内容由AI生成,思考得你完成
App 下载
内容由AI生成,思考得你完成
App 下载当你让AI解一道数学题,它第一次就答对了——可你让它再给几种解法,它却翻来覆去只会那一种。这不是AI变懒了,而是它“学窄了”。复旦大学、无限光年等团队的新研究戳破了这个真相:很多用强化学习(RL)微调的大模型,单次答题正确率(Pass@1)上去了,可多次尝试的成功率(Pass@k)反而掉了。这意味着AI把所有宝都押在一种“标准答案”上,忘了还有其他解题路径。更糟的是,它还会忘了之前学过的跨领域知识。现在,他们找到了问题的根:被所有人忽略的RL目标里的divergence项,也就是KL散度的选择。
你可以把KL散度理解成AI的“行为紧箍咒”——它用来约束AI在学习新技能时,别偏离自己原本的知识范围。过去大家默认用的是反向KL散度,它的本质是“追着最可能的正确答案跑”。
打个比方,这就像老师只让学生背标准答案,只要答对一次就给高分。学生慢慢就会发现,与其花时间想其他解法,不如死死记住那一种能拿分的答案。反映在AI身上,就是它的解题路径越来越窄,最后只会“押题”,不会“解题”了。
但真实的机制比这个比喻更精确:反向KL散度的数学特性是“模式追踪”,它会让AI的策略快速收敛到少数高概率的正确模式上,对那些概率低但同样有效的解法视而不见。如果完全去掉这个紧箍咒,AI又会像脱缰的野马,彻底偏离原本的知识体系,连老技能都忘得一干二净。
实验里就出现了这种极端情况:研究团队先让AI学会用三种不同风格回答问题,只要看开头就能分辨;可经过标准RL训练后,AI只会用一种风格说话了。
既然反向KL是问题的根,那换个散度行不行?研究团队给出的答案是DPH-RL框架——核心就是把KL散度从“紧箍咒”变成“复习笔记”。
他们选择了前向KL散度和JS散度,这两种散度有个关键特性:“覆盖质量”。简单说,它们会逼着AI“复习”原本学过的所有解法,不能只盯着那一种高分答案。就像老师要求学生不仅要答对题,还要能说出所有可能的解题思路,不许偏科。
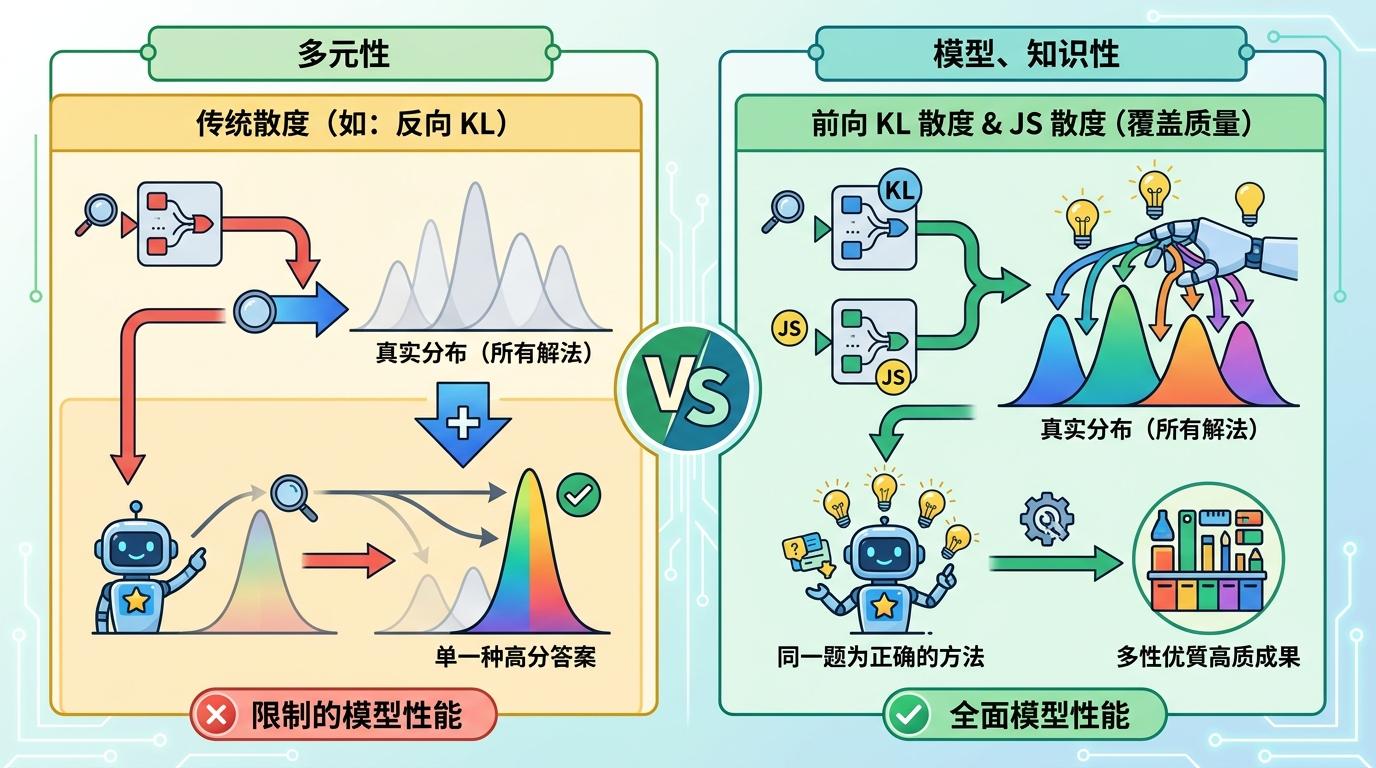
