对抗知识焦虑,从看懂这条开始
App 下载
让AI给医生讲明白:它是怎么看病的
CT影像诊断|医学AI黑箱|深圳理工大学|中国科学院深圳先进技术研究院|类关联流形学习|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载CT影像诊断|医学AI黑箱|深圳理工大学|中国科学院深圳先进技术研究院|类关联流形学习|大语言模型|临床诊疗技术|医学健康|人工智能
当CT影像在屏幕上加载完成,AI系统在0.3秒内给出“肺癌高危”的诊断结果——这是如今很多医院的日常。但医生盯着屏幕上的热力图,却只能看到一片模糊的高亮区域:AI到底看到了什么?是结节的形状,还是血管的走向?如果它错了,错在哪里?
这种“只给结果,不给理由”的黑箱,正在成为医学AI走进临床的最大障碍。直到中国科学院深圳先进技术研究院与深圳理工大学的团队,用一种叫类关联流形学习(CAML)的技术,第一次让AI把看病的逻辑“说”了出来。
你可以把医学AI的训练过程想象成让一个孩子认水果:给它看一万张苹果的照片,它最终能准确指出苹果,但它记住的可能不是苹果的形状和颜色,而是每张照片里都出现的白色果盘。

这就是医学AI最隐蔽的风险——捷径学习。它会捕捉数据里的非医学规律:比如某家医院CT机的默认对比度、胸片上的设备编号,甚至是患者的年龄标签,用这些和疾病无关的特征来做诊断。更糟的是,它可能学到连人类都不知道的“规律”,却无法解释,一旦出错就是致命的。
传统的可解释方法,比如给影像画热力图,只能告诉医生“AI关注了这里”,却没法说清“为什么关注这里”,更没法展示它的整体判断逻辑。就像只给你看一道菜的最后一勺,却不告诉你它是怎么炒出来的。
这种“解释性鸿沟”,让医生不敢完全信任AI,也让监管机构对AI医疗器械的审批慎之又慎。
CAML的思路,是把AI脑子里的“看病逻辑”,拆解成一张能看懂的地图。
你可以把AI处理的每一份医学数据——不管是胸片、心电图还是基因序列——想象成一个包裹:里面既有和诊断相关的“核心文件”,也有和个体相关的“包装填充物”。CAML做的第一件事,就是把这两部分精准分开:它用生成式模型把所有样本的“核心文件”提取出来,映射到一个只有8维的低维空间里,这就是类关联流形。
