对抗知识焦虑,从看懂这条开始
App 下载
AI模型升级后,企业成本涨了3.6倍
开发者社区|指令遵循机制|成本报表|旗舰AI模型|AI产品经理|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载开发者社区|指令遵循机制|成本报表|旗舰AI模型|AI产品经理|大语言模型|人工智能
2026年4月的某个周三,一位AI产品经理盯着屏幕上的成本报表皱起了眉:他们团队刚升级到最新的旗舰AI模型,原本指望靠它提升30%的工作效率,结果单任务成本直接涨了3.6倍。更糟的是,模型对指令的执行变得异常刻板——以前一句模糊的需求就能得到灵活输出,现在必须把每个细节写进提示词,否则就会出现完全偏离预期的结果。这不是个例,全球范围内的开发者社区都在讨论:为什么AI模型越升级,反而越“难用”了?
新模型最直观的变化是指令遵循机制的彻底调整。它不再像前代那样对模糊指令进行“脑补”,而是严格按照字面意思执行——如果用户说“生成一份报告”,它只会输出纯文本报告,不会主动添加图表或分点;如果要求“按格式整理数据”,缺少格式说明时它会直接返回原始数据。这种转变带来了稳定性的提升:在结构化任务中,它的错误率降低了66%,但也让习惯了“AI懂我”的用户不得不重新学习提示词工程。
背后的技术逻辑是自适应思考机制的引入。模型会根据任务难度动态分配计算资源:简单任务快速输出,复杂任务则启动多轮推理和自我校验。但这种“智能节流”也带来了新问题:部分需要深度推理的复杂任务,会被模型误判为简单任务,导致输出质量骤降。有开发者反馈,在数学证明和代码重构场景中,新模型的表现甚至不如两年前的旧版本。
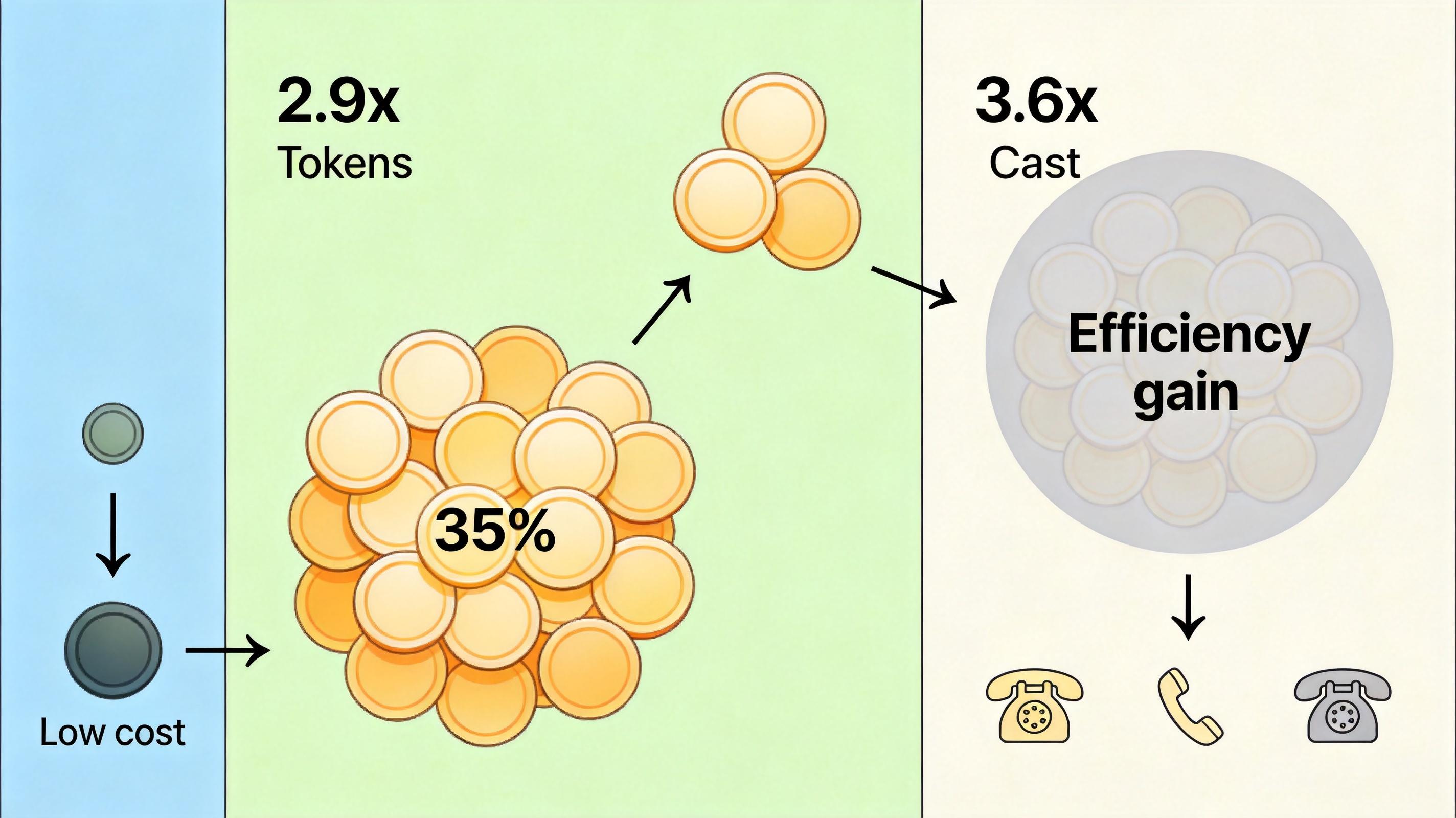
更核心的争议来自成本结构的变化。新模型的token消耗是前代的2.9倍,加上新分词器让英文文本的token数增加了35%,直接推高了使用成本。某企业的测试数据显示,相同的代码生成任务,新模型虽然调用次数减少了56%,但总成本还是涨了3.6倍——效率提升的收益,完全被成本上涨吞噬了。
