对抗知识焦虑,从看懂这条开始
App 下载
给芯片装内置冷却塔,AI算力瓶颈破了
芯片散热|硅基冷却元件|高带宽存储芯片|iHBM技术|SK海力士|先进材料|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载芯片散热|硅基冷却元件|高带宽存储芯片|iHBM技术|SK海力士|先进材料|AI算力|前沿科技|人工智能
当你用AI生成一张4K图片、跑一次大模型推理时,可能不会想到:此刻服务器里的高带宽存储芯片,正被自己的热量困住——就像一个人在密闭房间里全力奔跑,越用力越喘不上气。
2026年5月26日,SK海力士发布的iHBM技术,第一次把“冷却塔”搬进了芯片内部。这项技术在高带宽存储(HBM)的封装里直接嵌入硅基冷却元件,把局部热阻降低了30%,让那些因为过热被迫“降速”的算力,终于能全力奔跑。
但问题是,为什么芯片的热量会成为AI算力的致命瓶颈?这个内置的“冷却塔”,到底是怎么把热量引出去的?
你可以把HBM想象成AI服务器的“超级快递站”:它把几十层DRAM芯片垂直堆叠起来,用硅通孔当“快递通道”,让数据能以TB/s的速度在CPU、GPU和内存之间穿梭——这是AI大模型能快速处理海量数据的关键。
但堆叠结构也埋下了隐患:热量会像被困在高楼里的烟雾,只能从顶层的“窗户”慢慢散出去。尤其是HBM和GPU连接的D2D PHY区域,几千条信号线高速切换,产生的热量像在快递站里点了一堆篝火,而篝火的烟要穿过十几层“楼板”才能排出去。
传统的散热方案,比如在芯片顶部加散热器、用液冷冷板,都像在高楼外面装抽油烟机,能抽走顶层的烟,却管不了底层的篝火。当芯片温度超过95℃的安全线,就会自动降频“喘气”——这就是为什么很多AI服务器明明装了高端GPU,实际算力却只能发挥七八成。
一组数据能直观体现这个瓶颈:12层堆叠的HBM3E,底层芯片的温度比顶层高24℃,3D堆叠在GPU上时,局部温度甚至能冲到140℃,直接触发硬件保护机制。
iHBM技术的核心,就是在HBM的“篝火区”D2D PHY里,直接嵌入了硅基的集成冷却元件(ICE)——你可以把它理解成在篝火旁边直接挖了几条通向楼顶的通风管道,让热量不用再穿过十几层芯片,直接从内部排出去。

