对抗知识焦虑,从看懂这条开始
App 下载
看不见的扰动,能让自动驾驶车同时失控
自动驾驶失控|对抗攻击|香港城市大学|像素扰动|UniAda攻击|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动驾驶失控|对抗攻击|香港城市大学|像素扰动|UniAda攻击|自动驾驶|人工智能
你坐在自动驾驶车里,窗外是熟悉的市区街道,车辆平稳得让你快要睡着。没人会注意到,此刻摄像头捕捉的画面里,正叠着一层人眼完全无法察觉的像素扰动——它细到连专业图像软件都要放大十倍才能看见,却能让汽车的AI大脑彻底混乱。方向盘会猛地偏转29度,油门不受控地轰到时速多22公里,一场事故可能在你眨眼间发生。这不是科幻,是香港城市大学团队2026年4月公布的UniAda攻击,首次把自动驾驶的转向和加速同时拖入失控边缘。
过去针对自动驾驶的对抗攻击,更像“拆车只拆方向盘”——大多只盯着转向控制,完全忽略了加速这个同样致命的环节。就像测试一辆车只看转弯灵不灵,不管油门会不会突然卡死,这种单一目标的测试,根本没法覆盖真实驾驶的风险。
UniAda的核心突破,是把攻击从“单点”升级成了“多目标协同”。它要找的不是针对某一张图片的专属扰动,而是一种“通用扰动”——同一个像素修改方案,能套在一整段驾驶视频的每帧画面上,让汽车在几分钟的行驶里持续做出错误操作。