在成本争议的另一面,新模型的长上下文处理和视觉能力确实实现了突破。它支持100万token的上下文窗口,相当于能一次性读完2000页的书籍,并且在长文本中间部分的信息召回率达到了82%,比前代提升了14个百分点。在多步骤的agentic任务中,它能保持数天的项目上下文,自动规划任务步骤并校验输出,减少了50%的工具调用错误。
视觉能力的升级则打开了新的应用场景。它支持最长边2576像素的高分辨率图像输入,能精准识别财务报表中的微小数据、科研论文里的复杂图表,甚至是软件界面上的细小按钮。在ScreenSpot-Pro视觉导航测试中,它的准确率从83.1%提升到了87.6%,意味着AI终于能可靠地完成自动化UI交互、视觉辅助编程等任务。
但这些能力的应用门槛并不低。长上下文处理需要用户学会拆分任务、优化提示词结构,否则只会徒增token消耗;视觉能力则需要专门的图像预处理工具,才能把复杂的现实场景转化为模型能理解的输入。对大多数普通用户来说,这些“黑科技”的价值,远不如成本上涨带来的冲击直观。
对于企业用户来说,新模型带来的是一场“两难选择”:一方面,它在结构化任务、代码生成和视觉处理上的能力提升,确实能解决一些之前无法自动化的难题;另一方面,成本上涨、使用门槛提高和性能波动,又让企业不得不重新评估AI的投入产出比。
不少企业开始采取“混合策略”:用新模型处理复杂的多步骤任务和视觉相关工作,用旧模型完成创意写作、简单问答等场景;或者通过提示词优化、语义缓存和任务路由等技术,降低新模型的使用成本。某金融科技公司通过优化提示词,把单任务的token消耗降低了20%,每年节省了近10万美元的API费用。
但这些优化手段都需要专业的技术团队支持,对中小微企业并不友好。更值得警惕的是,新模型的“自适应思考”机制带来了不可预测性——企业无法确定模型在某一时刻会分配多少计算资源,也无法保证输出结果的稳定性。这种不确定性,让企业在关键业务场景中不敢完全依赖AI。
当AI模型从“创意助手”转向“执行机器”,它正在倒逼用户改变与AI的相处方式:不再是依赖AI的“脑补”能力,而是学会用精确的指令引导AI完成任务;不再是追求单一模型的全能,而是通过多模型协同实现效率与成本的平衡。
这或许是AI技术走向成熟的必经之路:褪去“无所不能”的光环,回归工具的本质。未来的AI,不会是能读懂人心的“智能伙伴”,而是能精准执行指令的“高效员工”——它的价值,取决于用户能否用对它。
能力越精准,使用越专业。