对抗知识焦虑,从看懂这条开始
App 下载
给AI装上手,它终于能伸进虚拟世界了
第一人称视角|手势识别|虚拟交互|南洋理工团队|Hand2World系统|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载第一人称视角|手势识别|虚拟交互|南洋理工团队|Hand2World系统|多模态视觉|人工智能
你对着空气比了个抓杯子的手势,屏幕里的第一人称视角中,一只手真的伸进桌上的场景,稳稳握住了那个玻璃杯——你甚至能调整手势角度,让它换个姿势捏杯柄,画面实时跟着变。这不是科幻电影,是南洋理工团队刚推出的Hand2World系统做到的事。在此之前,哪怕是能生成逼真视频的Sora,能让你漫游3D场景的Genie 3,都只能让你当一个“看客”,没法真正“触碰”虚拟世界里的任何东西。而现在,AI终于有了能和世界互动的“手”。为什么之前的技术都卡在这一步?
你可以把传统AI学手势的过程想象成:只见过被杯子、书本挡住半只的手,突然给它看一只完全张开的空手,它反而会凭空画出不存在的遮挡物——这就是2D手部mask方法的死穴:训练时看的是残缺的手,实际用的时候接收到的是完整手形,数据分布完全对不上,生成的画面自然满是伪影。