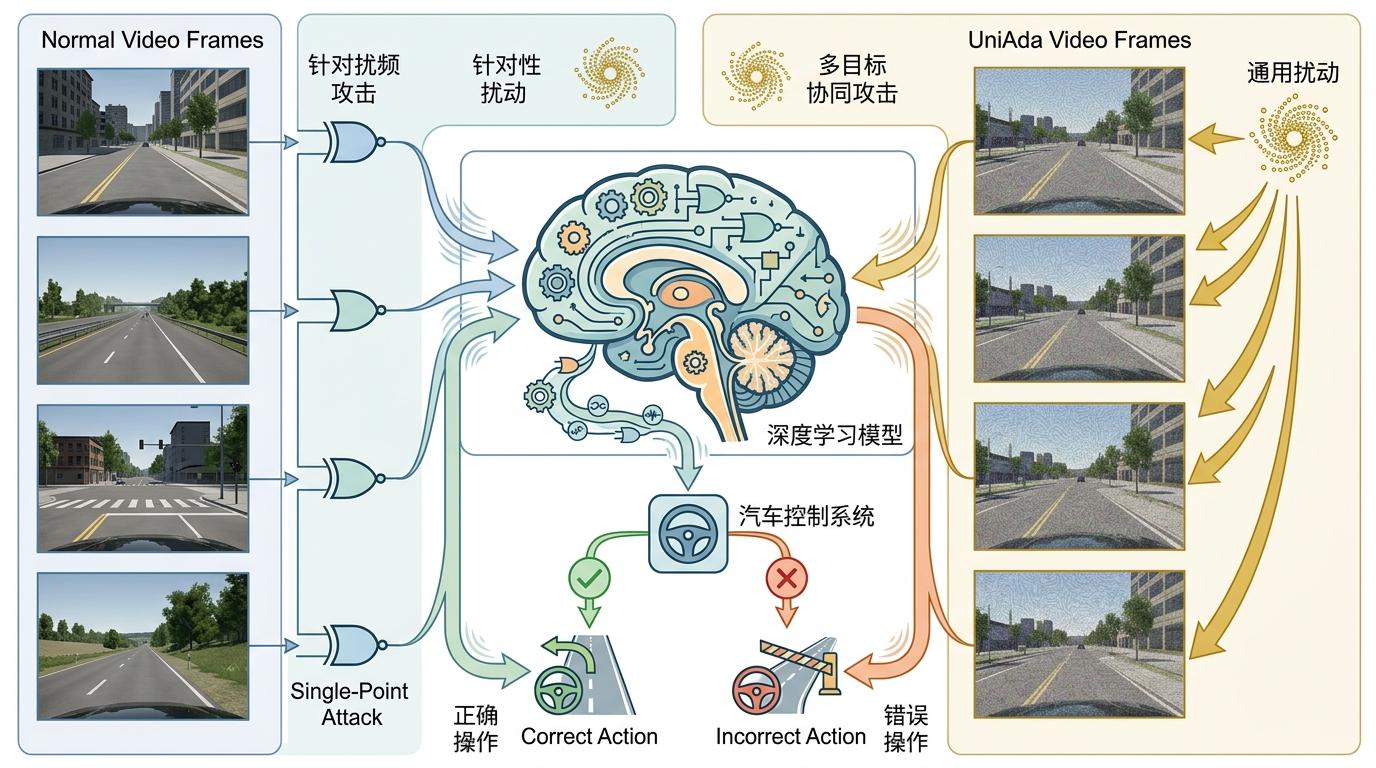
你可以把这种通用扰动理解成“万能病毒”:普通对抗攻击是针对某一扇门的特制钥匙,而它是能打开整栋楼所有门锁的万能卡。研究者通过动态调整转向和加速两个目标的优化权重,避免了顾此失彼——比如不会为了让方向盘偏得更狠,反而让加速扰动失效。在模拟测试中,这种方法让CILRS模型的转向误差从单目标攻击的22.6°飙升到29.2°,加速误差更是从7km/h跳到了22km/h。
多目标攻击最难的,是平衡两个目标的优先级。如果给转向和加速各分配50%的固定权重,很可能出现一个目标已经“用力过猛”,另一个还没达到攻击阈值的情况。UniAda的自适应权重方案(AWS),就是解决这个问题的关键。
这个方案的逻辑很简单:每次迭代时,算法会计算转向和加速两个目标的训练速度——如果转向的误差增长得比加速快,就自动调低转向的权重,给加速多分配优化资源;反过来就调高转向权重。就像教练盯着两个运动员的训练进度,随时调整训练量,确保两人同时达到最佳状态。
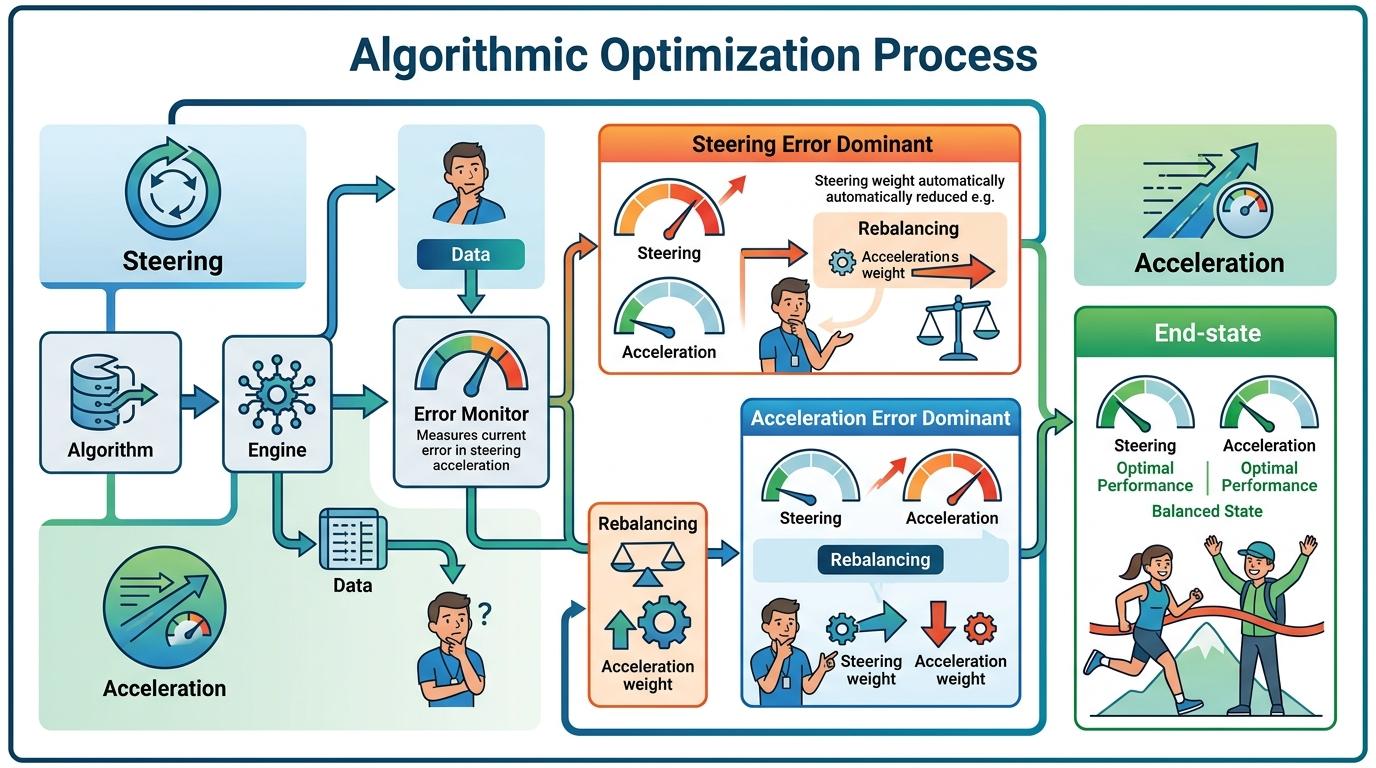
实验数据直观证明了这一点:在攻击CILRS模型的“Black Car”视频时,随着迭代次数增加,转向和加速的误差同步上升,最终稳定在相近的水平;而去掉自适应权重的对照组,加速误差的增长速度明显落后于转向。统计学t检验的结果也显示,UniAda在绝大多数测试场景下,表现都显著优于固定权重的版本。
