对抗知识焦虑,从看懂这条开始
App 下载
雨天拍照不用愁:AI跑到频谱域精准除雨
图像清晰度提升|纽约石溪大学|雨线去除|频谱域图像处理|SpectralDiff|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像清晰度提升|纽约石溪大学|雨线去除|频谱域图像处理|SpectralDiff|多模态视觉|人工智能
你有没有过这种经历:雨天出门拍了张好看的街景,回家放大一看,画面里全是歪歪扭扭的雨线,像有人在玻璃上乱划了几道。更气人的是,用手机自带的去雨功能,要么雨线没清干净,要么把建筑的棱角、树叶的纹理一起磨没了——就像给照片糊了层半透明的浆糊。
直到纽约石溪大学的团队搞出了SpectralDiff,这个困境才终于有了像样的解法。他们没在像素堆里和雨线死磕,而是绕到了图像的「后台」——频谱域,给每根雨线做了个精准的「定位手术」,还顺便把AI的计算速度提了18倍。为什么换个战场就能解决难题?这得从雨线的「隐藏身份」说起。
我们平时看的照片,是像素在空间域的排列——就像把无数个小色块拼在一起。但雨线这种东西,在空间域里太狡猾了:它会模仿树叶的纹理、建筑的线条,甚至和人物的发丝缠在一起,让AI根本分不清「该删的雨」和「该留的细节」。
但在频谱域里,雨线立刻就现了原形。你可以把频谱域想象成音乐的均衡器:空间域的像素是你听到的整首歌,频谱域就是把歌拆成了低音、中音、高音各个频段。雨线这种有固定方向的线条,在频谱域里会变成一条垂直于自身方向的亮线——就像在均衡器上某几个频段突然爆了峰值。不同粗细的雨线对应不同的「频段位置」,不同方向的雨线对应不同的「峰值角度」,简直自带一张独一无二的身份证。
