对抗知识焦虑,从看懂这条开始
App 下载
少花90%钱,AI多模型协作反而更强
模型路由|算力成本|上海交通大学|RouteMoA系统|多模型协作|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型路由|算力成本|上海交通大学|RouteMoA系统|多模型协作|大语言模型|人工智能
当你问AI一道复杂的数学题,背后可能同时跑着十几个大模型——有的算微积分,有的理逻辑,有的查公式,最后再把答案拼起来。这种叫「多模型协作(MoA)」的玩法,能拼出比单个大模型更准的结果,但代价也惊人:每轮调用都要烧一遍所有模型的算力,成本和延迟跟着模型数量疯涨。
直到上海交大的团队拿出了一个反常识的方案:不用让所有模型先做题,提前就能知道谁最擅长这道题。他们的RouteMoA系统,在15个模型的测试池里砍了89.8%的成本,延迟降了63.6%,准确率还比传统方案高了10%。这不是简单的优化,而是给AI协作换了一套新逻辑。
你可以把传统多模型协作想象成一场无差别考试:不管题目是数学还是写诗,都要让所有模型答一遍,再找个「评审模型」打分筛选。哪怕最后只留3个模型的答案,前面12个的算力也已经烧完了——就像为了选3个短跑选手,先让100个人跑完全程再挑。

RouteMoA把这个流程彻底倒了过来:它先给用户的问题做个「画像」,比如这是道高中几何题,需要空间推理和公式应用能力,再用一个轻量级的「评分器」,快速扫描模型池里每个模型的专长——谁最擅长几何,谁对空间题一塌糊涂,直接把后者排除在答题名单外。
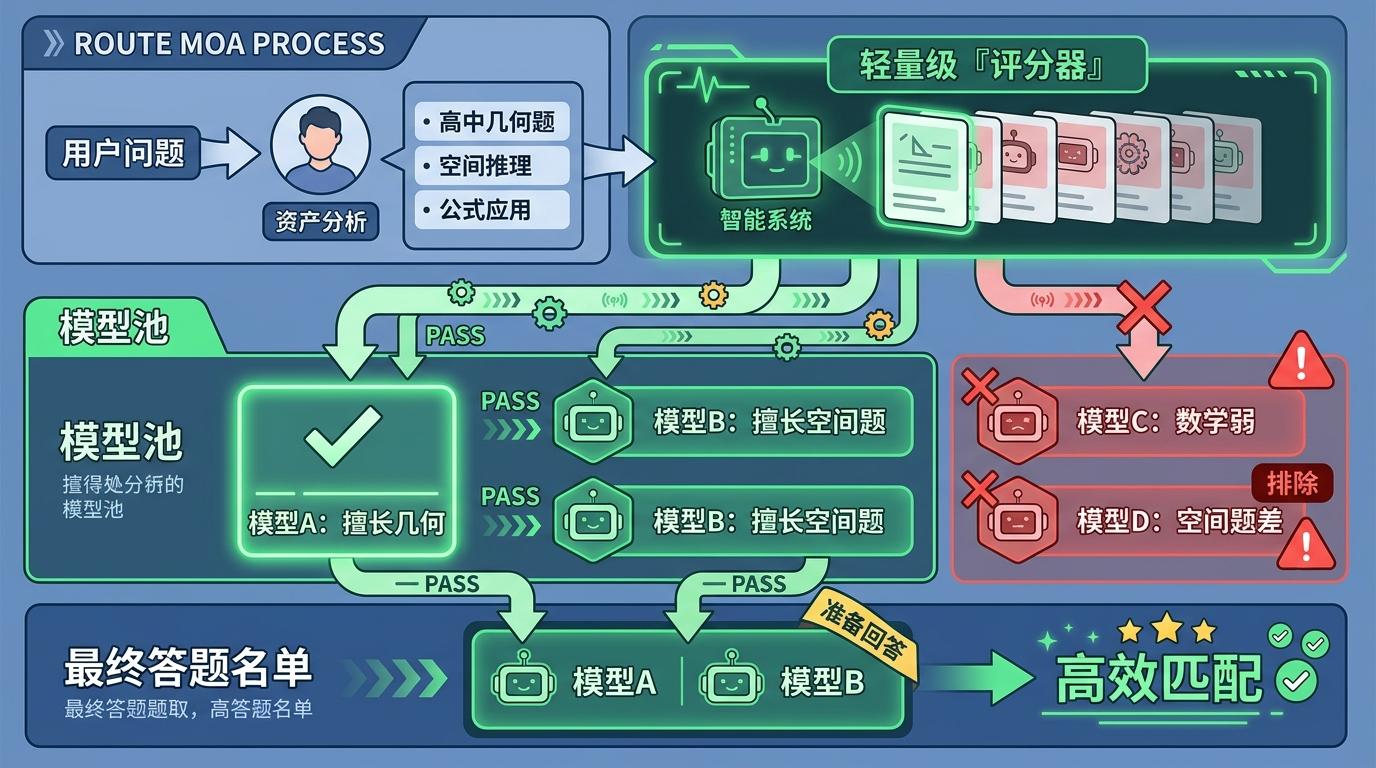
这个评分器不需要模型真的答题,只靠问题本身的特征和模型的过往表现数据就能打分,相当于看简历选人,不用先让所有人试岗。实验里这个「简历筛选」的准确率高得惊人:Top-3命中率达到98%,几乎不会漏掉真正能解题的模型。
