
11 天前
11 天前
当你刷到AI生成的逼真画作、和ChatGPT流畅对话时,可能不会想到,支撑这些奇迹的技术,至今还像个靠经验凑出来的“土作坊”。大模型训练动辄烧掉上千万电费,调参全靠工程师“凭感觉试”;AI能赢围棋冠军,却没人能说清它到底怎么想的。2026年4月,中科院院士鄂维南在一场论坛上抛出了振聋发聩的判断:AI不能再靠“瞎蒙”往前走了——它得变成一门真正的科学。而这一切的起点,是解决几个困扰数学家几十年的难题。
你可以把传统算法想象成一群在黑屋里摸大象的盲人:摸到腿说是柱子,摸到耳朵说是扇子,永远拼不出完整的象。这就是“维数灾难”——当问题的维度超过两位数,比如一张32×32的彩色图片有3072个像素维度,传统数学方法就会彻底失效:计算量会像爆炸一样指数级增长,再多的算力也填不满这个窟窿。
但深度学习打破了这个魔咒。1993年数学家Andrew Barron提出的Barron空间理论证明,只要函数满足特定的傅里叶谱性质,两层神经网络就能用和维度无关的误差逼近它——就像给盲人每人配了个对讲机,他们能把摸到的局部信息拼出完整的大象。蒙特卡洛积分的思路更直白:把高维函数逼近转化为随机采样的积分,就像用撒豆子的方法算圆面积,豆子撒得越多,结果越准,和圆的大小(维度)没关系。
这不是玄学,是硬邦邦的数学:深度学习的逼近误差只和网络宽度成正比,和维度无关。这就是AI能处理图像、语言等高维问题的核心原因。