直给补刀:前向KL散度的约束逻辑是,只要AI原本会某种解法,就不能把这种解法的概率压到几乎为零;JS散度则更平滑,能在稳定性和多样性之间找到更好的平衡。而且这个框架不用在线维护参考模型,只要提前从初始模型里采样就行,训练效率反而更高。
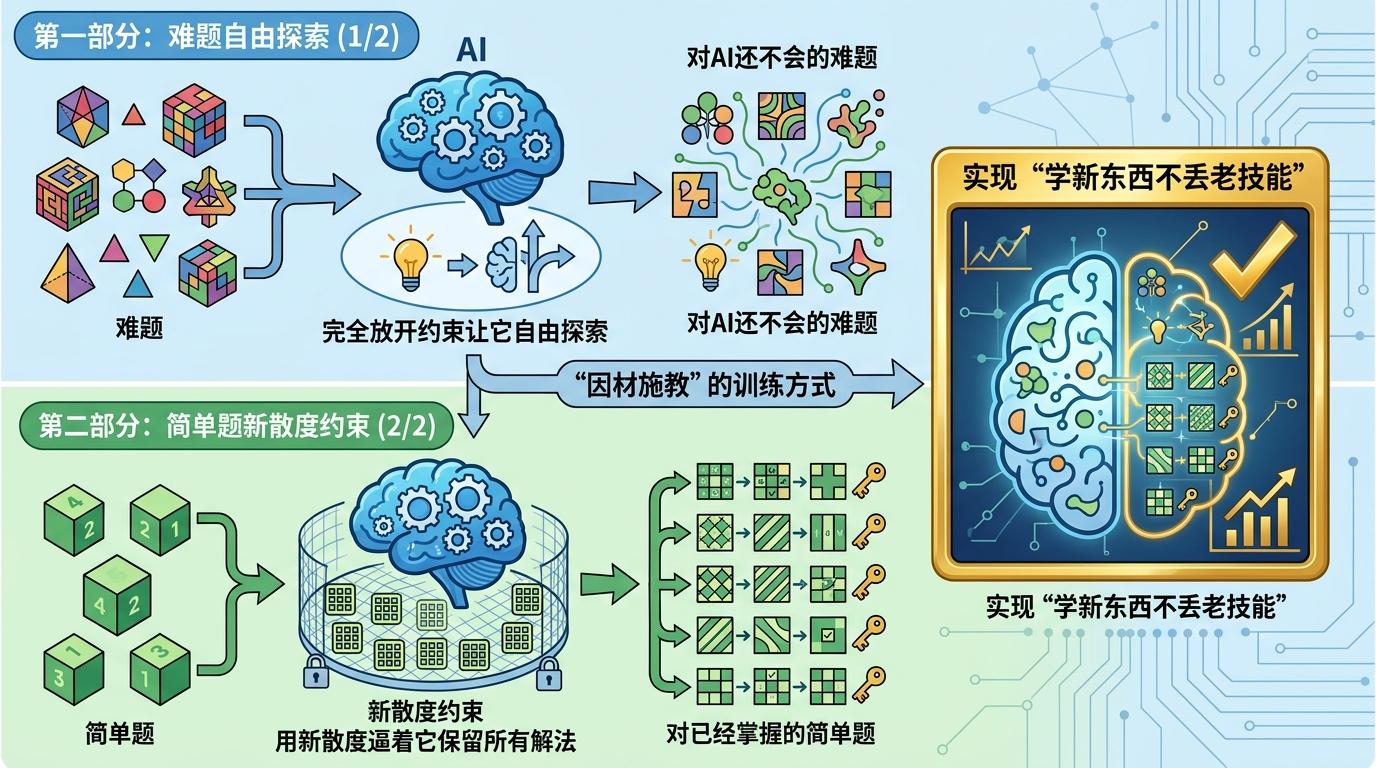
更聪明的是,他们把训练数据分成了两部分:对AI还不会的难题,完全放开约束让它自由探索;对已经掌握的简单题,就用新散度逼着它保留所有解法。这种“因材施教”的训练方式,终于实现了“学新东西不丢老技能”。
研究团队用Llama3.1-8B模型做了测试,只在SQL数据集BIRD上训练,却要在跨域SQL任务和数学推理任务上验证。结果一目了然:
用反向KL的模型,Pass@1虽然上去了,但Pass@8比基础模型低了不少;而用DPH-RL的模型,不仅Pass@1是最高的,Pass@8还超过了没经过RL训练的基础模型——相当于AI既学会了“一次答对”,又没丢了“多想几种办法”的能力。
在跨域和分布外任务上,差距更明显:所有用传统RL方法训练的模型性能都大幅下降,唯独DPH-RL的模型最接近基础模型的水平,甚至在某些指标上比其他RL模型高出9%。拆解数据后发现,DPH-RL的知识保留率极高,不像传统RL模型那样“学了新的,忘了旧的”。
当然,这个方法也不是万能的:它目前只在文本生成和代码任务上验证过,在机器人控制、多智能体系统等更复杂的场景下,还需要进一步测试;而且如何动态调整散度的约束强度,让AI在探索和保守之间找到最优平衡,还有待研究。
我们总在追求AI的“准确率”,却忘了真正的智能从来不是只会一种标准答案。就像人类解决问题时,从来不是只有一条路可走——有时候,那些“不那么高效”的解法,反而能在新问题上派上大用场。
这项研究最珍贵的地方,不是提出了一个新框架,而是把我们的注意力从“让AI更聪明”拉回了“让AI像人一样思考”。保多样性,比追正确率更重要。毕竟,未来的AI不该是只会背答案的考试机器,而应该是能灵活应变的“解决问题的人”。