UniAda的测试数据里,最值得警惕的不是模拟场景里的29°转向误差,而是真实道路测试中的3.54°——别小看这不到4度的偏差,在真实驾驶中,它已经足以让车辆偏离车道。更可怕的是,这种攻击的成功率高达96.3%,意味着只要扰动生效,几乎每帧画面都会误导汽车做出错误操作。
当然,UniAda目前还属于“白盒攻击”——攻击者必须完全掌握目标模型的结构和参数,这在现实的恶意攻击中很难实现。但它的价值不在于成为黑客的工具,而在于给自动驾驶行业敲响了警钟:现有的安全测试体系太片面了。
过去我们总觉得,只要把转向控制的鲁棒性做好,自动驾驶就安全了。但UniAda证明,一辆车的失控从来不是单一系统的问题——转向和加速的耦合失效,才是更接近真实事故的风险。而且,这种通用扰动的存在,意味着攻击者不需要逐帧设计攻击,只要找到一个通用方案,就能让整段行程的车辆持续失控。
当我们为自动驾驶的便捷欢呼时,往往忽略了它的“阿喀琉斯之踵”——那些看不见的微小扰动,可能比肉眼可见的障碍物更致命。UniAda的意义,从来不是展示“如何让车失控”,而是提醒我们:自动驾驶的安全,从来不是单一环节的坚固,而是整个系统在极端场景下的协同鲁棒性。
看不见的扰动,才是最致命的失控。 未来的自动驾驶安全测试,必须从“单点防御”转向“系统抗风险”,否则我们可能在不知不觉中,把无数人置于看不见的危险之中。