这个“通风管道”的设计很巧妙:它用的是电绝缘但热导率极高的硅基材料,既不会干扰芯片的电信号,又能像金属一样快速导走热量。相比传统散热路径,它把局部热阻降低了30%,相当于把烟雾的排出速度提升了近一半。
更关键的是,这个设计完全兼容现有的封装工艺。SK海力士用成熟的MR-MUF技术,把冷却元件和芯片一次性封装在一起,不需要客户改动服务器的设计——这意味着它能快速落地,而不是停留在实验室里的概念。
不过,这项技术也不是没有局限。它解决的是HBM内部的热阻问题,但如果服务器整体的散热系统跟不上,比如还是用传统风冷,顶层的热量依然排不出去。更值得关注的是,它本质上是一种“堵漏洞”的改良,而不是颠覆式的创新——当未来HBM堆叠到16层甚至20层时,可能需要更激进的散热方案,比如直接在芯片里刻微流道通冷却液。
其实,iHBM技术只是AI散热战场的一个缩影。现在的AI芯片,正在经历一场“热量军备竞赛”:GPU的热设计功率从几年前的300W飙升到1400W,未来甚至会突破2000W,传统的风冷已经完全跟不上。
除了内置冷却元件,还有很多玩家在探索不同的路径:Imec通过“系统-技术协同优化”,把3D堆叠HBM-on-GPU的峰值温度从141.7℃降到了70.8℃;微软在芯片背面蚀刻微流道,用冷却液直接带走热量;还有的公司在尝试把整个服务器浸没在绝缘冷却液里,让芯片直接“泡在水里”散热。
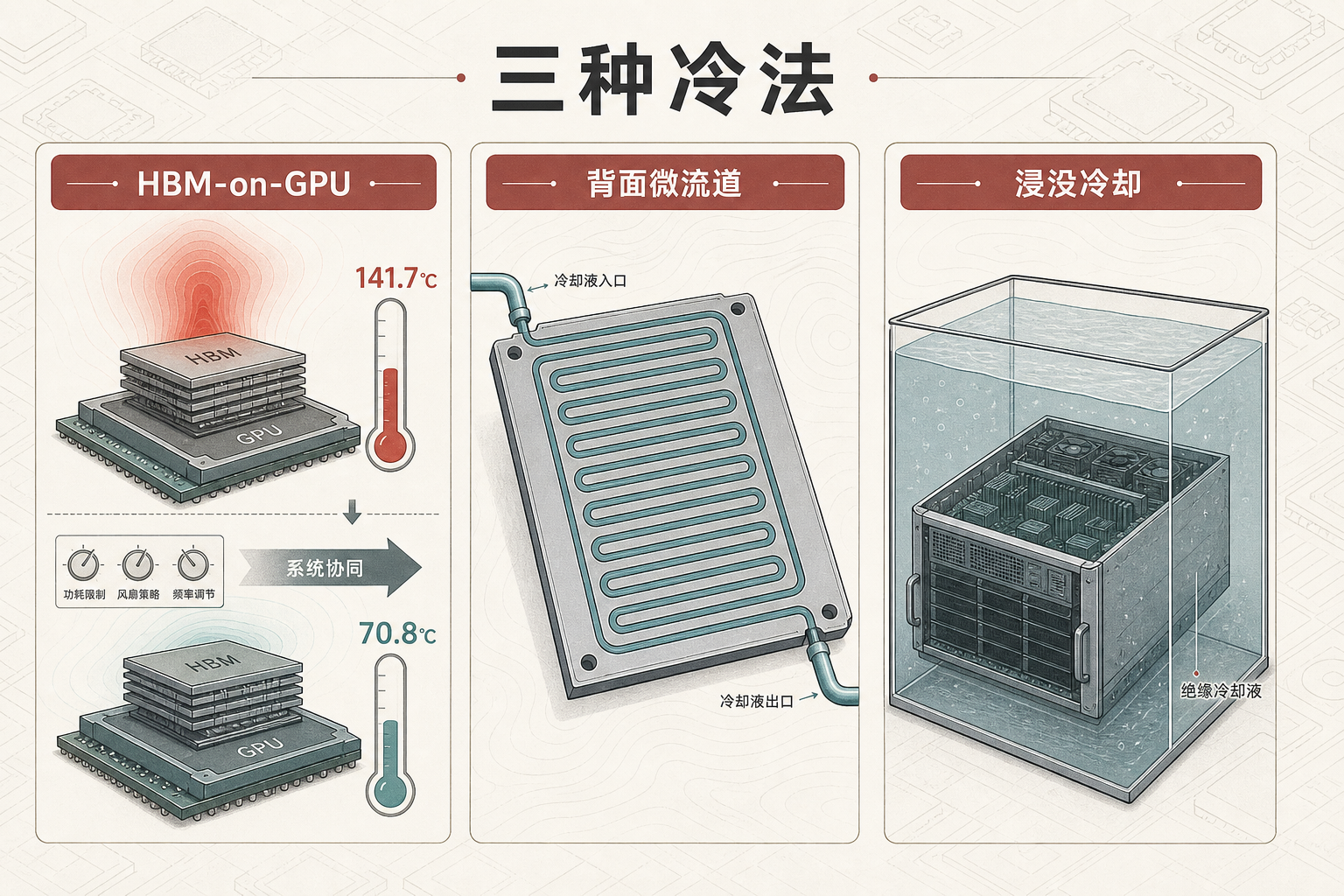
这些技术的本质,都是在和物理规律赛跑——芯片的算力提升越快,产生的热量就越多,散热技术就必须跟上,否则再强的算力都会被热量锁住。而这场竞赛的胜负,直接决定了未来AI能跑多快、能做多大的模型。
当我们为AI大模型的惊艳表现欢呼时,很少有人会注意到这些藏在芯片内部的“冷却塔”“通风管道”。但正是这些看似不起眼的技术突破,才让AI的算力能持续提升。
算力的边界,其实是散热的边界。未来,AI芯片的竞争,会越来越变成散热技术的竞争——谁能把热量更快地排出去,谁就能在AI的赛道上跑得更远。
毕竟,再强大的算力,也敌不过一颗发烫的芯片。