对抗知识焦虑,从看懂这条开始
App 下载
Transformer去噪不凭玄学,靠的是均值法则
图像生成|均值去噪|DiT模型|扩散模型|Transformer|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像生成|均值去噪|DiT模型|扩散模型|Transformer|大语言模型|人工智能
当你用AI生成一张高清猫图时,可能不会想到背后的两个技术巨头正经历一场“身份解谜”:Transformer和扩散模型。前者靠自注意力横扫AI领域,后者靠逐步去噪生成逼真内容,两者结合的DiT模型早已成了图像生成的标杆,但没人能说清——为什么Transformer能把去噪这件事做得这么好?是参数堆出来的玄学,还是藏着某种被忽略的数学逻辑?直到2026年的一篇论文,第一次把这个黑箱的盖子掀开了一条缝。
你可以把扩散模型的去噪过程想象成:给你一张被墨汁泼脏的猫图,要你一点点把墨渍擦干净,最后还原出清晰的猫。Transformer做的,不是直接擦墨渍,而是先在脏图里找出所有看起来像“猫毛”“猫耳朵”的碎片,把同一类碎片凑到一起算平均值——因为墨渍是随机泼上去的,多块碎片的平均会让随机的墨渍相互抵消,剩下的就是干净的猫的特征。
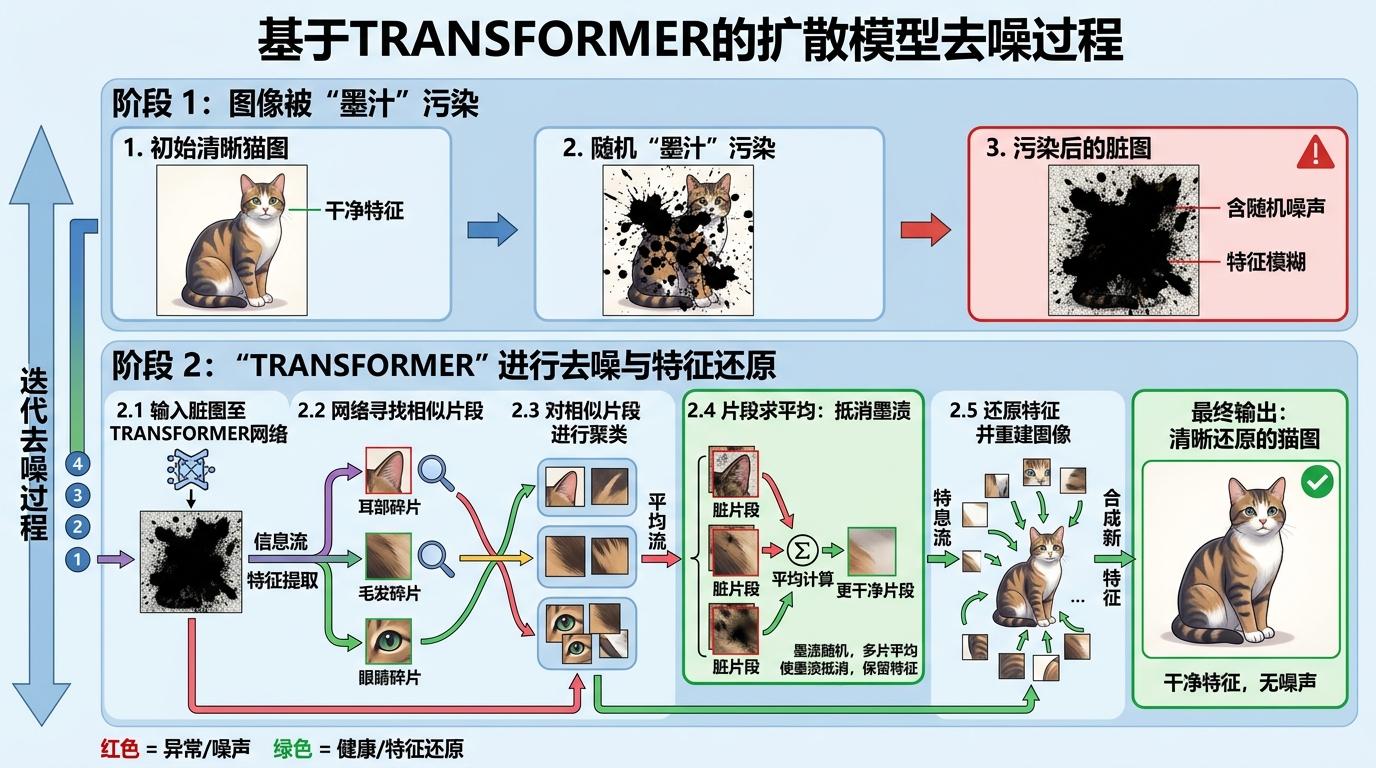
