对抗知识焦虑,从看懂这条开始
App 下载
6B小模型逆袭大模型,靠的是这三件事
Nano Banana 2|技能库|分层记忆|多智能体协作|上海人工智能实验室|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Nano Banana 2|技能库|分层记忆|多智能体协作|上海人工智能实验室|多模态视觉|人工智能
当大家还在比拼模型参数谁更大时,上海人工智能实验室联合南大、港中文、上交大的团队,干了件反常识的事:给一个只有60亿参数的小模型,装上了一套「多智能体协作+分层记忆+技能库」的组合拳,结果居然在多模态生成的部分任务上,超过了顶尖闭源模型Nano Banana 2。
这不是简单的模型升级,而是给AI换了一套「工作方式」——不再让单个模型硬扛所有任务,而是让一群小智能体分工协作,还能像人一样积累经验、调用技能。为什么这套组合拳能让小模型爆发大能量?这背后藏着多模态生成领域的一个关键转向。
你可以把传统的多模态生成模型想象成一个单打独斗的全能选手,不管是理解复杂指令、生成图像,还是检查结果,全靠自己一个人扛,遇到复杂任务很容易顾此失彼。而GEMS框架里的Agent Loop,相当于给AI搭了个结构化的「项目班子」:
有专门做规划的智能体,把用户的复杂指令拆成一个个可执行的小任务;有负责生成的智能体,专注输出图像内容;还有专门的验证智能体,像个严格的质检员,每一轮生成后都对照要求挑毛病;最后是优化智能体,根据反馈调整下一次的生成方向。
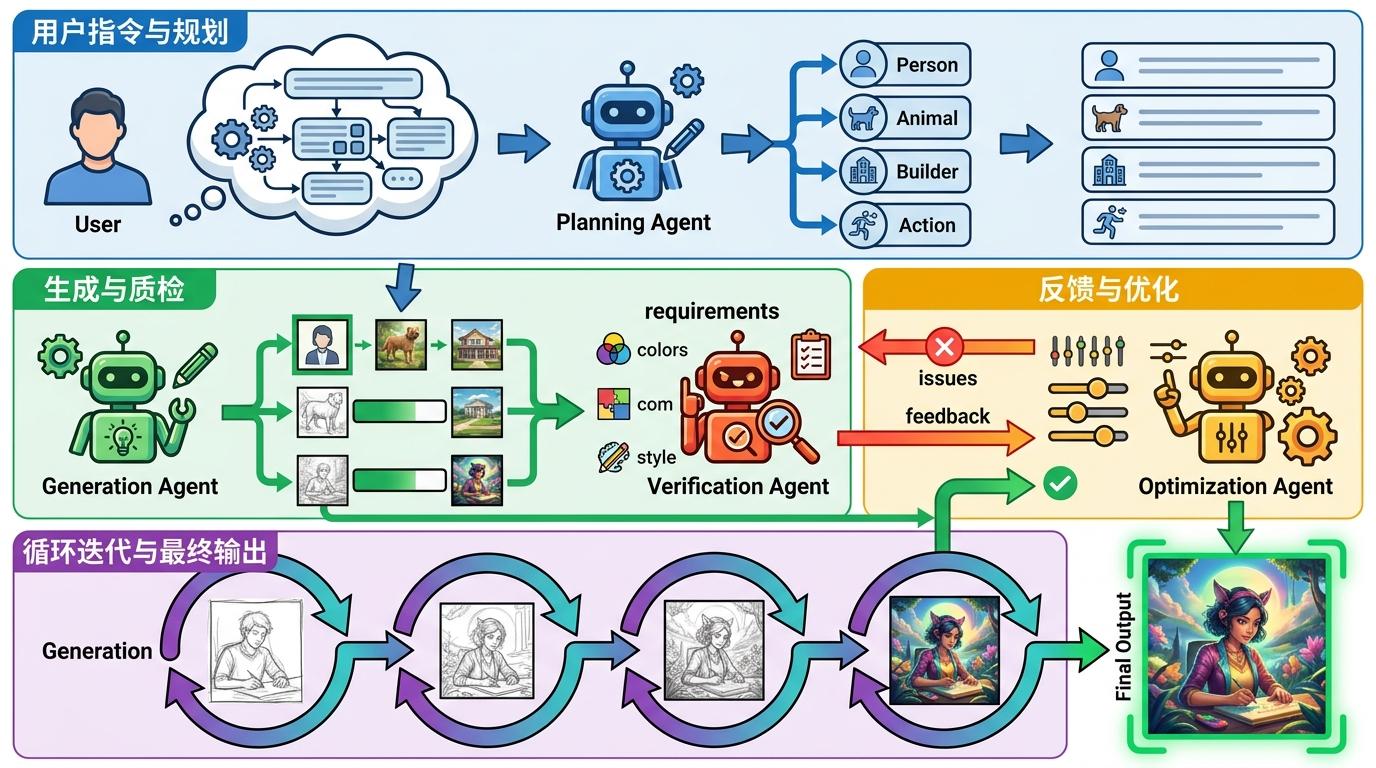
