对抗知识焦虑,从看懂这条开始
App 下载
AI能克隆歌手声线,但版权边界已划清
歌手声线复刻|版权争议|声音权属|AI歌声克隆|公共政策|AIGC|社会人文|人工智能
对抗知识焦虑,从看懂这条开始
App 下载歌手声线复刻|版权争议|声音权属|AI歌声克隆|公共政策|AIGC|社会人文|人工智能
戴上耳机,你听到一段带着气口转音、真假声无缝切换的女声翻唱——是那位以细腻唱腔著称的华语歌手终于翻了粉丝点的冷门歌?不对,这是AI生成的。2026年的一项测试显示,80%的普通听众无法稳定区分AI歌声与真人演唱,甚至有AI生成的‘模仿版’在风格相似度投票中超过了原唱片段。当AI能精准复刻人类声带的每一丝颤动,我们的耳朵不再是版权的可靠防线,一场关于声音权属的拉锯战,已经从实验室烧到了法庭。
你可以把AI克隆声音的过程想象成‘偷师学唱戏’——先把目标歌手的所有公开演唱拆成最小的‘零件’:比如转音时的气息变化、拖尾音的颤频、甚至换气前的微小停顿,这些被称为‘声学特征’的细节,会被AI用深度学习模型像拼图一样拆解、存储。
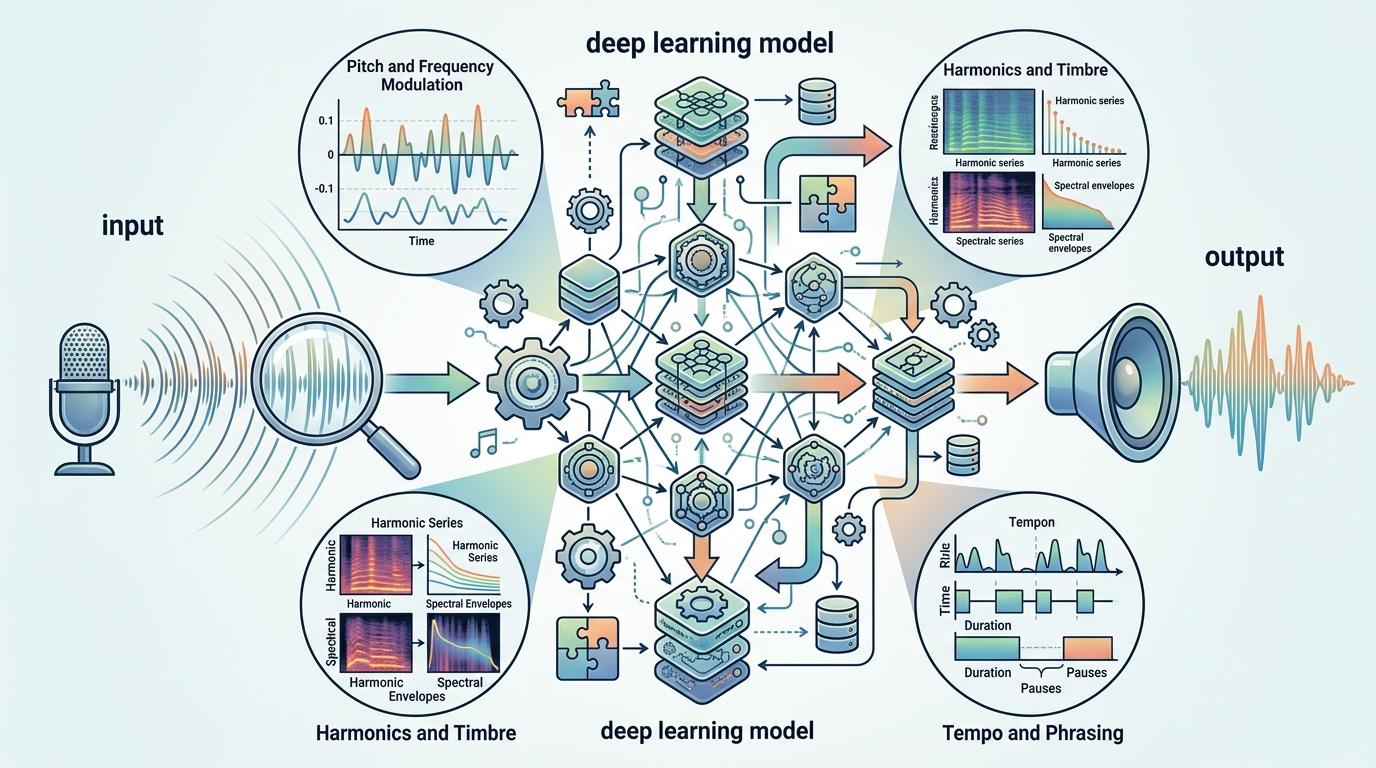
传统的语音合成只能模仿大致音色,而新一代模型靠‘少样本学习’,只需15到30分钟的干净录音,就能精准复刻特定声音的所有细节。它会先提取目标声音的‘声纹指纹’,再用扩散模型生成匹配的频谱图,最后通过神经声码器把频谱图转化为能以假乱真的音频。
