对抗知识焦虑,从看懂这条开始
App 下载
AI智能上限,竟由环境开放程度决定
自主学习能力|马尔可夫决策过程|环境开放程度|王子涵|DeepSeek V4|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自主学习能力|马尔可夫决策过程|环境开放程度|王子涵|DeepSeek V4|AI智能体|人工智能
当我们还在为「GPT-6要堆多少参数」「下一个模型要烧多少GPU」争论不休时,一群研究者已经悄悄换了赛道。2026年4月,DeepSeek发布V4大模型的同时,青年研究者王子涵抛出了一个反常识结论:AI Agent的智能上限,从来不是由算力或数据规模决定的——而是由它所处环境的开放程度。这意味着,给AI一个封闭的聊天框,它永远只是个对话工具;但给它一个能自由探索、试错、获取反馈的开放环境,它才有可能演化出真正的自主学习能力。我们一直找错了AI进化的钥匙。
要理解环境的重要性,得先搞懂AI Agent的决策底层逻辑——马尔可夫决策过程(MDP)。你可以把它想象成一场有规则的游戏:Agent是玩家,环境是游戏地图,状态是玩家当前的位置,动作是玩家能走的方向,奖励是走到终点的得分。Agent的目标,就是通过一次次试错,找到能拿到最多奖励的行动路线。
但真实世界的「游戏」比这复杂得多。在封闭环境里,比如下围棋,所有规则都是固定的,AI只要靠算力穷举就能赢;可在开放环境里,比如让AI管理企业供应链,规则会随市场波动,状态会被突发状况打乱,奖励也不是明确的「得分」——这时候,算力再强也没用,AI必须学会在不确定中自主调整策略。
王子涵团队的实验印证了这一点:当把同一个Agent放进不同开放度的环境,它的智能表现天差地别。在开放的多Agent协作环境里,Agent会自发学会共享工具、分工任务;可一旦把环境封闭成单一任务模式,它立刻退化成只会执行指令的「工具人」。
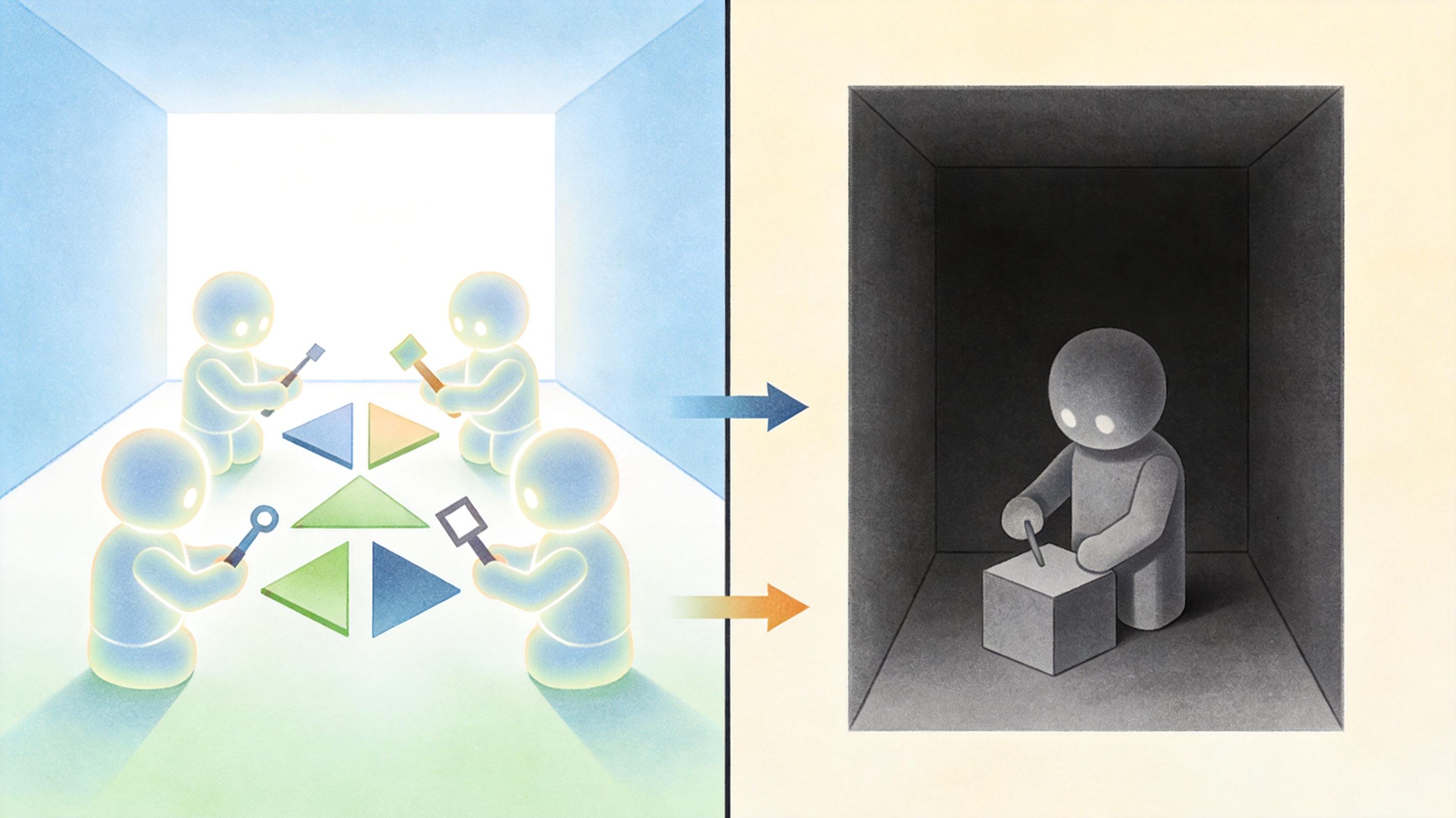
