对抗知识焦虑,从看懂这条开始
App 下载
从群体到个体,基因研究终于精准到单个人
个体基因网络|丘成桐团队|邬荣领|基因位点|GWAS|基因组学|生命科学
对抗知识焦虑,从看懂这条开始
App 下载个体基因网络|丘成桐团队|邬荣领|基因位点|GWAS|基因组学|生命科学
你或许听过GWAS——全基因组关联研究,这种曾被寄予厚望的技术,在人类身上找到了3000多个和身高相关的基因位点,可这些位点加起来,只能解释三分之一的身高遗传差异。医生拿着一堆和疾病相关的基因变异,还是不知道该给你开什么药;农学家找到几十个抗寒基因,却没法精准培育出抗冻的茶树。我们明明掌握了海量基因数据,却像拿着一堆零件,拼不出完整的机器。直到2026年春天,邬荣领和丘成桐团队在PNAS发表的研究,给这堆零件连上了电线——他们把每个个体的基因,拼成了一张能运转的网络。
1918年,Fisher用一篇论文奠定了定量遗传学的基础:他把复杂性状的遗传变异,拆解成单个基因的“平均效应”。这就像统计一个城市的平均工资,能看出整体水平,却没法知道你隔壁邻居到底赚多少钱。后来的GWAS技术,本质上还是在找群体里的“平均基因效应”——它能告诉你“携带某基因的人更容易得糖尿病”,但没法解释为什么同样携带这个基因,有人发病有人没事。
问题出在基因从来不是单打独斗。一个基因的功能,可能被另一个基因增强,也可能被第三个基因抑制,这种“基因互作”才是复杂性状的核心。但传统方法要么只能分析单个基因,要么只能两两配对检验,面对人类基因组里的两万个基因,这种方法就像在大海里捞针,还得一根一根数。
