对抗知识焦虑,从看懂这条开始
App 下载
写文档就能做视频,Adobe重构创作逻辑
三层映射逻辑|文本生成视频|Doki|Adobe研究院|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载三层映射逻辑|文本生成视频|Doki|Adobe研究院|AIGC|人工智能
你有没有过这种经历:脑子里攒了一肚子故事,打开剪辑软件却被时间线、轨道、转场按钮逼得没了兴致?或是用AI生成了几个镜头,却发现前一秒的柯基下一秒变了“地狱犬”,反复调整提示词到崩溃?
2026年3月,Adobe研究院推出的Doki,把这一切麻烦全抹掉了——你不需要学任何剪辑操作,打开一个空白文档,像写作文一样敲下“@柯基 跑进@机场,#特写 它的脸”,一段风格统一、画面连贯的视频就会在旁边自动生成。这不是科幻,是把视频创作的核心,从“操作软件”拉回了“讲故事”本身。
Doki的核心是一套“文档-段落-镜头”的三层映射逻辑——这是它能让文字直接变视频的关键。
你可以把整个文档当成一部电影的完整项目:开头的定义是“剧组筹备”,中间的段落是“分场景拍摄”,每一段里的镜头标记就是“具体拍法”。敲下斜杠“/”选择“新建镜头”,后面跟着的文字就是你的“拍摄指令”,系统会先生成一张静态预览图让你确认,没问题再生成动态视频。