AI要实现自主学习,核心是「试错-反馈-调整」的闭环。但在现实中,这个闭环常常被环境打断——要么反馈信号太弱,要么环境太复杂导致试错成本太高。
王子涵团队在研究多轮强化学习时发现了一个诡异的现象:训练时间越长,AI的推理能力反而越差。他们用信息论拆解后才明白,这是「推理坍缩」在作祟:当环境的奖励信号方差太低,AI的梯度更新会被噪声淹没,最后不管输入什么,它都只会输出一套固定的模板化推理链。就像一个学生,不管老师出什么题,都只会背同一篇范文。
为了破解这个问题,他们提出了「信噪比感知过滤」机制——只保留那些奖励方差高、能给AI带来有效反馈的训练样本。实验显示,用这种方法训练的Agent,泛化能力提升了30%以上。这背后的逻辑很简单:只有在充满不确定性的开放环境里,AI才能获得真正有价值的学习信号。
当AI Agent从实验室走进真实世界,环境的开放性就成了落地的最大挑战。比如O2 AI团队正在研发的企业供应链Agent,它需要对接真实的业务API、处理动态的库存数据、应对突发的物流延误——这些都是实验室里完全模拟不出来的开放场景。

传统的AI模型在实验室里能拿到90%以上的准确率,但一到真实环境就「水土不服」,根本原因就是训练环境和真实环境的「分布偏移」。王子涵团队做过一个对比:在封闭的Grid Game环境里,AI的任务完成率能达到85%;可一旦把环境改成接近真实供应链的动态场景,完成率立刻跌到20%以下。

这也解释了为什么现在很多AI Agent看起来很厉害,却只能处理一些简单任务——它们从来没在真正开放的环境里练过。要让AI真正走进真实世界,我们要做的不是继续堆参数,而是给它打造一个足够复杂、足够开放的训练环境。
我们曾经以为,AI的进化是一条线性的赛道:算力越来越强,参数越来越多,智能就会越来越高。但王子涵等研究者的发现,把这条赛道彻底掰弯了。
AI的智能上限,从来不是由硬件决定的,而是由它能接触到的世界的广度和深度决定的。就像人类的智慧,从来不是从书本里堆出来的,而是在与真实世界的交互中慢慢演化出来的。
环境开放一寸,智能进化一丈。这或许才是AI真正的进化密码。