解决了维数灾难,AI又遇到了新的坎:“深度灾难”。就像传话游戏,一句话经过十个人就会变味,深度学习的梯度信号在经过几十层网络后,要么衰减到消失,要么膨胀到爆炸,导致深层网络根本训不动。
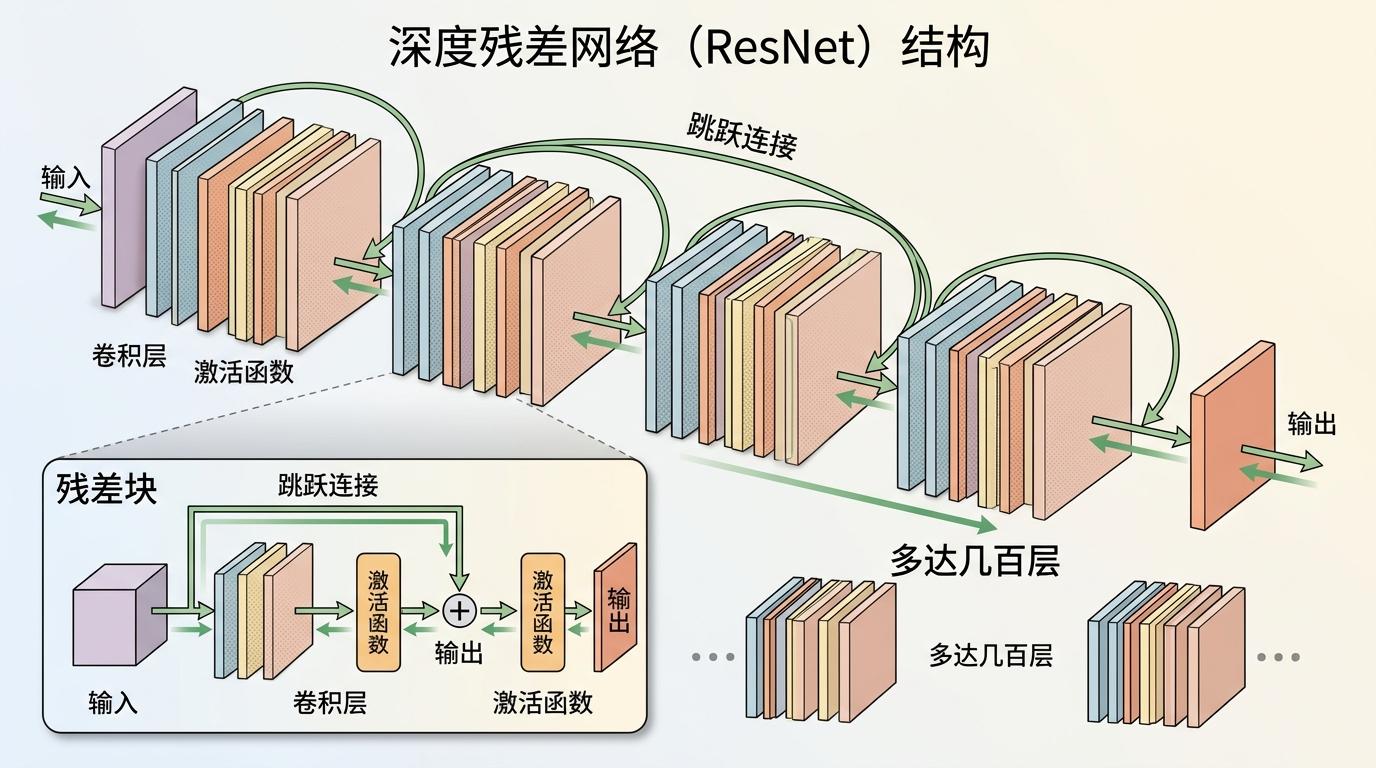
2015年残差网络(ResNet)的出现,给梯度开了个“绿色通道”:它不直接学输入到输出的完整映射,而是学输入和输出的“残差”——就像你不用记住整本书,只需要记住和上一版的区别。恒等映射的跳跃连接让梯度能直接从输出层传到输入层,彻底解决了梯度消失的问题。现在,几百层的神经网络能像搭积木一样轻松训练。
另一道坎是“记忆灾难”:循环神经网络(RNN)处理长文本时,就像鱼只有7秒记忆,前面的信息走着走着就丢了。Transformer的自注意力机制则像给每个词配了个放大镜,能直接看到整个文本里的所有词,不管隔了多少行。它的计算复杂度和序列长度的平方成正比,而RNN是线性的——这意味着Transformer能轻松处理几万字的长文本,而RNN连几千字都费劲。
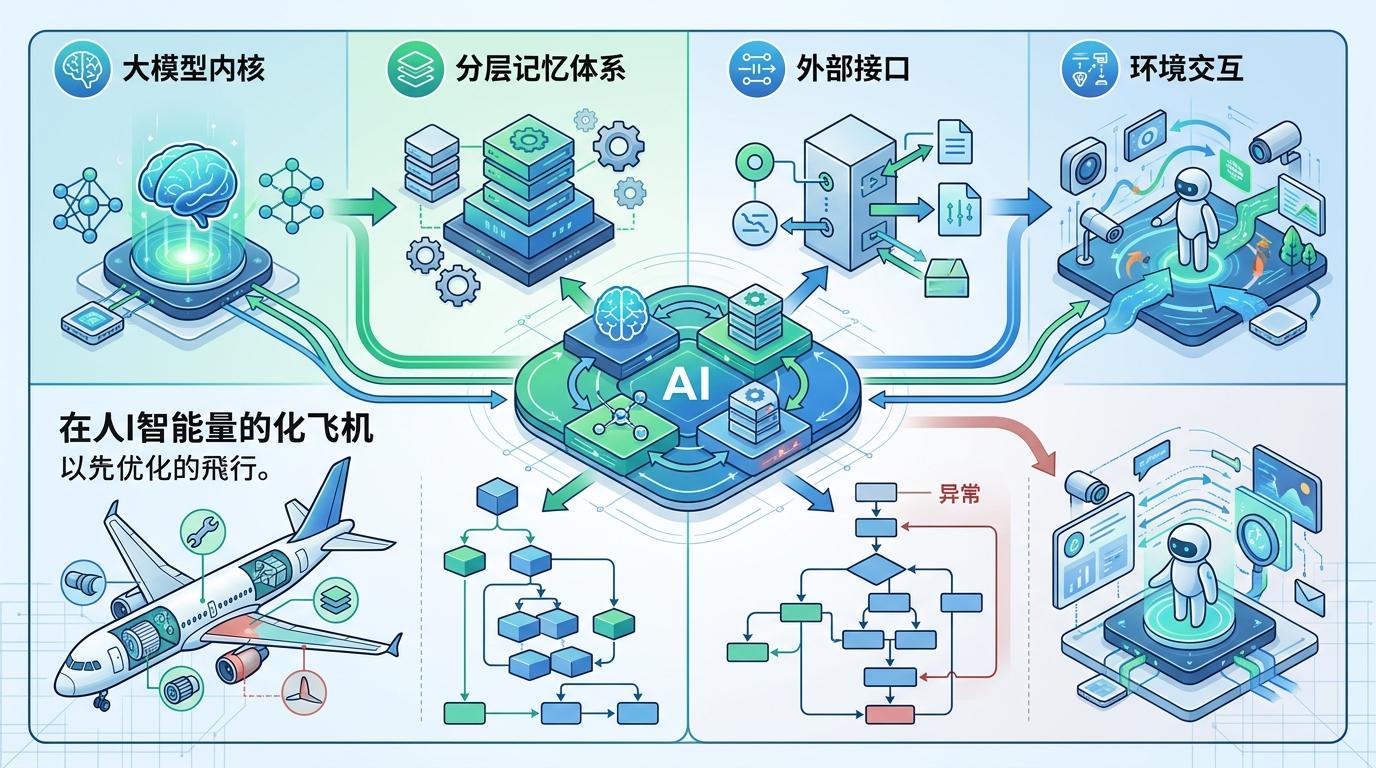
当单个算法的理论基础逐渐清晰,科学家开始把AI当成一个复杂系统来看待。就像一架飞机,不能只优化发动机,还要考虑机翼、尾翼和控制系统的协同。AI系统也一样,它包括大模型内核、分层记忆体系、外部接口和环境交互四个部分。
