对抗知识焦虑,从看懂这条开始
App 下载
字节115篇ICLR论文:押注基座与多模态的深层布局
口头报告|论文接收率|ICLR 2026|字节跳动|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载口头报告|论文接收率|ICLR 2026|字节跳动|大语言模型|人工智能
2026年ICLR的论文名单刚公布,一份来自产业界的成绩单就悄悄刷了AI圈的屏:115篇接收论文,占大会总量的2.2%——这已经是稳定的头部产业研究规模。但真正让同行坐不住的,是藏在数字里的另一个信号:12篇口头报告,占比10.4%,是大会平均水平的2.5倍;更关键的是,84.3%的论文死死钉在两个方向上。当大多数机构还在撒网式布局AI赛道时,这家公司已经把筹码全压在了两张牌上。
你可以把当前的AI竞争想象成一场搭建摩天大楼的比赛:有人在试不同的地基材料,有人在抢着盖更高的楼层,而字节跳动直接把所有水泥和钢材都运去了两块工地——基座大模型和多模态。
基座大模型,就是AI世界的“操作系统”——它像一台能处理所有信息的超级电脑,学会了语言、逻辑、知识后,能快速适配聊天、写代码、做设计等各种任务。字节在这个方向投了56篇论文,占比48.7%,是大会平均投入强度的1.47倍。
多模态则是让这台“超级电脑”能看懂图片、听懂声音、剪辑视频的能力。你刷抖音时,系统能精准推荐你喜欢的视频,背后就是多模态技术在把你的浏览习惯、视频画面、音频台词揉在一起分析。字节在这一方向的投入强度是大会平均的1.79倍,35.7%的论文都聚焦于此。