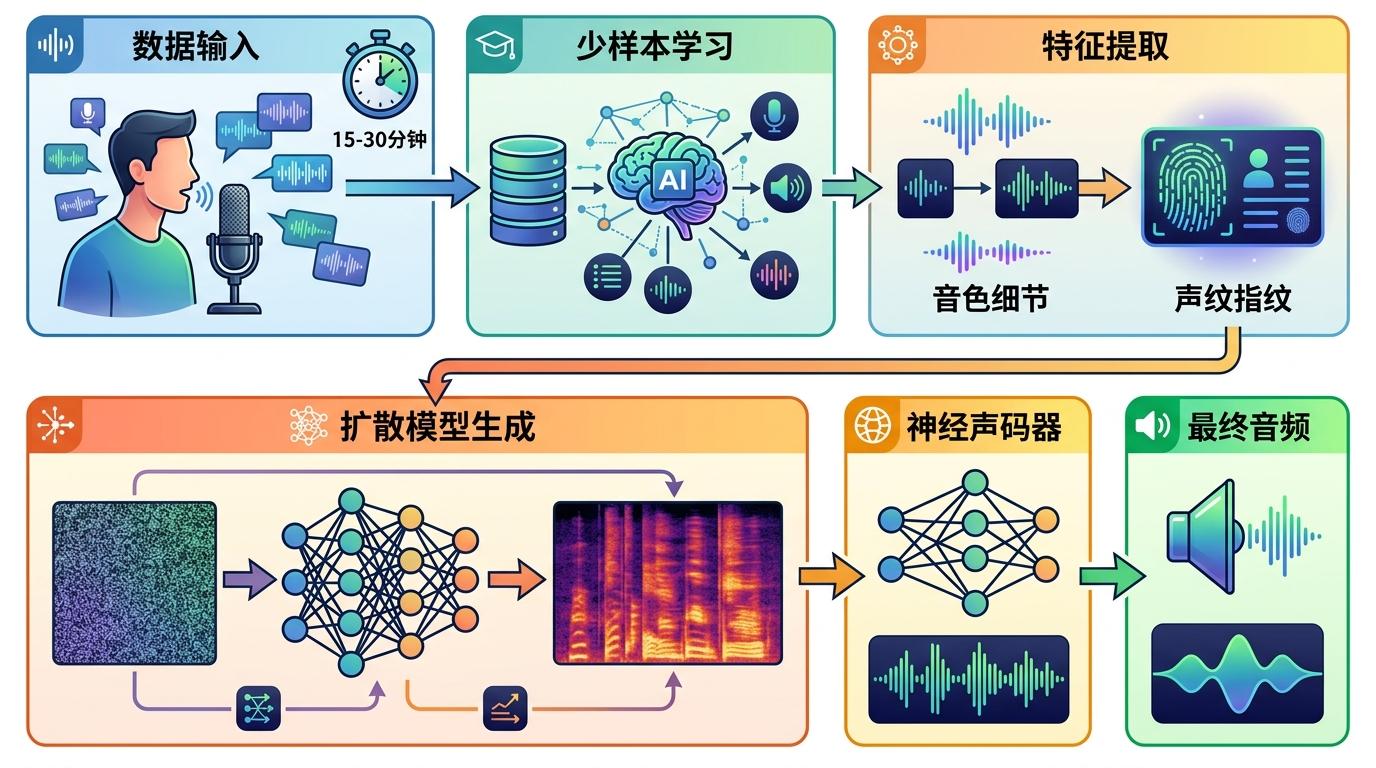
但真实的机制比这个比喻更精确:AI会把声音拆解为‘内容层’和‘风格层’——内容层是歌词和发音逻辑,风格层是独属于某个歌手的音色、节奏和情感处理。训练完成后,它能像换皮肤一样,把任何文本内容套上目标歌手的‘风格外壳’。
2024年,北京互联网法院的一份判决,第一次把AI声音克隆从‘技术擦边球’变成了明确的侵权行为。一位配音演员发现自己的声音被做成AI声音包售卖,法院最终认定:自然人的声音具备唯一性和可识别性,属于人格权保护范畴,未经授权的声线克隆,就是对人格权益的非法剥夺。
这意味着,哪怕你拥有某段录音的著作权,也不能随便把它喂给AI做训练。要使用他人声音进行AI商业化开发,必须拿到‘专项明示授权’——不是模糊的‘同意使用作品’,而是明确写清‘允许用于AI训练、克隆及商业化生成’。
2025年起,监管进一步收紧:AI生成内容必须强制标识,国家版权局要求AI音乐至少包含30%的人类创作成分才能获得版权,区块链存证的创作记录甚至能作为法院采信度超95%的证据。平台开始部署‘AI+区块链’监测系统,把未授权的AI音乐排除在版税池之外。