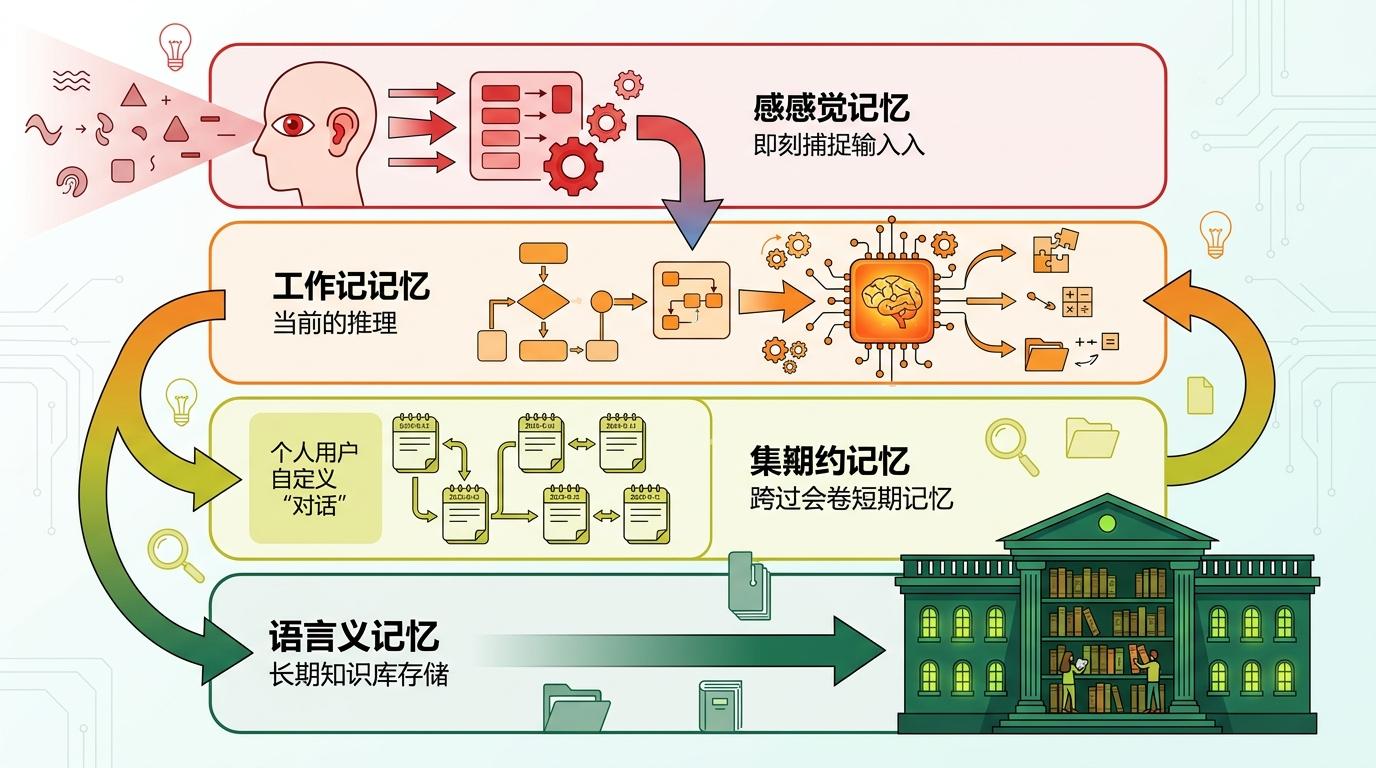
比如“忆立方”模型,它把AI的记忆分成了四层:感官记忆负责即时捕获输入,工作记忆负责当前推理,情景记忆负责跨会话的短期记忆,语义记忆负责长期存储知识库。这种分层设计解决了传统AI“记不住事”的问题——就像你大脑里的临时记事本和永久藏书阁,各司其职。
AlphaGeometry则是神经符号混合系统的典范:大模型负责猜辅助线怎么画,符号引擎负责用几何定理严格证明。这种“AI找思路,人类讲逻辑”的协作模式,让AI能解出国际数学奥林匹克竞赛的几何题,性能接近人类金牌选手。
但AI的科学化还有很长的路要走:我们还不知道深度学习的泛化能力到底来自哪里,非结构化数据的建模还没有统一框架,AI的创造力还远不如人类的工程直觉。
从AlphaFold预测蛋白质结构,到DeePMD实现量子精度的分子模拟,AI正在从“经验工具”变成“科学方法”。它不再是黑箱里的魔法,而是有数学理论支撑、有系统框架约束的科学体系。
“AI的科学化,是从‘试错’到‘理解’的跨越。”这不仅是技术的进步,更是人类认知的升级。当我们能真正理解AI为什么能行,我们才能让它更可靠、更安全、更能解决人类面临的复杂问题——从气候变化到疾病治疗,从新材料研发到深空探测。AI的未来,不是让它变成另一个人类,而是让它成为人类探索未知的最强大工具。
点击充电,成为大圆镜下一个视频选题!