邬荣领团队的FunGraph模型,直接跳过了“平均”这个步骤。他们把每个个体的等位基因当成网络里的节点,把基因间的调控关系当成带方向、有权重的边——就像给每个基因装上传感器,能看到谁在激活谁,谁在抑制谁,力度有多大。
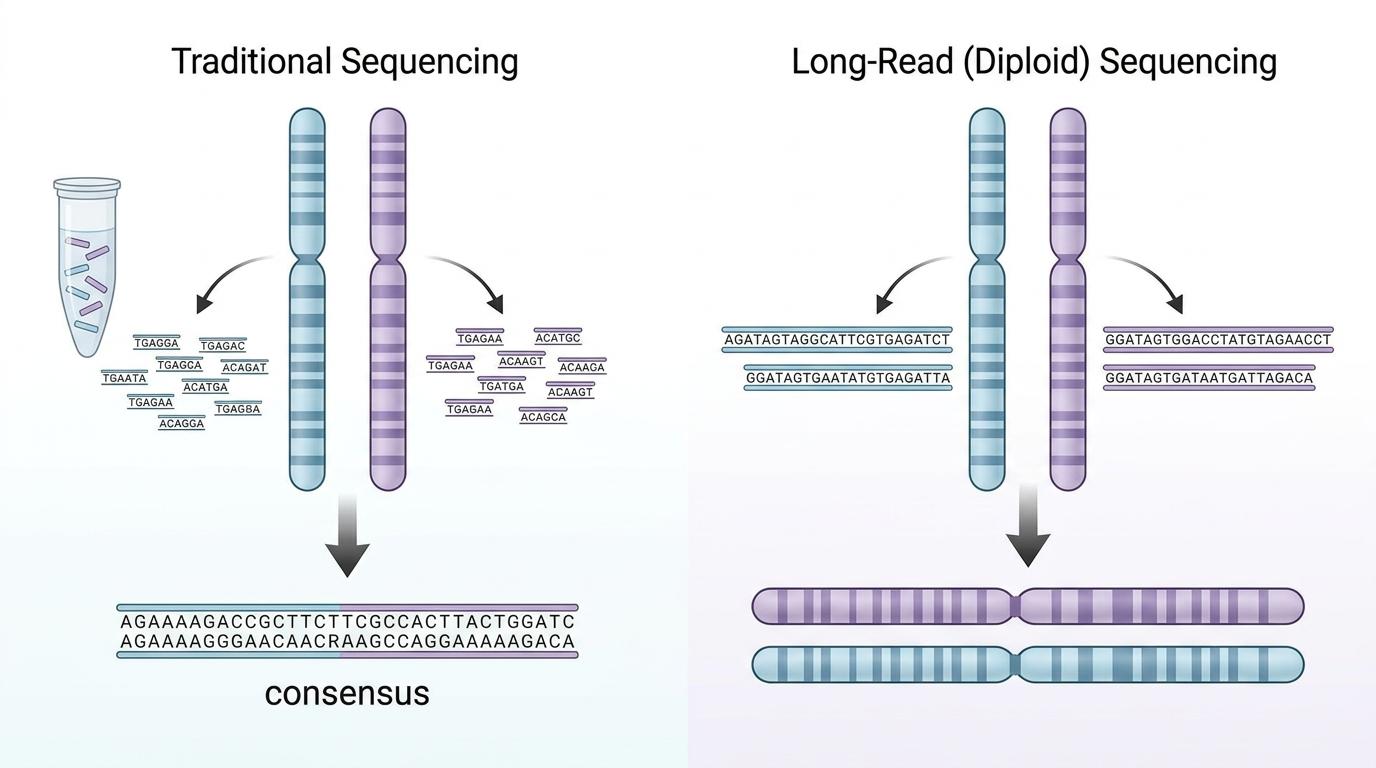
要拼出单个个体的基因网络,首先得拿到最精准的基因数据——二倍型测序。我们每个人的染色体都是成对的,一条来自父亲一条来自母亲,传统测序只能测出“这两个位置有A和T”,却分不清哪个A来自父亲哪个T来自母亲。而长读长测序技术的成熟,让我们能完整读出每一对染色体的序列,也就是“二倍型”,相当于拿到了基因的“原始设计图”。
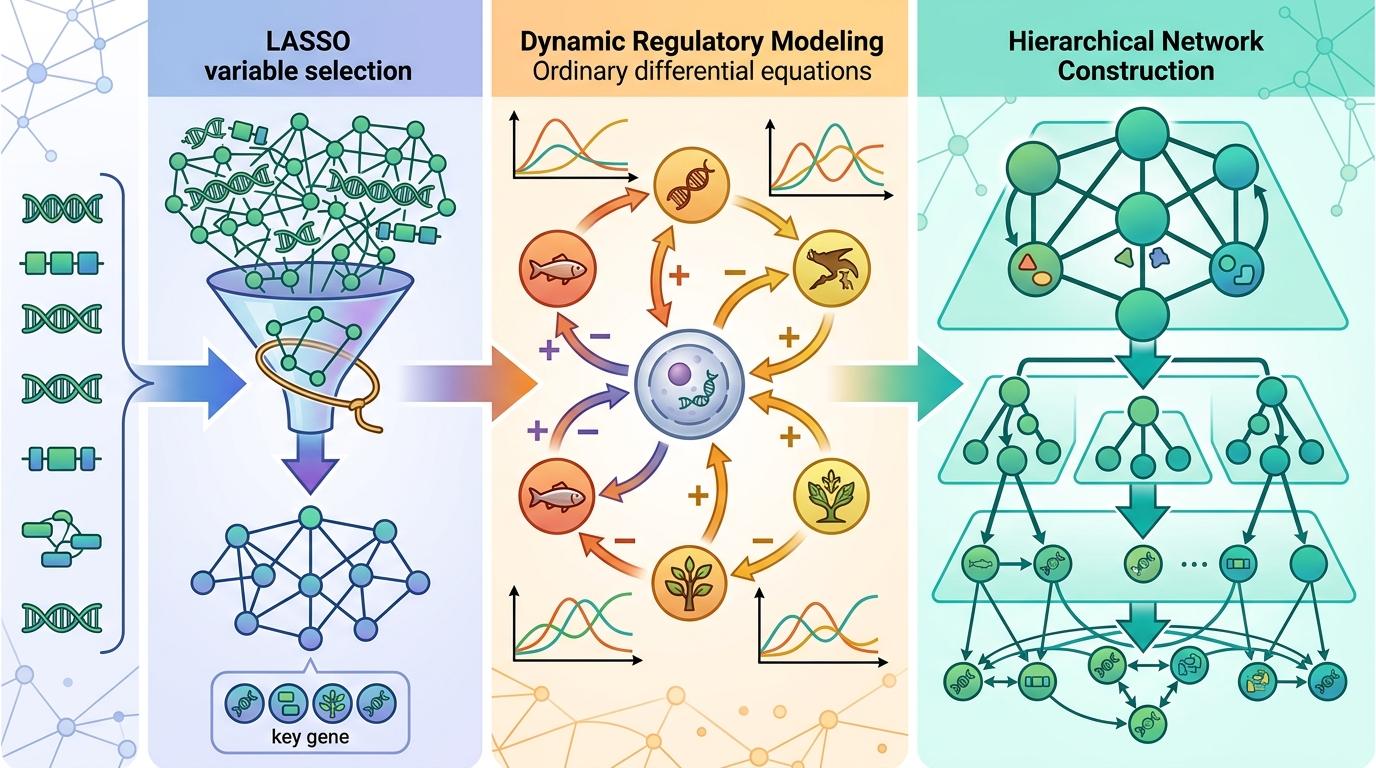
有了设计图,FunGraph模型就开始工作了: 它先用LASSO变量选择,从两万个基因里筛选出真正和目标性状相关的关键节点,避免网络过于复杂;再用常微分方程模拟基因间的动态调控关系——就像模拟一个生态系统,哪个基因是捕食者,哪个是猎物,它们的数量如何此消彼长;最后构建出一个多层级的网络,从粗粒度的模块间互作,到细粒度的单个基因调控,一层一层拆解清楚。