这就是论文揭示的核心:均值去噪机制。它的本质是信号处理里的经典思路——随机噪声的均值为零,只要有足够多的同类样本,平均就能把噪声“稀释”掉。而Transformer的自注意力,刚好天生擅长“找同类”:训练后它的注意力权重会向同类Token倾斜,异类Token的权重几乎可以忽略,最终实现“按模式分组,组内求平均”的操作。
更关键的是,论文用数学证明了,这种均值去噪能逼近贝叶斯最优风险——也就是在知道数据全部分布的情况下,能达到的最好去噪效果。这意味着Transformer的出色表现,不是靠运气,而是踩中了最优解的数学逻辑。
要证明这个结论,研究者得先搭一个“理论脚手架”——多Token高斯混合模型(MTGM)。你可以把它理解成:每张图不是一个整体,而是由多个“碎片”(Token)拼成的,每个碎片都来自某一种“基础图案”(比如猫、狗、车),但一张图里只会包含其中几种。这个假设刚好贴合真实图像的构成:一张图里通常是几个物体的组合,而不是乱成一团的像素。
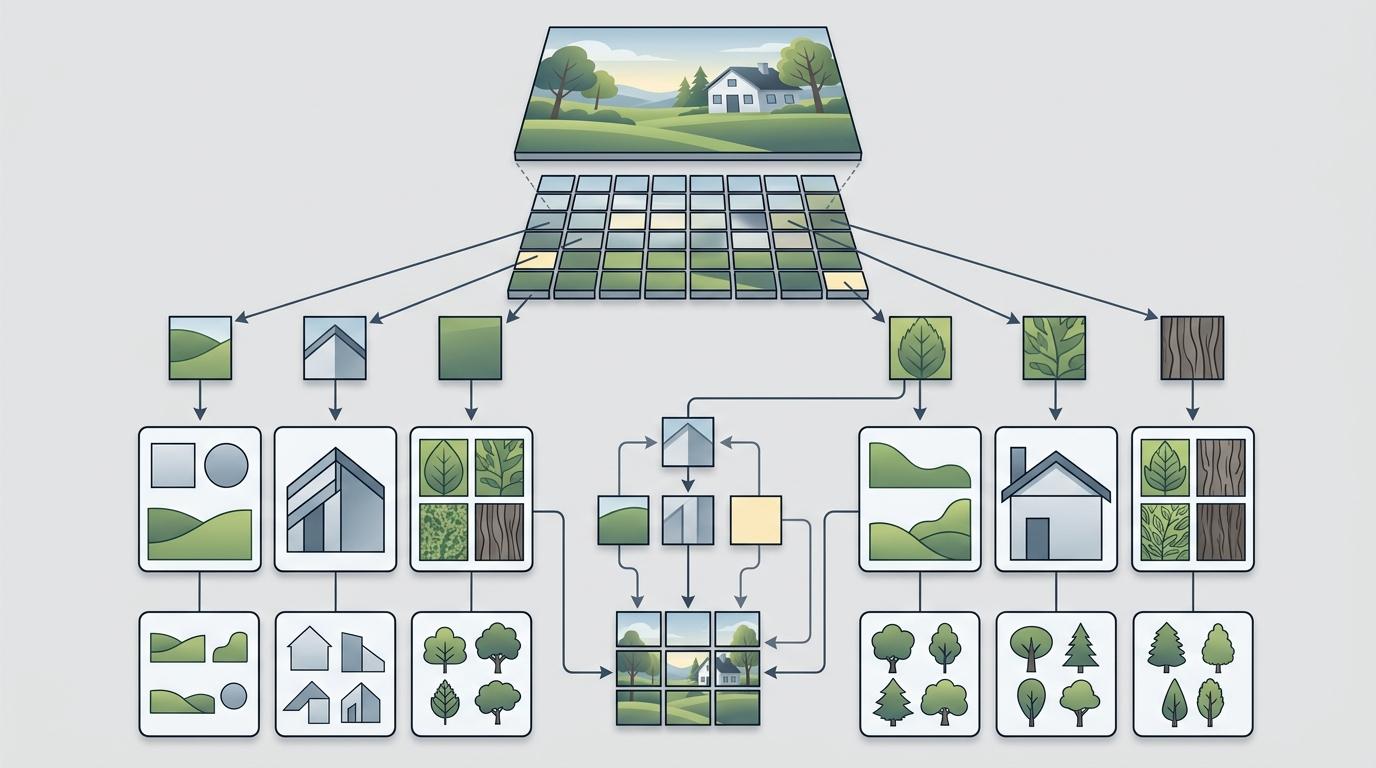
研究者用了一个极简的单层单头Transformer来做实验,训练目标就是标准的DDPM去噪损失——让模型预测当初加入的噪声。结果显示,只要满足三个条件,Transformer的损失就能收敛到贝叶斯最优风险附近:
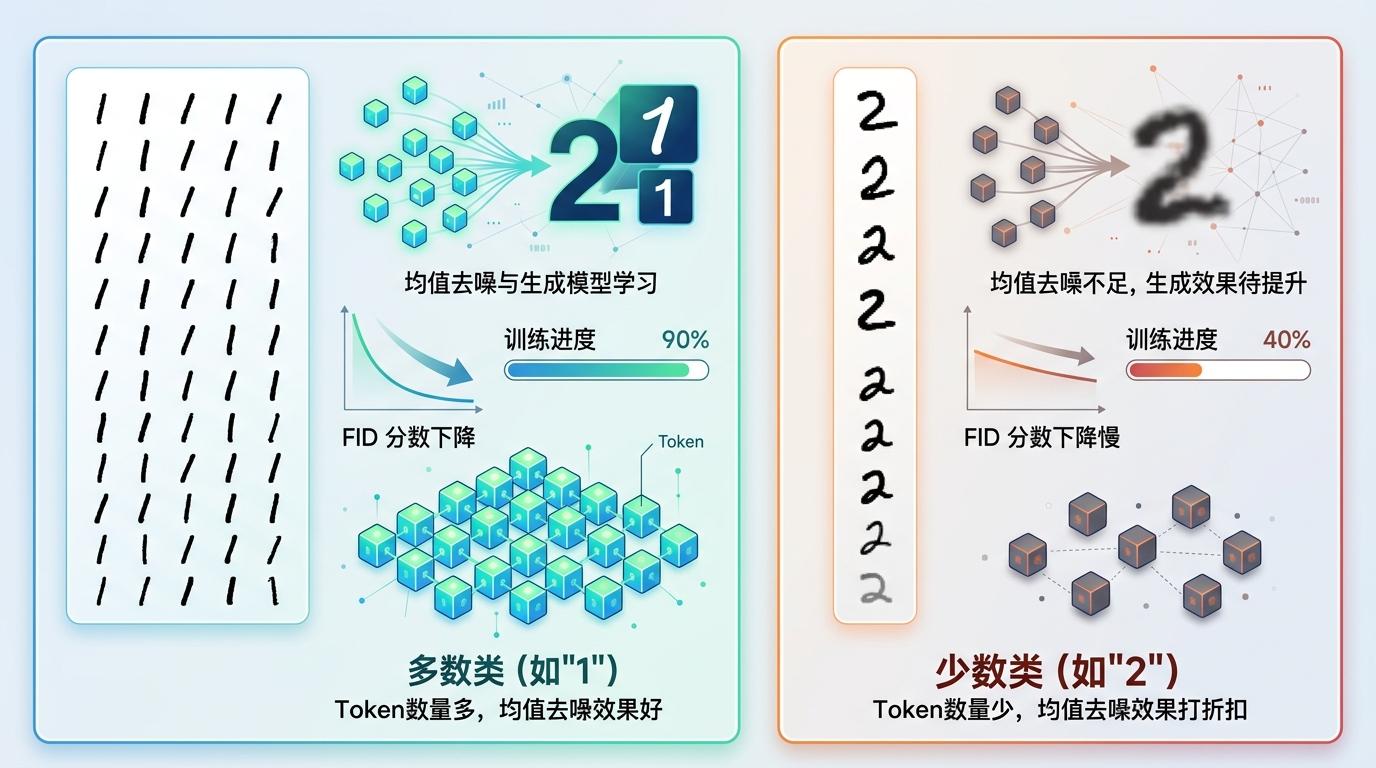
MNIST数据集的实验也验证了这个结论:当某个数字(比如“2”)是少数类时,它的FID分数下降得比其他数字慢——因为它的Token数量少,均值去噪的效果打了折扣,需要更多训练才能跟上。
