对抗知识焦虑,从看懂这条开始
App 下载
仿真高分的机器人,到现实中却连杯子都拿不稳
物理世界适应性|四维扰动轴|RADAR评测|现实鸿沟|仿真机器人|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载物理世界适应性|四维扰动轴|RADAR评测|现实鸿沟|仿真机器人|具身智能|人工智能
你可能没注意到,现在的机器人已经能在虚拟实验室里完美完成叠衣服、摆积木这类复杂任务,甚至能在各类仿真评测里拿到接近满分的成绩。但把它们放到真实的客厅里,仅仅是光照暗一点、桌子上的杯子换了个位置,或是摄像头沾了点灰尘,这些「优等生」就会瞬间手足无措——要么抓空杯子,要么把积木碰倒在地。
这就是困扰具身智能领域多年的「现实鸿沟」:模型在仿真环境里的表现越亮眼,放到真实物理世界里就越拉胯。直到RADAR评测基准的出现,才第一次把这个鸿沟的真相,赤裸裸地摆在了研究者面前。
要理解RADAR的价值,得先明白传统评测的问题出在哪——它们把真实世界简化成了一个「无菌实验室」:永远不变的物体位置、固定的光照、零噪声的传感器,连机器人的初始姿态都被精准校准。在这种环境里训练出的模型,就像只会在恒温无菌箱里生长的娇弱菌株,一接触真实世界的「细菌」就迅速失活。
RADAR的第一个核心突破,就是用「四维物理扰动轴」给这个无菌箱开了个口子。你可以把它想象成四个调节真实世界复杂度的旋钮:第一个旋钮调物体位置和机器人初始姿态,第二个调光照亮度和角度,第三个调传感器的噪声强度,第四个调物体的摆放组合。每拧动一个旋钮,评测环境就更接近真实场景一分。
