对抗知识焦虑,从看懂这条开始
App 下载
Transformer图像复原瓶颈,被这本“字典”打破了
卫星图像放大|老照片修复|图像复原|电子科技大学|自适应词元字典|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载卫星图像放大|老照片修复|图像复原|电子科技大学|自适应词元字典|多模态视觉|人工智能
你有没有过这种经历:翻出一张模糊的老照片,想用AI修复清晰,结果人物的脸是清楚了,背景的屋檐却断成了两截?或者放大一张低分辨率的卫星图,明明是连在一起的农田,AI却把它分成了三块?这不是AI不用心,而是它被“困”在了一个个小格子里——当前图像复原的主流工具Transformer,为了节省算力只能在局部窗口里处理信息,很难看清图像的全局结构。直到电子科技大学的团队拿出了一本“自适应词元字典”,让AI终于能“一眼看全图”。
你可以把Transformer处理图像的过程想象成拼拼图:传统方法是把整幅图切成几百个小格子,AI只在每个格子里拼碎片,格子之间的连接全靠猜。这种叫“基于窗口的自注意力”的机制,确实把计算量从“平方爆炸”降到了线性增长,让AI能处理高分辨率图像,但代价是——它永远不知道格子外面的碎片长什么样。
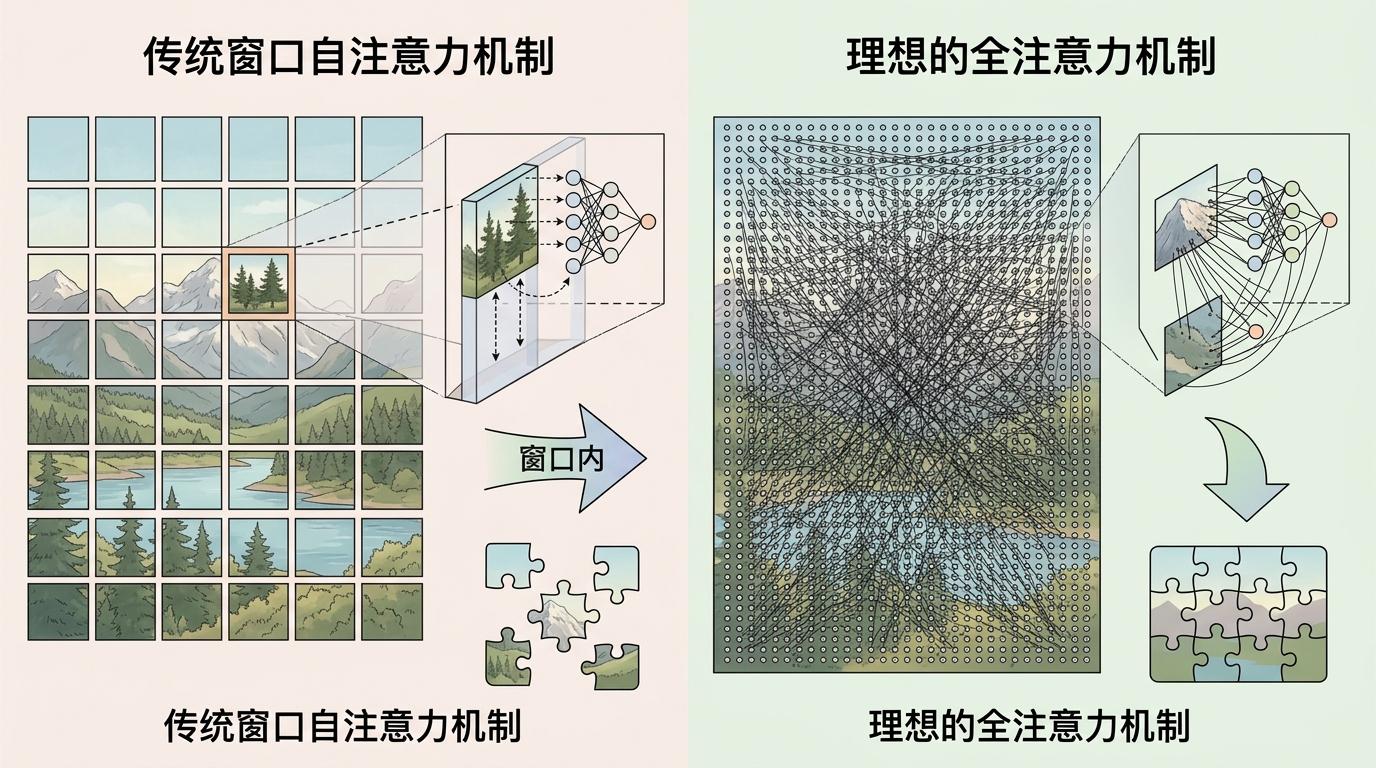