更聪明的是段落的作用:同一个段落里的镜头会自动共享上下文。比如你在第一段写“@柯基 叼着行李走进@机场”,下一个镜头只需要写“@柯基 跳上登机梯”,Doki会自动记住机场的场景、柯基的样子,不用你反复描述。这就像剧组在同一个片场连续拍镜头,灯光、布景、演员状态自然保持一致。
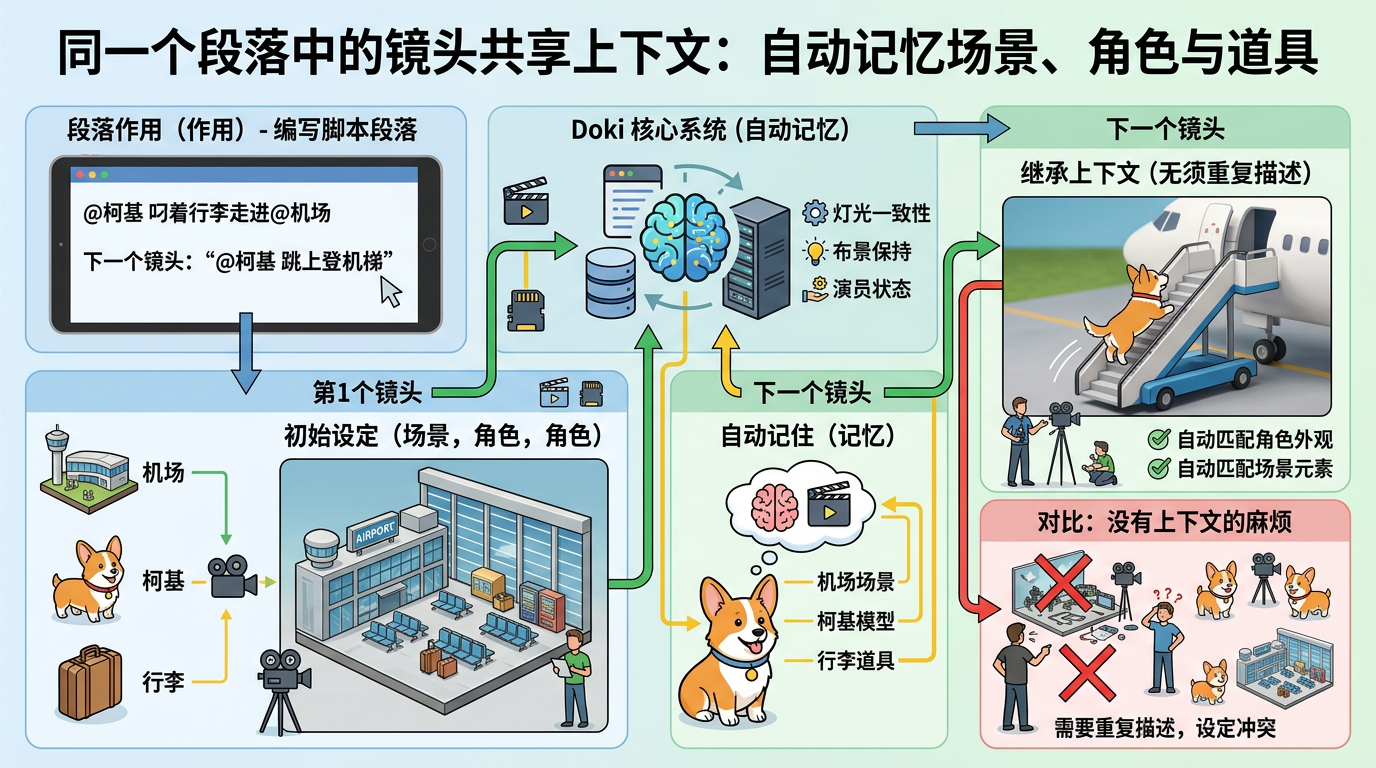
这种设计直接干掉了传统创作的“碎片化痛点”:你不用在Word写剧本、Midjourney画角色、Runway生镜头、Premiere剪视频之间来回切换,所有操作都在一个文档里完成,思路再也不会被打断。
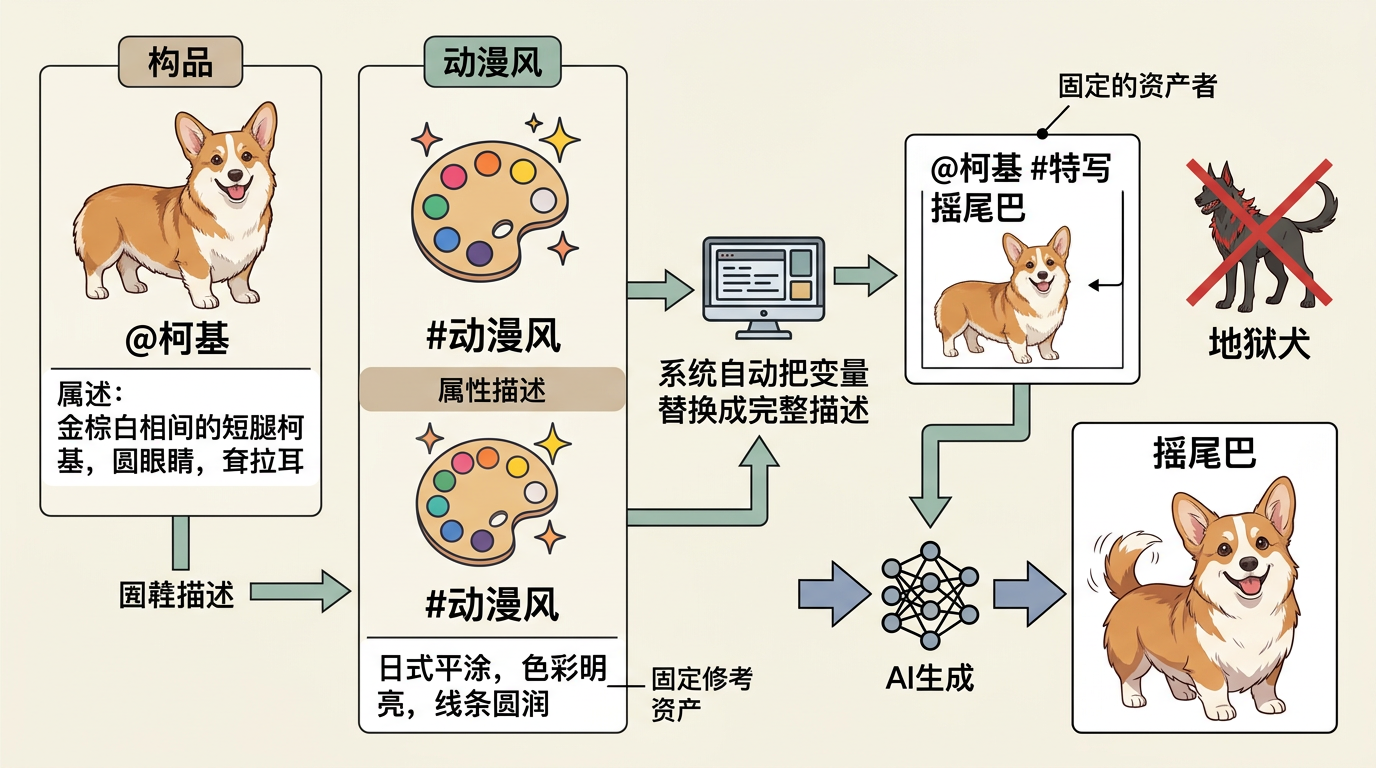
AI生成视频的老毛病——角色“变脸”、风格漂移——Doki用一套参数化定义系统解决了,说穿了就是给故事元素建“变量库”。
用@符号定义“名词”:@柯基 = 金棕白相间的短腿柯基,圆眼睛,耷拉耳;用#标签定义“形容词”:#动漫风 = 日式平涂,色彩明亮,线条圆润。这些定义一旦建好,后面的镜头里只要写“@柯基 #特写 摇尾巴”,系统就会自动把变量替换成完整描述,再加上你给柯基绑定的参考图,AI生成时就像拿着固定的演员定妆照和场景施工图,再也不会把柯基生成“地狱犬”。
最爽的是批量修改:如果想把整个视频风格从#动漫风改成#黏土定格风,你只需要修改#动漫风的定义,所有引用这个标签的镜头都会自动标记为“待更新”,一键就能全部重新生成。这比传统制作里逐帧调整风格,效率提升了不止一个量级。
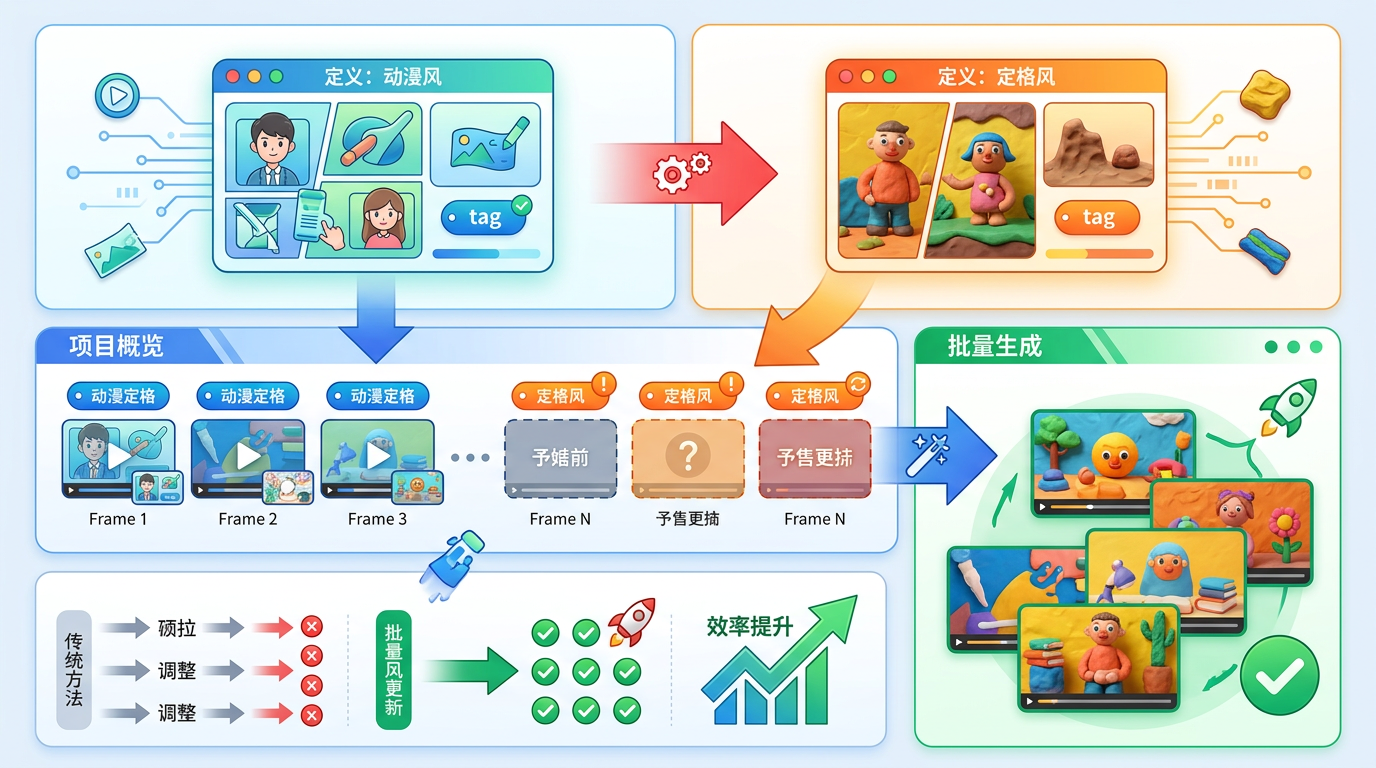