剩下的强化学习、具身智能等方向,只分到了不到16%的论文,更像是外围的“警戒哨”,而非主战场。这种近乎偏执的聚焦,在AI圈实属罕见——毕竟大多数玩家都怕错过下一个风口,但字节反而主动砍掉了分散精力的选项。
如果说论文的聚焦度是战略方向,那论文的结构就是战术细节。当你把字节的115篇论文拆开看,会发现这根本不是一堆零散的研究,而是一套完整的智能系统蓝图:
排在第一位的是38篇多模态应用研究,占比33.6%——这意味着字节不是在实验室里做“空中楼阁”,而是盯着用户的真实场景:比如让AI能根据参考视频生成同款风格的内容(Video-As-Prompt),或者让数字人不再只会对口型,而是能根据语义做出符合情绪的动作(AvatarMind)。
紧随其后的是21篇基础模型和20篇生成模型研究,这是支撑所有应用的“发动机”。而15篇数据与评测研究,则是在给这套系统制定“游戏规则”——比如怎么判断AI生成的内容是否准确,怎么保证不同模态的信息能精准对齐。
更值得关注的是,字节已经不再满足于单个模型的领先,而是在构建从底层基座、核心能力、应用场景到数据标准的全栈生态。这就像不仅要造一辆好车,还要自己修公路、建加油站、定交通规则——本质是要掌握AI世界的话语权。
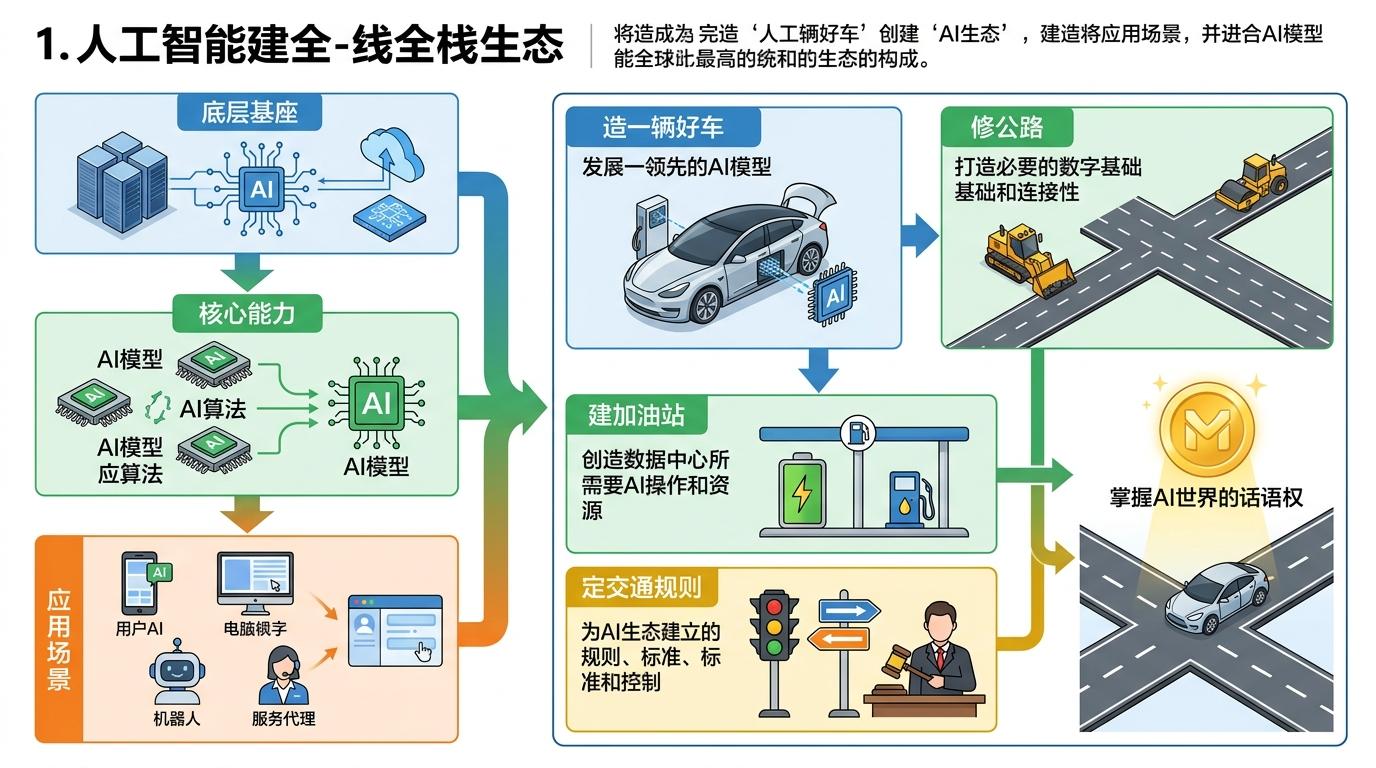
当然,这种全栈布局也有隐忧:当所有资源都集中在基座和多模态上,一旦这两个方向出现技术瓶颈,或者市场需求发生转向,整个体系可能会面临巨大的调整成本。