比如修复一张有河流的卫星图,河流从左上角流到右下角,被切成了十几个格子,AI在每个格子里都能认出“这是水”,但就是没法把这些水连成一条完整的河。电子科技大学数据智能团队的顾舒航教授和博士生张乐恒,把这个问题叫做“全局建模瓶颈”——AI能看清局部细节,却看不懂整体结构。
团队提出的自适应词元字典(ATD),本质上是让AI在训练时偷偷记一本“图像结构百科全书”。 训练的时候,AI会把见过的所有典型图像结构——比如直线、曲线、纹理、边缘——都拆解成一个个“词元”,存在这本字典里。等到处理新图像时,它会先用“词元字典交叉注意力”把输入图像的特征和字典里的典型结构做比对:哦,这个区域的纹理和字典里的“农田”匹配,那个区域的曲线和“河流”匹配。
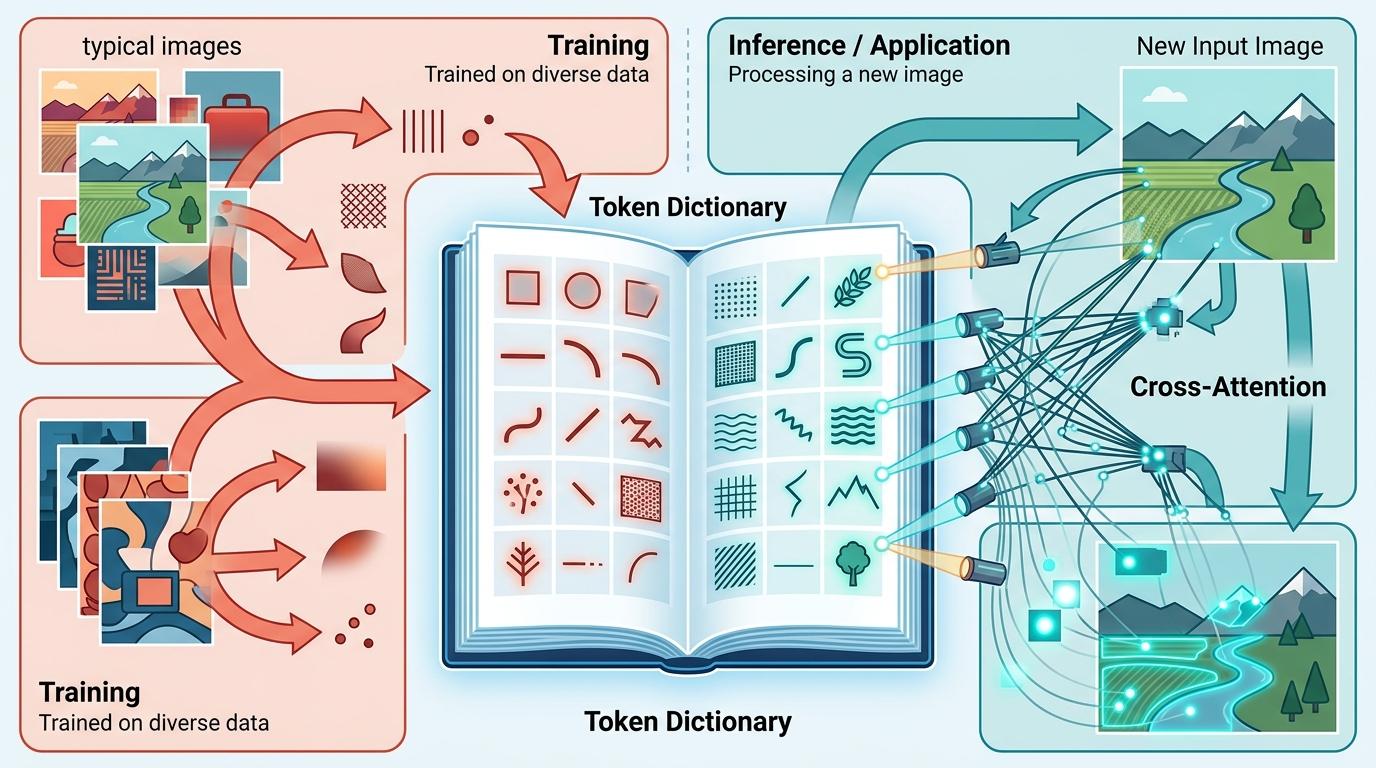
更聪明的是,它会根据匹配结果把整个图像的特征分成不同类别,比如“农田组”“河流组”“建筑组”,然后在每个组里做自注意力计算——这就相当于跳过了格子,直接把全图里所有相似的结构拉到一起处理。计算复杂度还是线性的,但AI终于能“看见”全局的结构了。
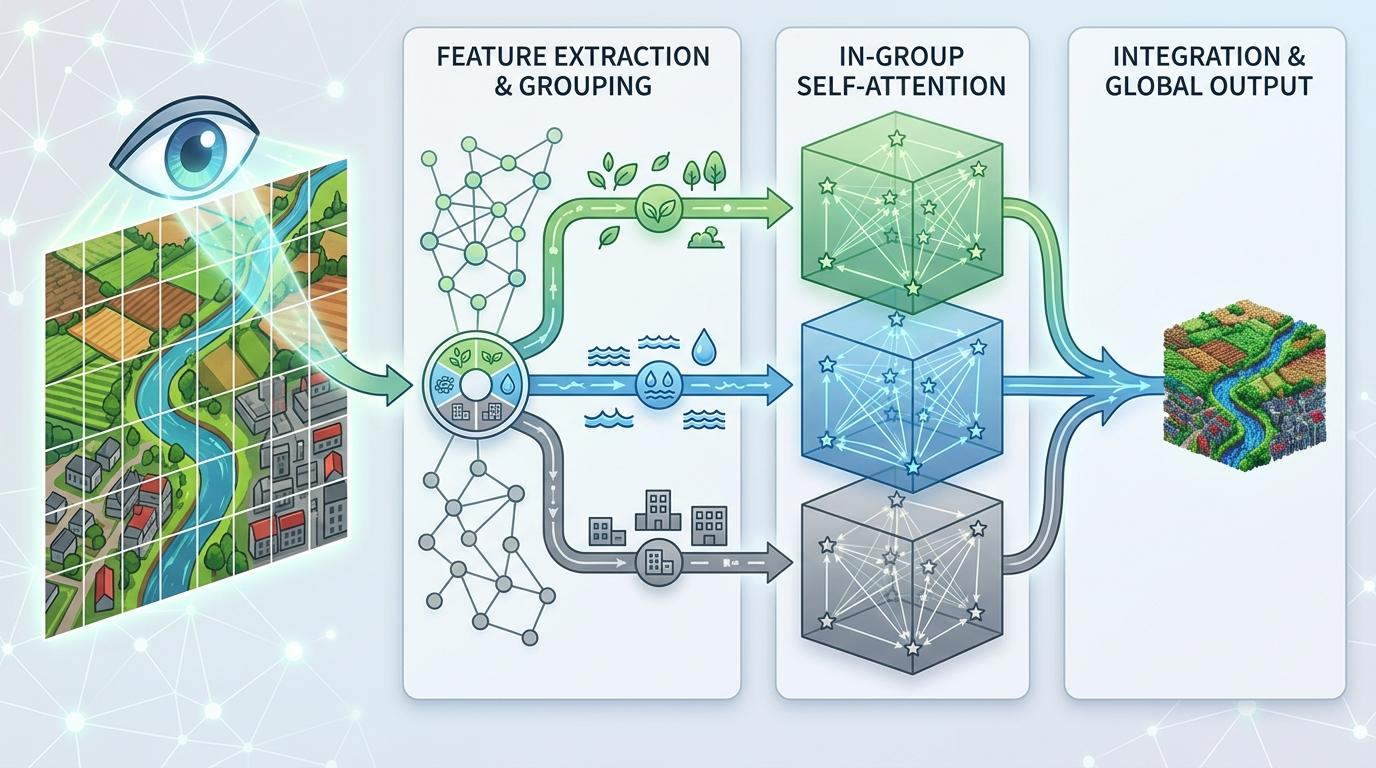
