智能
给AI放一段静音,再问它音频里的内容——你猜它能答对多少?香港中文大学与蚂蚁集团的团队做了测试:主流音频-语言大模型在静音输入下,居然能在权威测试集里拿到最高58.4%的准确率,是随机猜测准确率的两倍还多。这不是AI的超能力,而是它在“投机取巧”:靠着题目里的文本线索、训练时记住的概率分布,不用听音频就能蒙对答案。这种“聋而知晓”的假象,成了AI真正听懂声音的最大障碍——直到他们找到一把精准的“过滤器”。
你可以把AI的音频理解训练,想象成给学生做听力题——如果卷子上的题目光看选项就能猜答案,练再多也练不出真听力。过去的音频训练数据里,就混着大量这种“伪听力题”:有的题目文本里藏着明显线索,比如“以下哪种动物会喵喵叫”;有的是AI在训练时记住了“猫叫是最常见的动物音频”,不用听也会选猫。
团队先做的第一件事,是用57万道题搭建了一个严格的“听力题库”AudioMCQ。他们给每道题做了一次“静音测试”:用三个不同的主流AI模型,在只给静音音频的情况下答题,如果至少两个模型能答对,就标记为“弱音频贡献题”——也就是靠蒙就能对的题;反之则是“强音频贡献题”——必须真听才能答对的题。最终的结果有点惊人:54.8%的题都是“伪听力题”。
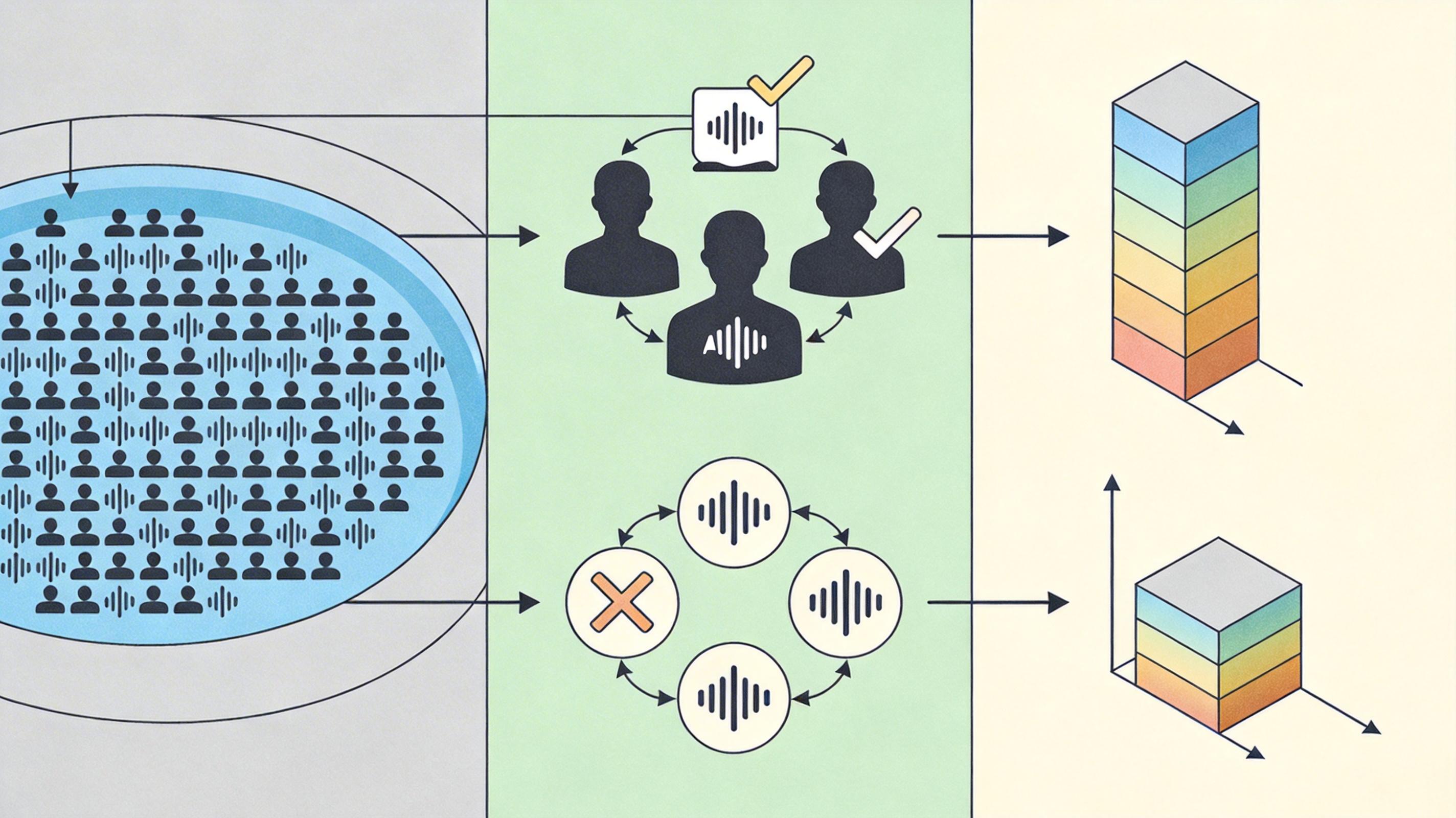
传统的AI后训练,要么把所有数据混在一起微调,要么先监督微调再强化学习,但效果总是不稳定——有时甚至越练越依赖文本捷径。团队的破局点,是把“弱贡献题”和“强贡献题”用在了不同的训练阶段:
第一种是“弱到强”范式:先用弱贡献题做监督微调,让AI先把文本逻辑和基础对应关系练扎实;再用强贡献题做GRPO强化学习——这种强化学习会给“真听音频答对”的答案更高奖励,逼AI放弃捷径,专注从音频里找信息。