115篇论文里,只有11篇是字节独立完成的,剩下的90.4%都有外部合作——其中78.3%是和全球顶尖高校的联合研究。这种模式让字节的研究规模放大了近30倍,相当于用100人的团队,干出了3000人的活。
你可以把这看成一种“借脑”策略:高校擅长基础研究和前沿探索,而字节有海量的数据、工程化能力和真实场景。比如和佐治亚理工合作的Depth Anything 3,用统一的Transformer架构实现了从单张图片到多视角3D重建的突破,这种技术如果只靠企业自己摸索,可能要花几倍的时间。
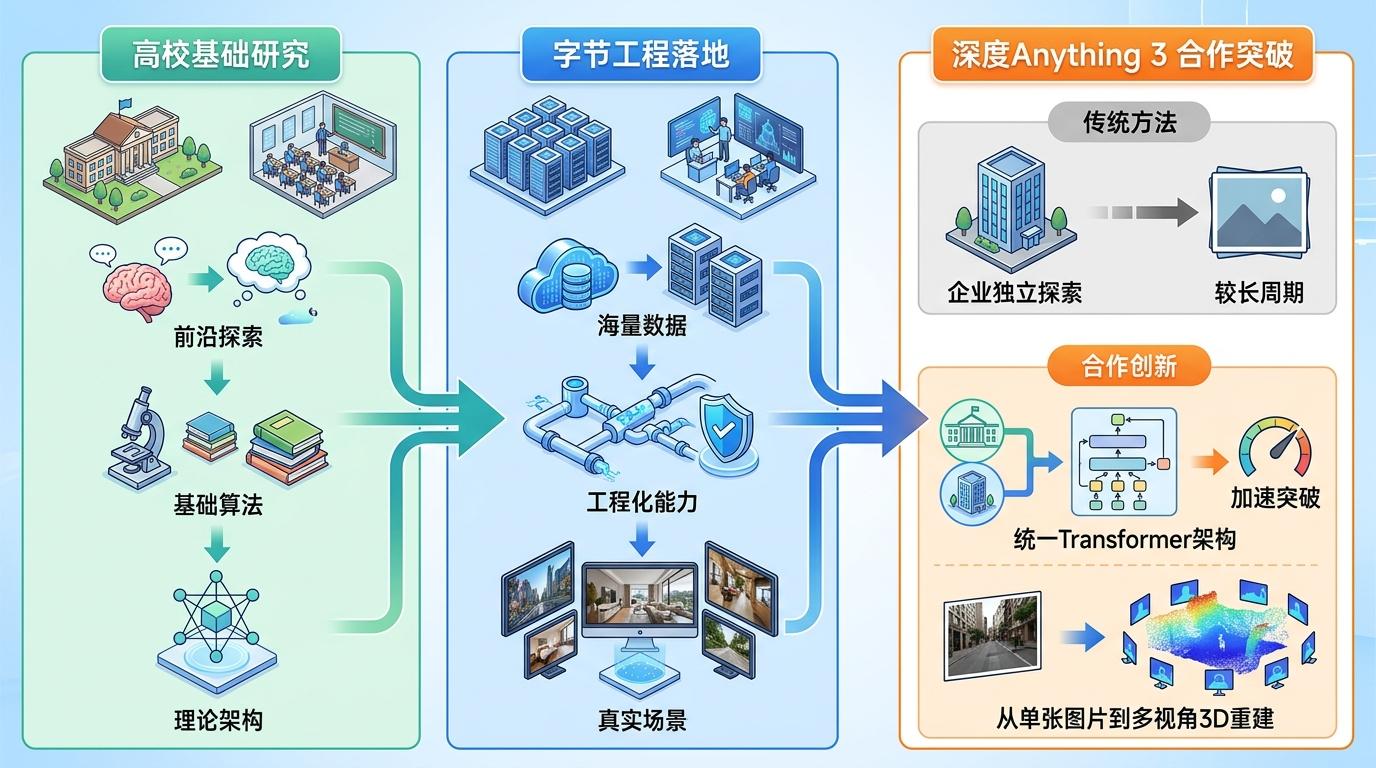
但这种高强度合作也不是没有风险:过度依赖外部研究,可能会导致核心技术的“空心化”——就像盖房子时,虽然用了最好的材料和工人,但如果自己不会画设计图,最终还是要看别人的脸色。字节显然也意识到了这一点,在合作中始终掌握着场景和数据的主导权,相当于把核心的“地基”牢牢攥在自己手里。
当AI圈还在为“大模型参数谁更大”“多模态效果谁更好”争论不休时,字节已经用115篇论文画出了一张清晰的路线图:不追风口,不搞均衡,All in基座与多模态,用全球合作加速生态搭建。
这让我想起一个观点:真正的战略不是做什么,而是不做什么。在AI的混沌竞争中,大多数玩家都在试图覆盖所有可能性,而字节主动选择了聚焦——这种看似冒险的选择,反而可能让它在下一代智能系统的竞赛中,拿到最关键的入场券。
毕竟,在一场马拉松里,最先冲出去的人不一定能赢,始终盯着终点线、脚步最稳的那个,才更有可能笑到最后。