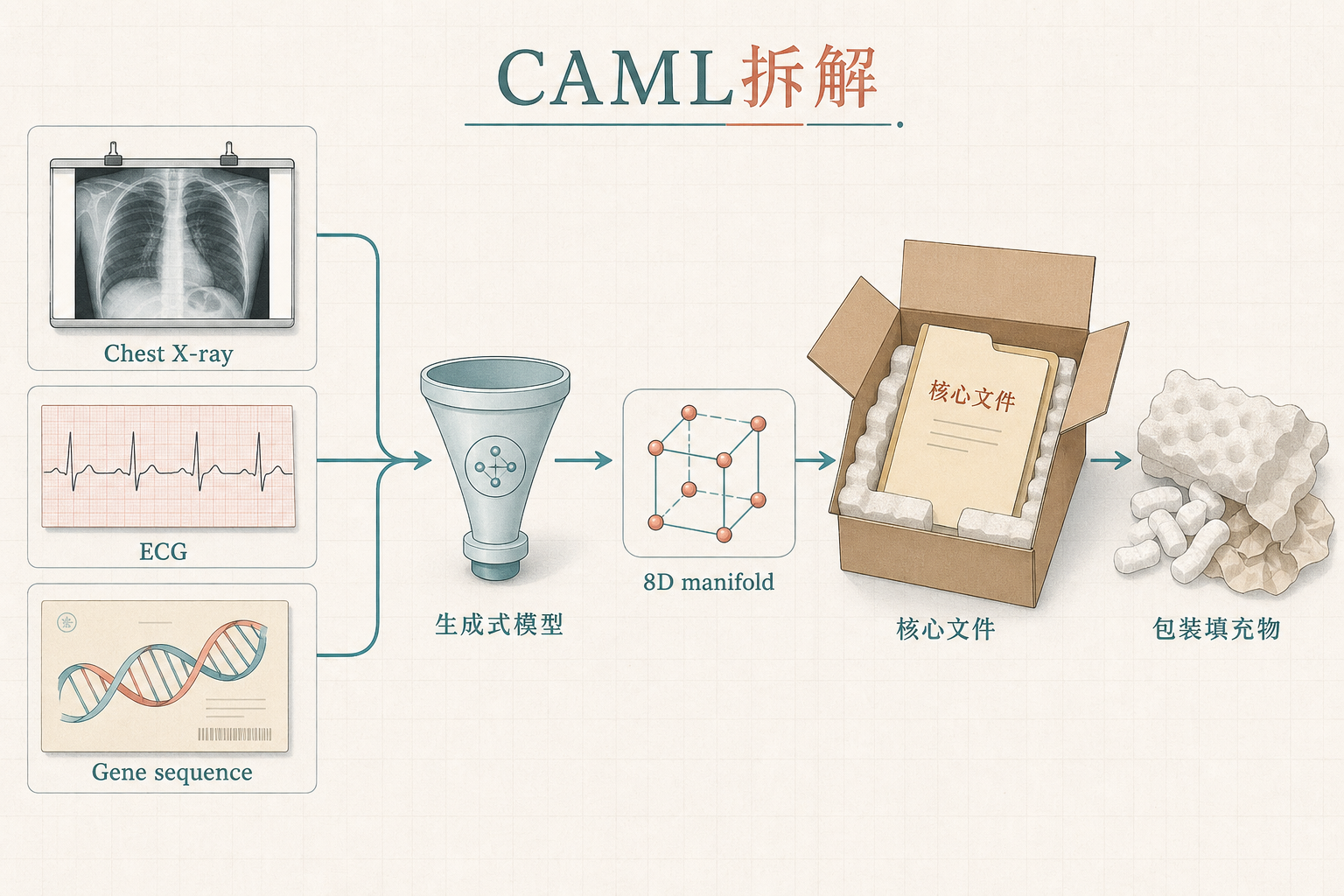
这个低维空间里的每一个点,都对应着一种和诊断相关的共性模式。比如所有肺癌高危样本的点会聚集在一个区域,肺炎样本则在另一个区域,区域之间的边界就是AI的决策边界。
更关键的是,CAML能沿着这个边界“修改”样本:给一张正常胸片做细微调整,让AI的诊断从“正常”变成“肺炎高危”,同时生成修改后的影像——医生能直观看到,到底是肺部纹理的哪一点变化,让AI改变了判断。这就像让AI演示:“你看,把这里的阴影加深一点,我就会认为是肺炎。”
团队在6类医学数据集上做了测试:在保持诊断准确率只下降1%-3%的前提下,CAML的解释被临床专家的接受度,比传统方法高出了47%。
CAML的价值,不止于让AI“说清楚”,更在于它能帮人类“发现新东西”。
在测试中,它曾在脑肿瘤MRI数据里,发现了一种连神经科专家都没注意到的亚型分布——某些看似无关的肿瘤影像特征,在低维空间里呈现出清晰的聚类。这意味着这些特征背后,可能藏着未被发现的病理规律。
更重要的是,它能帮监管机构快速排查AI的风险:比如当它发现某个AI模型的决策边界和设备型号高度相关,就说明这个模型可能在依赖捷径学习,根本没法推广到其他医院。
当然,CAML也有局限:它需要大量计算资源来生成低维流形,目前还没法做到实时解释;对于多模态融合的复杂模型,它的拆解能力还有待提升。但它至少迈出了关键一步——让AI从“只会看病的工具”,变成“能和医生对话的伙伴”。
当我们谈论医学AI的未来,我们谈论的从来不是让AI取代医生,而是让它成为医生的“第二双眼睛”。这双眼睛不仅要看得准,还要能告诉医生:“我看到了这个,所以我这么判断。”
CAML的出现,就是给这双眼睛加上了“说话的能力”。它让医学AI从一个神秘的黑箱,变成了一个可以被理解、被验证、甚至被一起探索未知的伙伴。
信任始于理解,智能源于透明。 未来的诊室里,AI和医生的对话,或许会成为最寻常的声音。