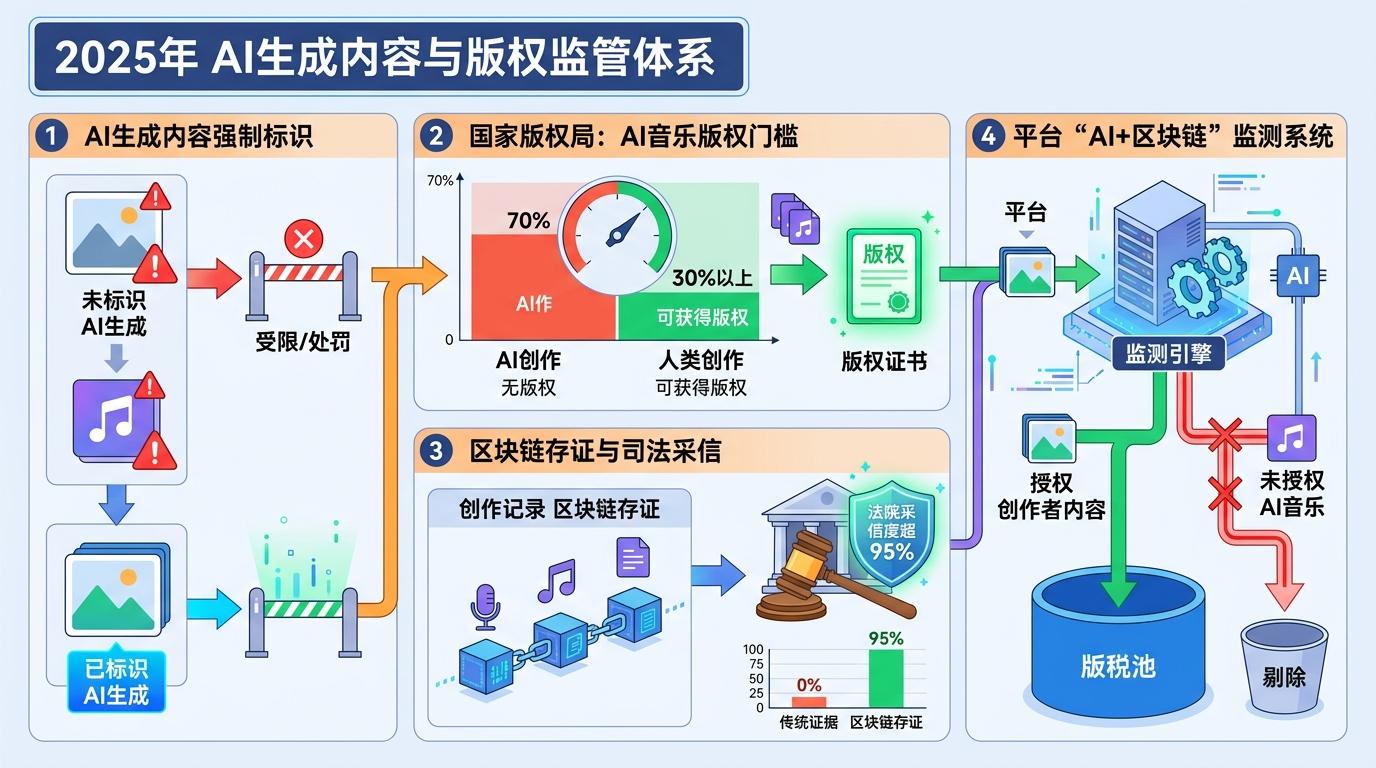
曾经被唱片公司联名抵制的AI音乐平台,如今开始主动转向‘授权模式’。有的平台和三大唱片公司达成协议,让歌手自主选择是否开放声音库给AI使用,用户生成的相关内容会按比例给歌手分红;有的平台干脆直接放弃‘精准克隆’,只借鉴歌手的广义风格,避免触碰人格权红线。
流媒体平台也在行动:Deezer部署的AI内容识别系统,能把85%的欺诈性AI流量排除在版税池外;有的平台要求创作者必须上传完整的创作流程记录,证明自己在AI生成的基础上做了足够的二次创作。
更值得关注的是,这种转变不是被动的合规,而是开辟了新的收入渠道——有的歌手授权AI复刻自己的声音,粉丝可以用AI和‘虚拟歌手’互动生成定制歌曲,歌手能从中获得分成,反而拓展了盈利边界。
当AI能复刻人类的每一丝唱腔,我们终于明白:技术的边界从来不是由机器的能力定义,而是由人类对创作价值的共识划定。AI可以是创作的放大器,却不能成为版权的收割机。
技术迭代的速度永远快于规则,但每一次争议、每一份判决、每一个行业协议,都是在为技术划出不伤害创造力的安全区。技术是工具,而创作的灵魂永远属于人。未来的音乐世界,不该是AI取代人类,而是人和AI各擅其场——AI负责复刻细节,人类负责注入只有生命才能理解的情感。