当然,只看「简历」难免有误差——比如某个模型平时几何题答得好,但刚好对这道题的题型不熟悉。RouteMoA加了一道低成本的「补漏程序」:让初选出来的几个模型先答出简短的思路,再做两件事:
一是「自评」,每个模型给自己的思路打个分,比如「我对这道题的解法有80%把握」;二是「交叉评审」,让平时表现最稳定的几个模型,给其他模型的思路挑错。关键是,这些评审都不用额外调用模型算力,只基于已经生成的简短思路就行——就像让候选人先讲30秒解题思路,再互相点评,不用真的写完整个解题过程。
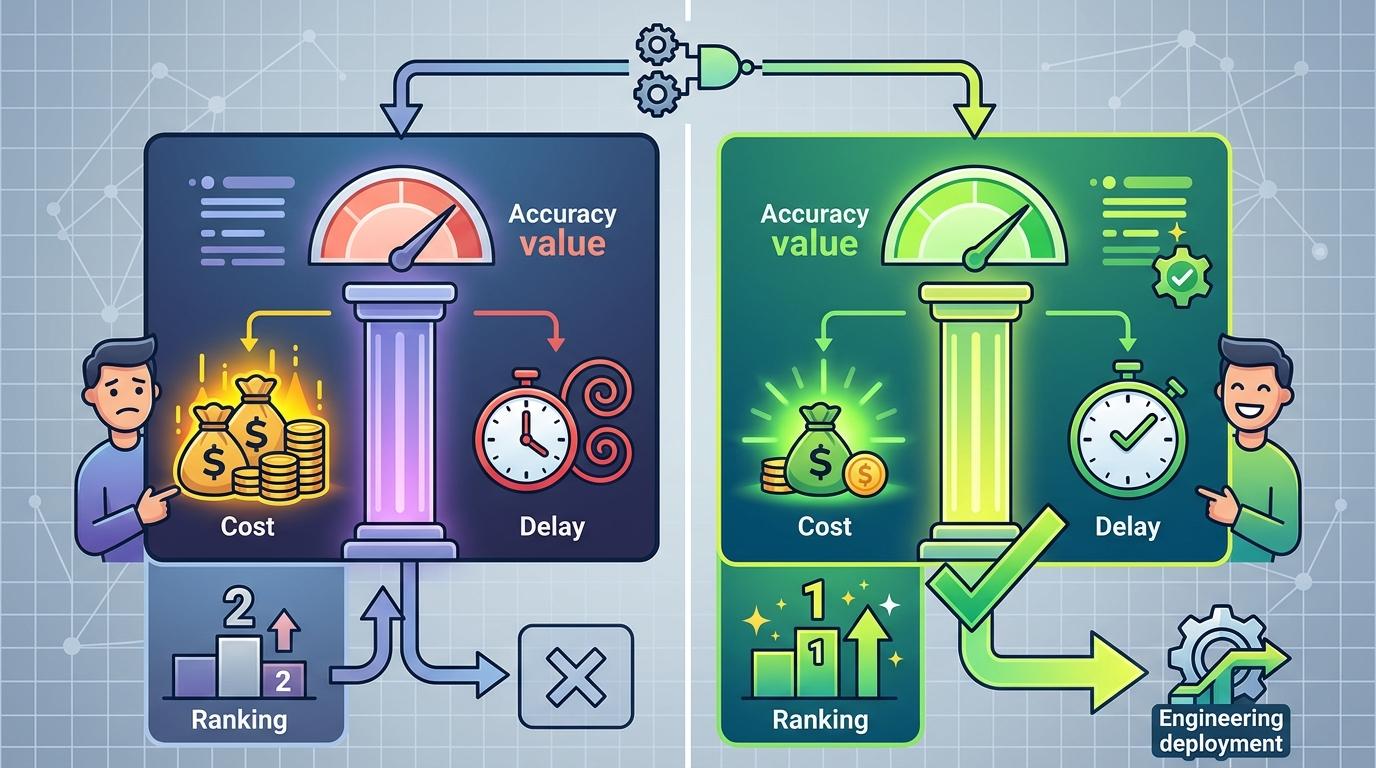
最后一步才是综合排序:不光看谁的准确率高,还要算调用这个模型要花多少token、延迟有多久。比如有两个模型准确率差不多,一个要花10块钱延迟2秒,另一个花1块钱延迟0.5秒,系统会直接选后者。这种「性能-成本-延迟」的三维排序,才是真正适合工程落地的选择。
实验数据里藏着一个更重要的信号:RouteMoA的失败案例中,超过50%的错误不是因为选错了模型,而是因为最后把几个模型的答案拼错了——比如把A模型的解题步骤和B模型的结论硬凑在一起,逻辑链断了。
这意味着,多模型协作的瓶颈已经从「怎么选模型」转移到了「怎么融合答案」。过去大家都在想怎么让模型更高效地干活,现在发现,把不同模型的输出揉成一个通顺、准确的答案,难度不比选模型小。
团队在论文里提到,他们下一步的研究重点就是答案融合——比如让模型在答题时同步输出「解题逻辑链」,而不只是最终答案,这样融合时就能顺着逻辑链拼接,而不是简单地把句子粘在一起。这也给整个行业提了个醒:AI协作的下一个战场,不是模型数量,而是协作的「粘合剂」。
当我们还在惊叹单个大模型的能力边界时,多模型协作已经悄悄从「堆数量」转向了「拼效率」。RouteMoA的意义,不只是砍了多少成本,而是证明了一件事:AI的未来不是比谁的模型更大,而是比谁能把不同模型的能力用得更聪明。
「精准协作,比全员参战更有力量」——这句话不仅适用于AI,也适用于所有需要分工的复杂系统。毕竟,真正的高效从来不是所有人都动起来,而是让对的人在对的时间做对的事。