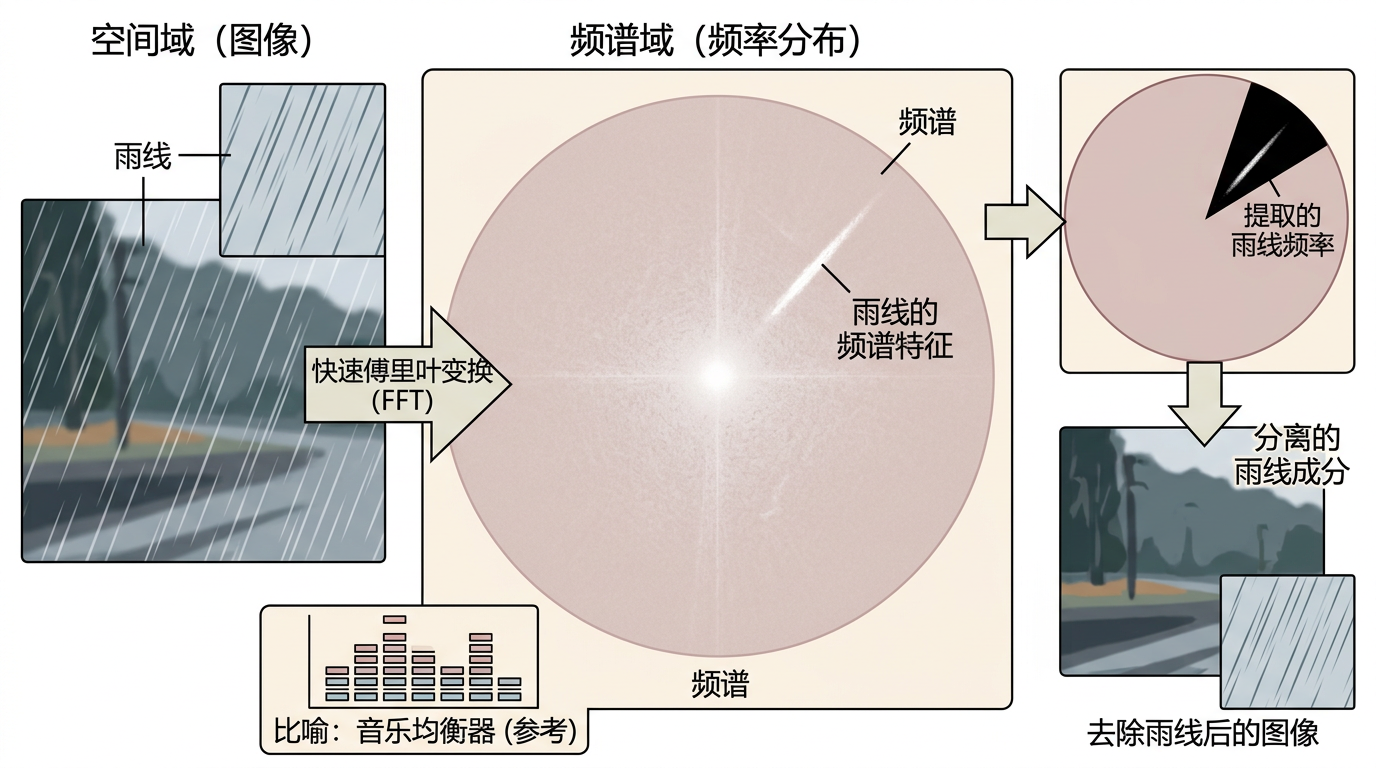
SpectralDiff的第一个聪明之处,就是把扩散模型的「加噪-去噪」过程搬到了频谱域。传统扩散模型是在空间域加无差别的高斯噪声,就像给整张照片泼墨;而SpectralDiff是在频谱域,对着雨线对应的亮线区域「精准泼墨」——用径向高斯函数控制雨线的粗细,用冯·米塞斯分布锁定雨线的方向,生成和真实雨线结构完全匹配的「结构化噪声」。
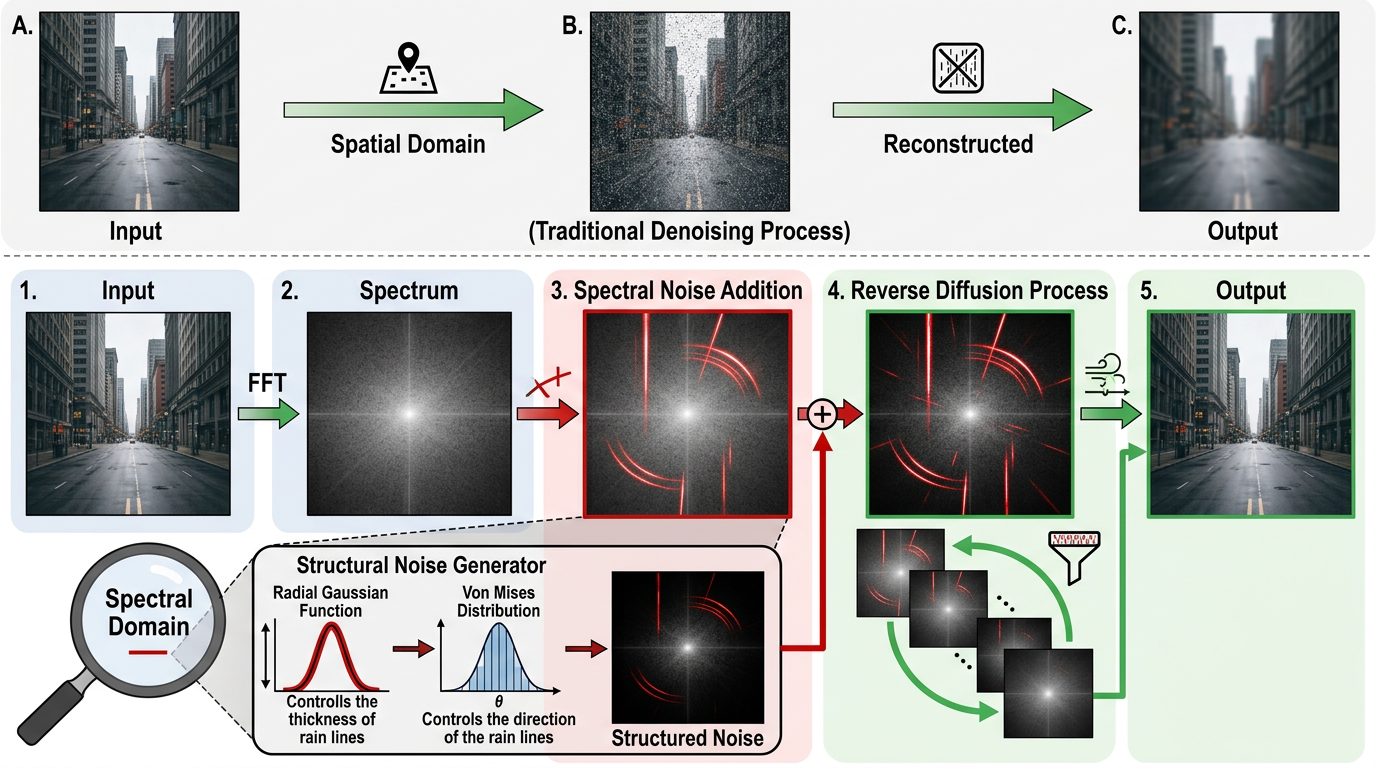
这样一来,AI在训练时学的就不是「怎么模糊掉所有细线」,而是「怎么精准拔掉那些带特定频谱标记的雨线」。
但问题来了——在频谱域搞操作,要不停做傅里叶变换,计算量会爆炸,根本没法在手机、摄像头这种设备上实时用。石溪大学的团队又拿出了第二个杀招:全乘积U-Net。
这里要用到一个信号处理的老定理:空间域的卷积,等价于频谱域的逐元素乘法。反过来想,我们要在频谱域做的「掩码乘法」,能不能在空间域用更简单的操作实现?
他们把传统U-Net里的卷积层,全换成了「乘积层」。简单说,就是先让AI根据输入的雨天图,动态生成一组「权重滤镜」,然后把输入图像和这组滤镜逐像素相乘——这就相当于在空间域模拟了频谱域的「精准过滤」。
别小看这个改动,计算量直接砍到了原来的1/18。传统3×3卷积层的计算量是18C²HW,而乘积层在通道数C较大时,计算量只有不到C²HW。论文里的实验数据很直白:用同样的硬件,传统扩散模型处理一张图要跑几十秒,SpectralDiff只用2秒多,甚至比一些轻量级的CNN模型还快。