打个比方,以前AI是在几百个小房间里各自拼拼图,现在它先把所有蓝色的碎片(代表河流)都收集到一个房间,所有绿色的碎片(代表农田)收集到另一个房间,拼出来的自然是完整的河流和农田。
实验结果比理论更有说服力:在图像超分辨率任务中,ATD和它的轻量化版本ATD-light,在Set5、Set14等5个国际基准数据集上的PSNR(峰值信噪比,数值越高图像越清晰)都超过了当前的主流模型;多尺度版本ATD-U在图像去噪和JPEG压缩伪影去除任务中,同样实现了对现有方法的显著超越。 更关键的是视觉效果:修复后的老照片,人物的头发和背景的窗帘不再出现断裂;放大后的卫星图,河流和道路的连续性完全符合现实。当然,它也不是完美的——比如处理极端复杂的抽象艺术图像时,字典里没有对应的典型结构,效果会打折扣;而且要在移动端实现实时处理,还得进一步压缩计算量。
从只能看格子到能看全图,ATD的突破不止是提升了图像复原的质量,更重要的是它给Transformer找到了一种新的思路:不用在“计算效率”和“全局视野”里二选一,而是可以用外部先验知识来搭桥。 未来,这本“字典”里或许会加入更多内容——比如不同场景的语义信息、不同材质的纹理特征,甚至是多模态的先验知识。但现在,我们已经能看到一个更清晰的未来:AI不仅能修复图像的细节,更能理解图像的“灵魂”。 用先验知识,打破算力的围墙。