Hand2World直接抛弃了2D mask,改用MANO参数化3D手部模型——它能从单目视频里还原出完整的三维手部网格,就像给AI看了手的“透视图”,再把这个3D模型投影成“填充轮廓+线框叠层”的复合信号。不管手有没有被挡住,这个信号的格式都完全一致,AI不用再纠结“手被挡住了多少”,只需要根据场景自己推断遮挡关系就行。线框还能在手指互相挡住时,给AI补上关节结构的细节,这是纯2D轮廓做不到的。
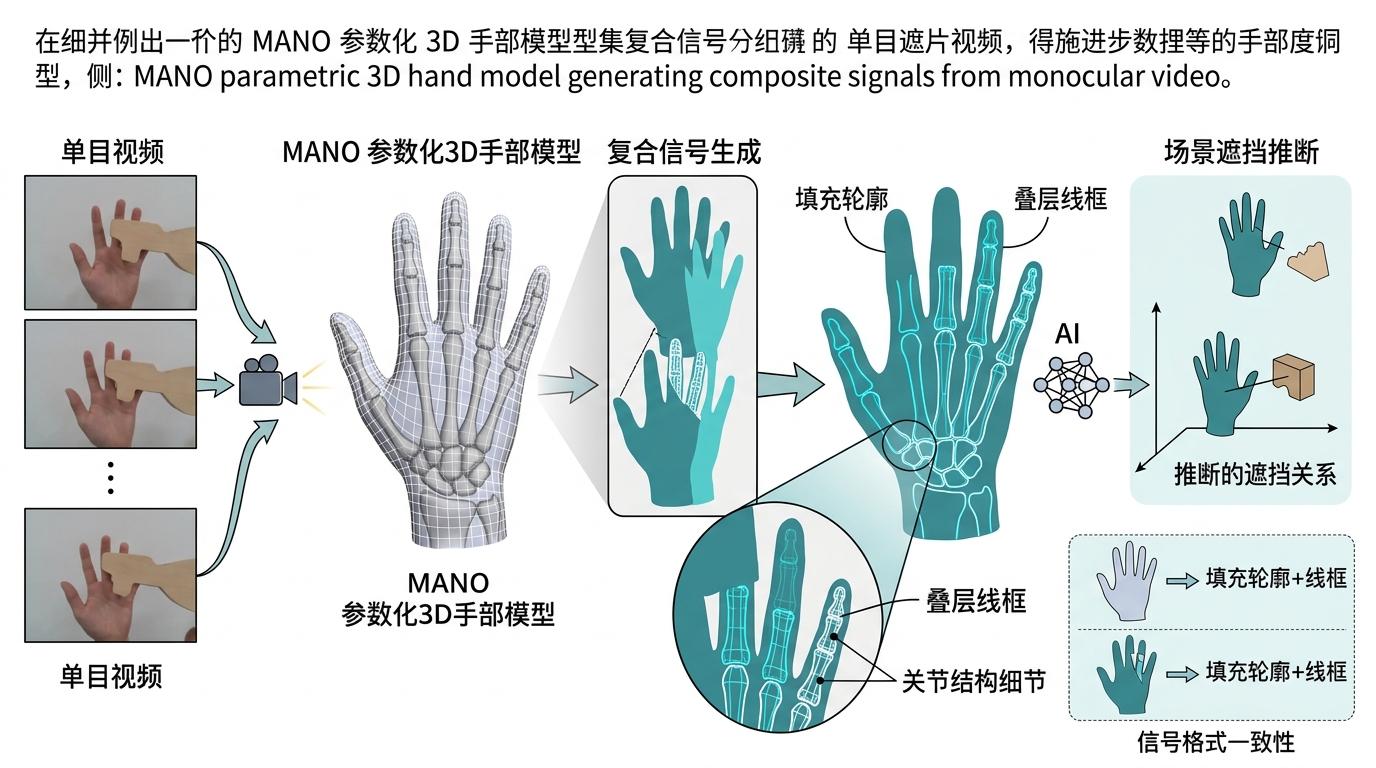
简单说,以前AI只认识“半只手”,现在它终于能看懂“一整只手”的真实姿态了。
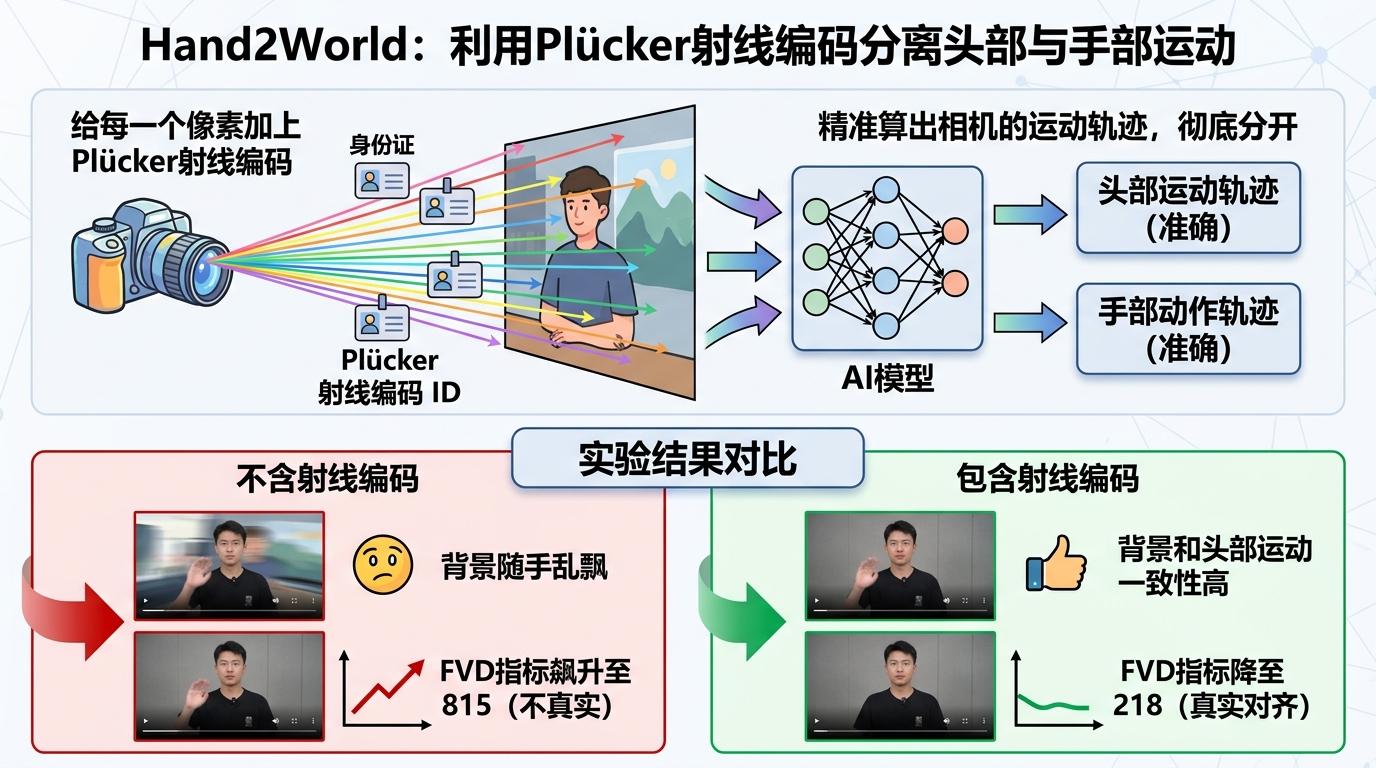
第一人称视角里还有个麻烦:你的头转一下,画面里的手和背景会一起动,AI根本分不清“是我抬手了,还是我低头看手了”。之前的技术要么搞不定这个混淆,要么得用多摄像头同步采集,成本高到没法大规模用。
Hand2World用了个巧办法:给每一个像素都加上Plücker射线编码。你可以把它理解成给每束从相机射向场景的光线都贴了个“身份标签”,AI能通过这些标签精准算出相机的运动轨迹,把头部转动和手部动作彻底分开。实验数据最能说明问题:去掉这个射线编码后,衡量视频真实度的FVD指标从218直接飙到815,背景跟着手一起乱飘;加回去之后,背景和头部运动的一致性立刻和真实视频对齐。
更关键的是,这套系统能用普通单目视频自动标注训练数据——不需要昂贵的多摄像头阵列,也不用人工逐帧标注,只靠YOLO检测手部、HaMeR估计3D参数,再做个时序稳定化处理就行,一下子把训练数据的规模门槛拉低了。