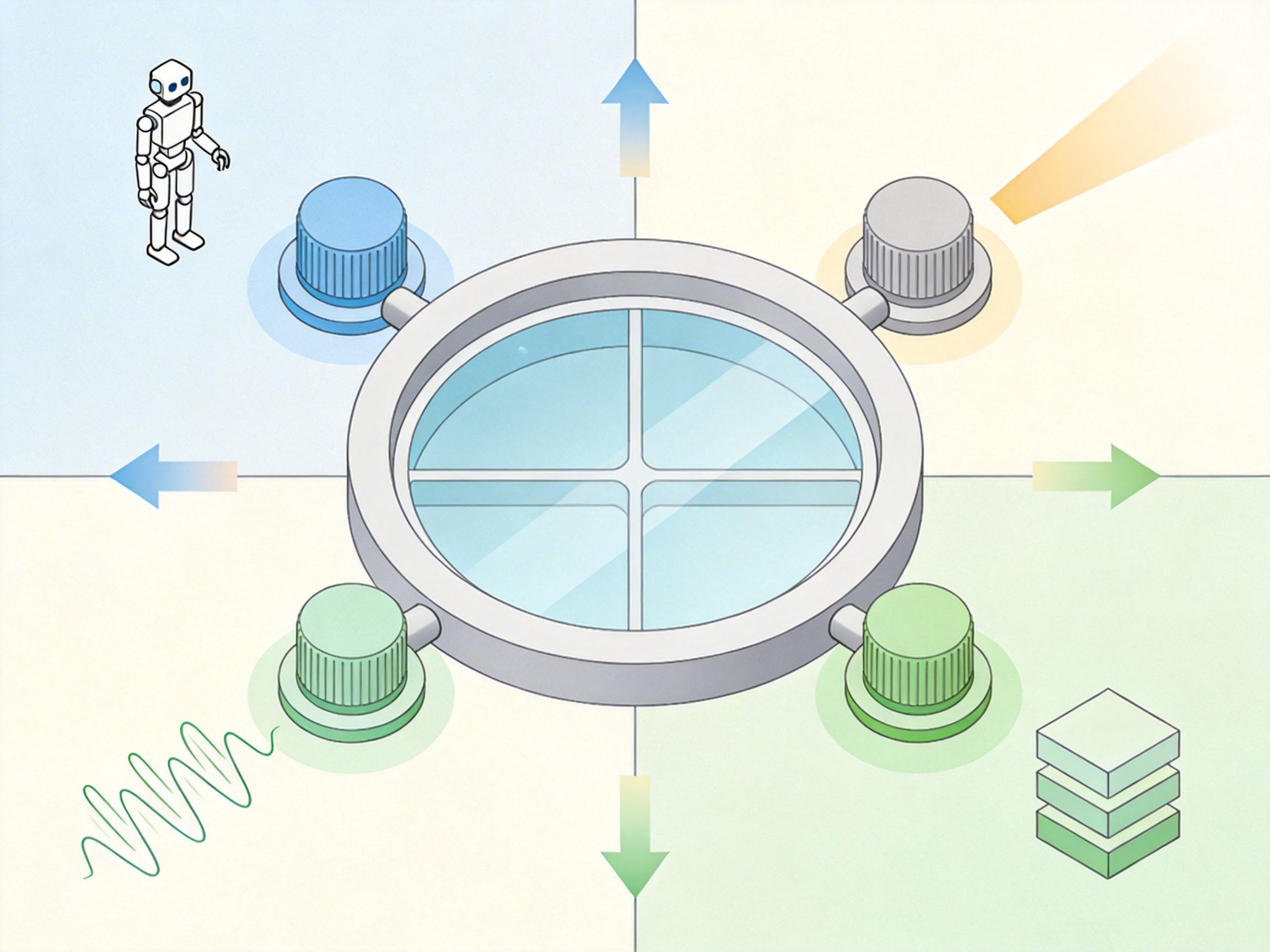
最震撼的实验结果来自传感器噪声测试:当把常见的图像噪声加入测试后,主流模型的3D空间定位准确率(3D IoU)直接从0.261暴跌到0.068——相当于从能大致摸到杯子,变成连杯子在哪都找不到。这个数据像一盆冷水,浇醒了沉迷仿真高分的研究者们:我们的模型,根本没准备好面对真实世界的混乱。
除了真实世界的动态混乱,传统评测还有一个致命缺陷:把机器人的智能简化成了「重复动作执行者」。比如让机器人反复抓取同一个位置的杯子,或是把积木放到固定的凹槽里——这类任务不需要思考,只要把动作练熟就能拿高分,但完全测不出机器人对空间和物理规则的理解能力。
RADAR专门设计了一套「空间推理任务」,相当于给机器人出了一套几何考试卷。比如要求机器人「把红色杯子放到蓝色盒子的左边」,或是「从桌子底下把球推出来」。这些任务的核心不是动作本身,而是理解物体间的相对位置、空间结构,甚至是物理碰撞的规则。
测试结果同样不容乐观:大部分主流模型在这类任务上的成功率不到30%,有的甚至完全无法理解「左边」「底下」这类空间概念。这暴露了一个更深层的问题:我们的AI能识别物体,能执行指令,但根本「看不见」空间的结构——它们就像一群只会死记硬背的学生,换个题型就彻底懵了。
更值得关注的是,这种空间智能的缺失,恰恰是机器人走进真实家庭、工厂的最大障碍。毕竟真实世界里,没有哪个杯子会永远待在同一个位置,也没有哪个任务会给你重复练习的机会。