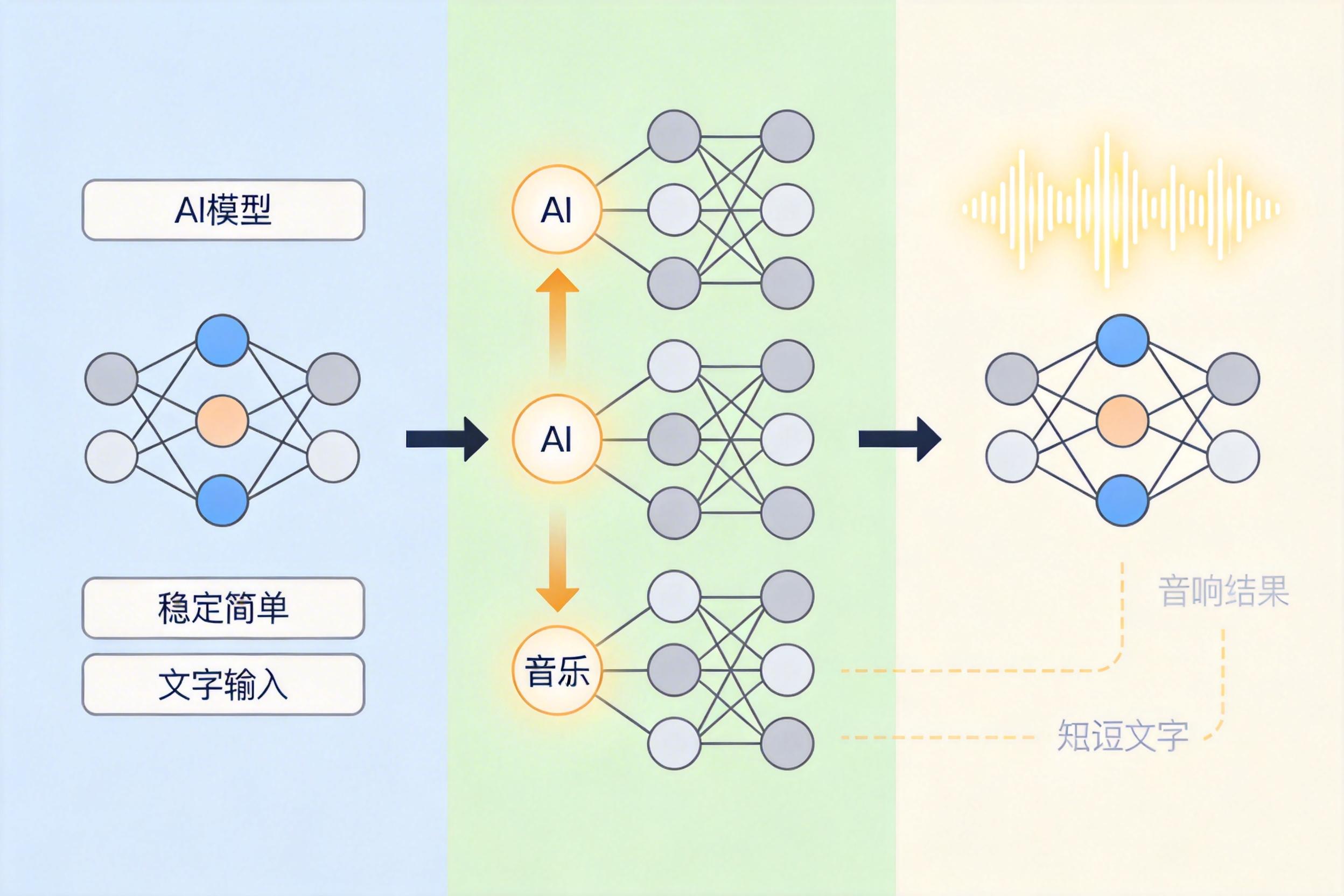
第二种是“混合到强”范式:先用弱、强混合的自然数据做微调,让AI适应真实世界的题目分布;再集中用强贡献题做强化学习,针对性补全“真听”的能力。
数据不会骗人:在MMAU-test-mini测试集上,“弱到强”范式把准确率从传统方法的70%-73%直接拉到了78.2%;在强音频贡献占比更高的MMAR测试集上,“混合到强”范式突破了67%的大关——这是此前所有方法都没摸到过的高度。
当然,这套方法也不是万能的。目前的音频贡献过滤,还只针对选择题设计,要拓展到音频描述、开放问答等更复杂的任务,还得重新设计判断标准。团队也只用到了AudioMCQ里不到一半的数据,更大规模的强化学习训练效果如何,还需要进一步验证。
更关键的是,AI的“听力”还远赶不上人类:人类能在嘈杂环境里精准聚焦某一个声音,能通过语气判断情绪,能从一段背景音里揪出细微异常,但AI现在还只能处理相对清晰、单一的音频场景。而且,这套方法依赖多个基准模型来判断音频贡献强弱,要是基准模型本身就有偏见,过滤出来的数据也会带着偏差。
从“能答”到“能听”,这一步看似细微,实则是AI从“拟合数据”到“理解世界”的关键跨越。过去我们总在追求AI的准确率,却常常忽略:那些靠捷径拿到的高分,本质上是一种“认知假象”。
真的理解,从来都不能走捷径。
就像学语言不能只背单词不学对话,练听力不能只看选项不听声音,AI要真正听懂这个世界,也得先学会“放弃捷径,认真去听”——这不仅是技术的进步,更是我们对AI认知的一次校准。