光生成一次画面还不够,真正的交互得是“你动一下,AI跟着变一下”。Hand2World把双向扩散模型蒸馏成了因果自回归生成器,就像写小说一样,逐帧生成后续画面,还能用KV缓存记住之前的场景信息,避免重复计算。
在单卡A100 GPU上,它能跑到8.9帧每秒,基本能跟上你手势调整的速度——你可以先比个抓杯子的动作,看AI生成的画面,觉得角度不对,再调整手势,AI立刻就会生成新的抓取姿势,形成真正的“闭环”。当然它也有局限:生成的视频分辨率还不如传统VR系统,长时间生成会有轻微的画面漂移,要做到视网膜级分辨率和低于20毫秒的延迟,还有不少路要走。
在ARCTIC、HOT3D这些权威数据集上,它的FVD指标比之前的最好方法降了76%,相机轨迹误差降了42%——这些数字背后,是AI第一次能像人一样,用手和虚拟世界持续互动。
从只能“看”的Sora,到能“走”的Genie 3,再到现在能“触碰”的Hand2World,AI世界模型的进化路径,其实一直在复刻人类和世界互动的方式:先用眼睛观察,再用身体移动,最后用手去操控。
这不仅仅是技术的突破,更是人机交互范式的小转折——以前我们是对着屏幕“发号施令”,现在我们可以用最自然的手势,直接“伸进”虚拟世界里。当然,它离真正的“具身智能”还远:现在的AI只是能模拟“伸手”的动作,还没有真实的触觉反馈,也没法像人一样根据触感调整力度。但从“看见”到“触碰”,这一步已经为AI打开了新的门。
从旁观到触碰,AI开始学“做事”了。