这篇论文的意义,不在于直接让AI生成的猫图更清晰,而在于它第一次给“Transformer为什么能在扩散模型里生效”这个问题,提供了严格的理论答案。但它的局限性也很明显:
首先,它用的是极简的单层单头Transformer,而现实中的DiT模型是多层多头的,真实数据也不是规整的高斯混合分布——把这个结论推广到复杂模型和真实数据,还有很长的路要走。
其次,计算效率仍是大问题。Transformer的自注意力复杂度是O(n²),扩散模型本身又需要多步采样,两者结合后,高分辨率图像生成的计算成本高得吓人。虽然现在有线性注意力、稀疏注意力等优化方法,但离实时生成还有差距。
最后,模型的可解释性和安全性还没解决。就算我们知道了它靠均值去噪工作,也没法解释每一个注意力权重的具体含义;而扩散模型可能记忆训练数据、生成虚假信息的风险,也需要更完善的机制来规避。
当我们为AI生成的逼真图像惊叹时,往往容易忽略背后的数学逻辑——就像我们享受电灯带来的光明,却很少去想欧姆定律。这篇论文的价值,就是把Transformer和扩散模型结合的“黑箱”,变成了一个可以用数学语言解释的“白箱”。
它告诉我们,AI的进步从来不是玄学,而是一步步踩在数学的肩膀上。从均值去噪这个小小的理论突破出发,未来我们或许能设计出更高效、更可控的生成模型——毕竟,当我们理解了机器的“思考方式”,才能更好地让它为我们所用。
好的AI,从来不是靠参数堆出来的,而是靠逻辑撑起来的。