这个闭环协作的逻辑很简单:每一轮都先拆解任务,再生成,再验证,再优化,像搭积木一样一步步把结果拼到符合要求。实验数据显示,单是引入这个多智能体闭环,就能让模型性能从31.0直接跳到52.4——相当于从勉强及格,一下子摸到了优秀线。
更关键的是,这套班子是模块化的,缺什么角色就加什么,不用从头训练整个大模型,这也是它能赋能小模型的核心原因。
传统模型的「记忆」,就是把所有历史对话和生成记录一股脑堆在一起,像个杂乱无章的抽屉,找东西全靠瞎翻,还经常翻到没用的垃圾信息。GEMS的Agent Memory,相当于给AI装了个分层的文件柜:
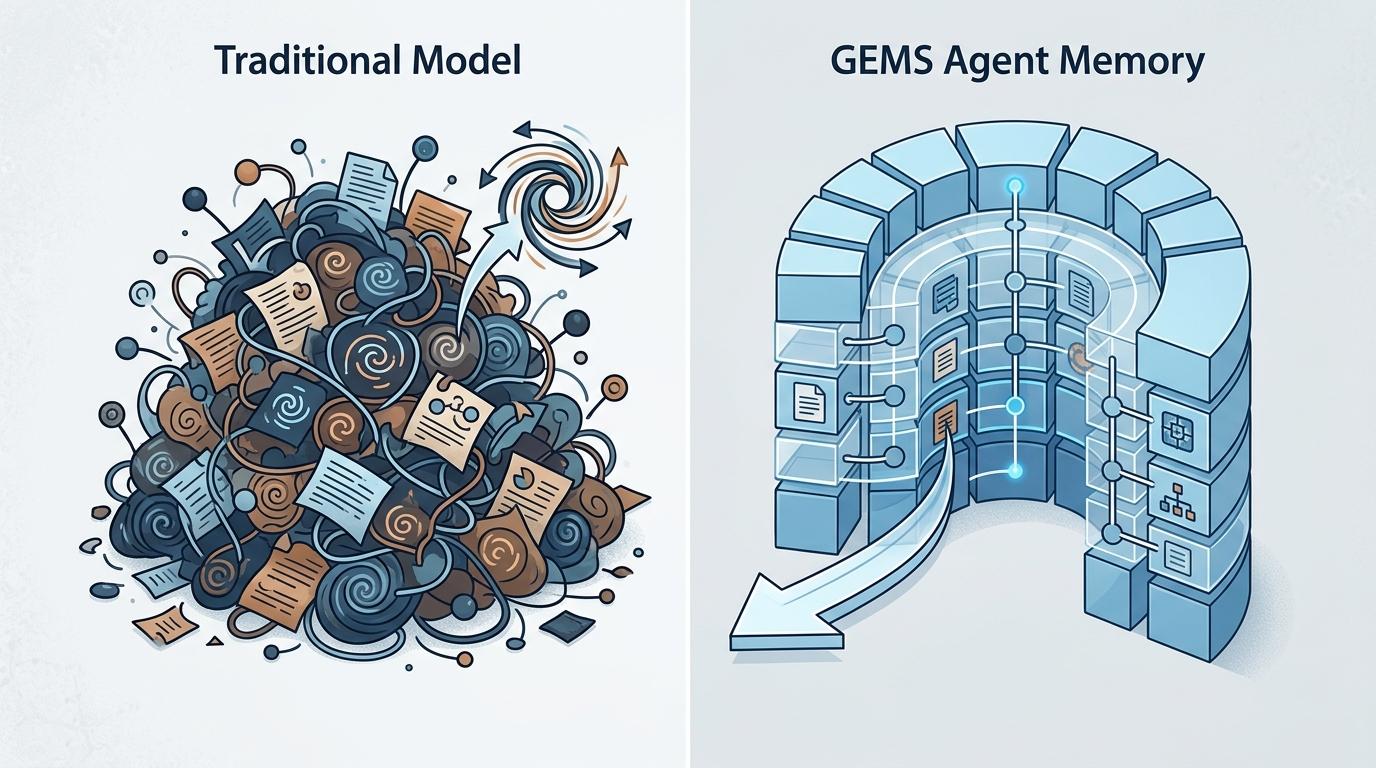
最底层是「事实抽屉」,专门存每一轮的提示词、生成的图像、验证反馈这些实打实的信息,确保随时能追溯细节;上层是「经验抽屉」,把每一轮生成时冗长的思考过程,压缩成一句句精炼的经验——比如「生成山脉日出时要强化光影层次」,而不是把整个思考链都存下来。
这种分层压缩有多高效?实验显示,单独加入记忆模块就能让性能再提升9分,还能把生成的平均轮次从3.26降到2.80——相当于少做14%的无用功,既省了计算资源,又让每一轮的优化更有方向。
更重要的是,它解决了大模型的一个老问题:不会从错误里学经验。以前的模型就算生成错了,下一轮还是可能犯同样的错,而有了分层记忆,它能把错误变成经验,下次再遇到类似任务,直接就知道该避开什么坑。