传统评测的第三个痛点,是依赖人工监督或简单的2D指标,不仅成本高,还充满主观偏差。比如让研究员盯着机器人的动作打分,或是用2D图像里的重叠度来判断抓取是否成功——这些方法要么受限于人的精力和判断,要么无法反映真实的3D空间效果。
RADAR的解决方案是一套全自动化的3D评测流程:用双RGBD摄像头捕捉真实的3D空间信息,通过AI自动完成语义分割、3D重建和指标计算,全程不需要人工干预。这套系统就像一个精准的裁判,能客观测量机器人的每一个动作在3D空间里的误差,比如抓取位置的偏移量、物体摆放的角度误差。
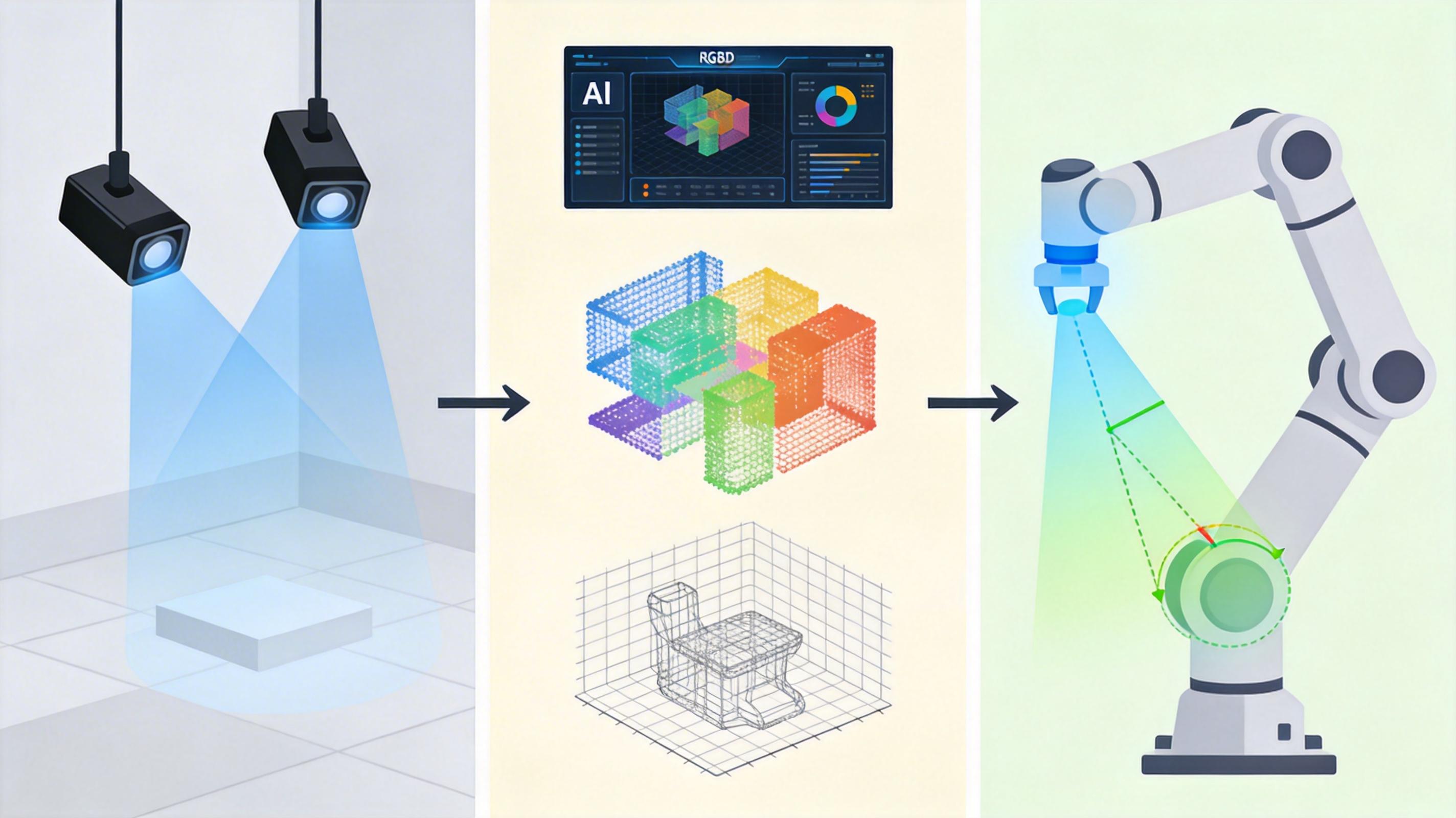
它的优势不止于客观:轻量化的AI模型支持批量测试,能在短时间内完成上百次不同场景的评测,成本只有传统人工评测的十分之一;标准化的流程也让评测结果完全可复现,不同实验室的模型终于能在同一个公平的赛道上比拼。
当然,RADAR也并非完美。目前它的物理扰动还主要集中在刚体和常见环境变量,对于柔体、流体这类更复杂的物理交互,还需要进一步完善。但它至少给具身智能领域指明了方向:与其在仿真里刷高分,不如先学会在真实世界里站稳脚跟。
当我们谈论具身智能时,我们真正想要的不是一个能在虚拟世界里表演的「演员」,而是一个能在真实世界里干活的「工人」。RADAR的意义,就是把研究者的注意力从「如何刷更高的仿真分数」,拉回「如何让AI适应真实世界」这个核心问题上。
它用冰冷的数据告诉我们:智能的本质,从来不是在理想环境里的完美表现,而是在混乱世界里的生存能力。未来的机器人,不需要在仿真评测里拿满分,只需要能在你的客厅里,稳稳地拿起那个换了位置的杯子——这才是具身智能真正的「落地」。
智能的终极考场,永远是真实世界。