用开发者的话说,这是把“维持一致性的责任从用户大脑转移到了系统架构”——你不用再当AI的“翻译官”,只要专注于写好故事。
Doki的AI协作完全是“以你为中心”:你可以选“亲力亲为”模式,自己定义元素、写镜头,AI像听话的剧组严格执行指令;也可以选“运筹帷幄”模式,把“柯基机场登机的动漫短片”这个想法丢给侧边栏AI,它会直接生成包含所有定义和镜头的完整草稿,你再用内联AI精修——选中一段文字说“把这里改得更紧张点”,AI就会直接修改文本描述,所有操作都在你看得见的文本层面,没有黑箱。
一周的用户测试里,10位从新手到专家的参与者做了46个视频,系统可用性得分81.2分(优秀级别)。新手说“第一次把脑子里的想法直接变成了视频”,专业创作者则把它当超级故事板——快速生成动态分镜,和团队沟通创意的速度比手绘快了好几倍。
当然它也有局限:AI生成偶尔还是会有随机性,帧级别的精细控制(比如让柯基做特定手势)还做不到,用文字描述复杂镜头运动也有点抽象。但这些都是AI模型本身的问题,Doki的核心逻辑已经跑通了。
当视频创作退回到“写文档”的本质,我们其实是在重新思考人机协作的边界:AI该做的是执行那些重复、机械的工作,而人类要做的,是讲好一个故事。
Doki不是要替代剪辑师,它是要让更多人能跨过技术门槛,把脑子里的故事变成视频。就像打字机让更多人能写作,Doki可能会让更多人能当“导演”。
最好的创作工具,是让你忘了它的存在。