更妙的是,训练的时候在频谱域注入结构信息,推理的时候完全在空间域运行——用户根本不需要知道傅里叶变换是什么,点一下去雨按钮,AI就已经在后台完成了「频谱定位-空间清除」的全套操作。
在Rain1400、RainCityscapes这些数据集上,SpectralDiff的PSNR(峰值信噪比)和SSIM(结构相似性)指标全都是第一,尤其是在真实场景的测试集里,比传统方法领先了一大截。但我认为,它也不是完美的。
现在的频谱掩码是用固定的数学分布生成的,只能模拟那些方向、粗细相对规律的雨线。可自然界的雨哪有那么听话?极端暴雨里的雨线是乱缠在一起的,还有被风吹得弯曲的雨丝,甚至是镜头上的雨滴反光——这些复杂的雨型,固定参数的掩码根本没法精准建模。
还有,虽然全乘积U-Net把计算量降了下来,但扩散模型本质上还是要多步迭代推理,在一些算力特别弱的老手机或者低端监控摄像头上,实时处理还是有点吃力。未来如果能把自适应的频谱掩码学习和更轻量化的扩散模型结合,才能真正把「精准去雨」装进每一台设备里。
其实SpectralDiff最值得关注的,不是它把去雨效果提了多少,而是它给AI图像处理指了一条新路子:与其在问题的表面死磕,不如绕到问题的「后台」,利用事物的物理本质来设计解决方案。
雨线的本质是有结构的频率信号,所以去雨的关键不是「模糊细线」,而是「精准过滤特定频率」。这个思路不仅能用来去雨,还能用来除摩尔纹、消条纹噪声、修镜头光晕——所有有固定结构的图像干扰,都能用这套「频谱定位+精准清除」的逻辑来解决。
找对问题的本质,比堆算力更重要。 或许未来的AI图像处理,会越来越像一个「精准的外科医生」,而不是一个「拿着砂纸的装修工」。