你有没有过这种经历:让AI生成一张有艺术感的山脉日出图,它却给你一张光影平淡的「写实照片」?不是它没能力,而是它不知道该调用「美学绘画」的技能。GEMS的Agent Skill,就是给AI建了一个可随时调用的「专家库」。
这个技能库像个按需加载的工具箱,里面存着各种任务的详细指令:比如「美学绘画」技能里,写着如何强化光影层次、调整色彩饱和度;「创意绘画」技能里,记录着怎么添加梦幻元素、营造故事感。当AI接到任务时,会先判断需要什么技能,再把对应的指令加载进来——不用把所有技能都塞进模型里,占内存还影响效率。
实验里有个很直观的对比:生成「漂浮的书」,没有技能加持时,只是一本普通的书飘在空中;触发「创意绘画」技能后,书页会飞舞起来,背景还会点缀星空,一下子就有了故事感。虽然技能模块单独只贡献了2.1分的性能提升,但它让AI的能力边界一下子拓宽了——从只会做基础任务,变成了能应对各种专业需求的多面手。

当然,这套框架也不是完美的:技能库的扩展需要人工整理专业指令,多智能体协作也会增加少量的沟通成本,但比起它带来的性能提升,这些代价显然值得。
当整个行业还在为「参数越大性能越好」的路径依赖狂奔时,GEMS的出现像个提醒:AI的未来,可能不是比谁的模型更大,而是比谁的「工作方式」更聪明。
它证明了一件事:给小模型装上协作的脑子、会总结的记忆、可扩展的技能,一样能在复杂任务上打败大模型。这不仅能降低AI的部署成本,让更多资源有限的场景用上高性能模型,更重要的是,它给多模态生成指出了一条新方向——与其堆参数,不如先把AI的「协作能力」「记忆能力」「学习能力」打磨好。
智能的本质,从来不是单个个体的强大,而是群体协作的智慧。 这句话放在AI身上,同样成立。