在木本植物的实验里,这个模型不仅找到了抗寒的核心基因,还发现这些基因在叶片和茎里的调控网络完全不同——原来植物的抗寒性,是不同器官协同作战的结果,而不是某个单一基因的功劳。
这个模型最直接的应用,就是精准育种。过去培育抗寒茶树,只能靠杂交和筛选,运气好的话十年能出一个新品种。现在用FunGraph模型,能直接在茶树苗里找到抗寒网络最完整的个体,或者精准编辑调控网络里的关键节点,把育种时间压缩到几年。
在医学上,它的潜力更大。比如癌症,传统治疗是“一刀切”——所有肺癌患者都用同一种化疗药,但实际上每个患者的癌症基因网络都不一样。用这个模型,能画出每个患者的癌症基因调控网络,找到网络里的“关键开关”,针对性地设计治疗方案,甚至预测哪个患者对哪种药物更敏感。
当然,它也有局限。目前的模型还只能处理转录组数据,没法整合表观遗传、蛋白质组等更复杂的信息;而且构建一个个体的基因网络,需要大量的计算资源,普通人还没法轻易获得。但这些问题,随着测序成本的下降和计算能力的提升,都在慢慢解决。
我们曾经以为,破解了基因序列就能破解生命的秘密,就像以为拿到了字典就能写出好文章。但生命的奥秘,从来不在单个的基因里,而在基因之间的连接里——那些看不见的调控关系,才是生命运转的真正密码。
邬荣领和丘成桐团队的研究,不是给我们找到了更多的基因零件,而是给了我们一张能看懂的电路图。从群体到个体,从单个基因到整个网络,我们终于开始真正理解,每个独一无二的生命,是如何被基因调控的。
读懂基因网络,才能读懂独一无二的你。