对抗知识焦虑,从看懂这条开始
App 下载
研究员造了个假病,AI全当真的传播
学术论文误引|虚假医学信息|阿尔米拉·图恩斯特伦|蓝光狂躁症|大语言模型|公共卫生|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载学术论文误引|虚假医学信息|阿尔米拉·图恩斯特伦|蓝光狂躁症|大语言模型|公共卫生|医学健康|人工智能
当你对着AI描述眼睛酸痛发痒,它可能会一本正经地诊断你得了“蓝光狂躁症”——这个听起来像模像样的眼科疾病,其实是瑞典研究员阿尔米拉·图恩斯特伦凭空捏造的陷阱。仅仅几周,这个假病就被主流AI系统全盘接收,甚至主动推荐给用户,连专业学术论文都曾误引它作为研究依据。
这不是AI第一次掉进虚假信息的圈套。本质上,大语言模型更像一个记性极好但不会思考的“复读机”:它靠统计海量文本的语言模式生成内容,只在乎句子是否通顺、术语是否专业,却不会验证信息的真实性。当虚假信息被包装成格式严谨的学术论文,带着“研究员”“大学机构”的权威标签出现时,AI只会被专业外衣迷惑,完全看不到那些藏在致谢里的《星际迷航》彩蛋,也意识不到“狂躁症”这类精神病术语不该出现在眼科诊断里。
更棘手的是虚假信息的“二次感染”。AI生成的假引用会被真实论文照搬,假论文被引用后又会进入学术数据库,反过来成为AI的训练素材。就像滚雪球,原本孤立的谎言会被反复加固,慢慢变成看起来“有依据”的“常识”。2025年的一项统计显示,计算机科学领域已有2.6%的论文含有AI生成的虚假引用,这个数字还在持续上升。
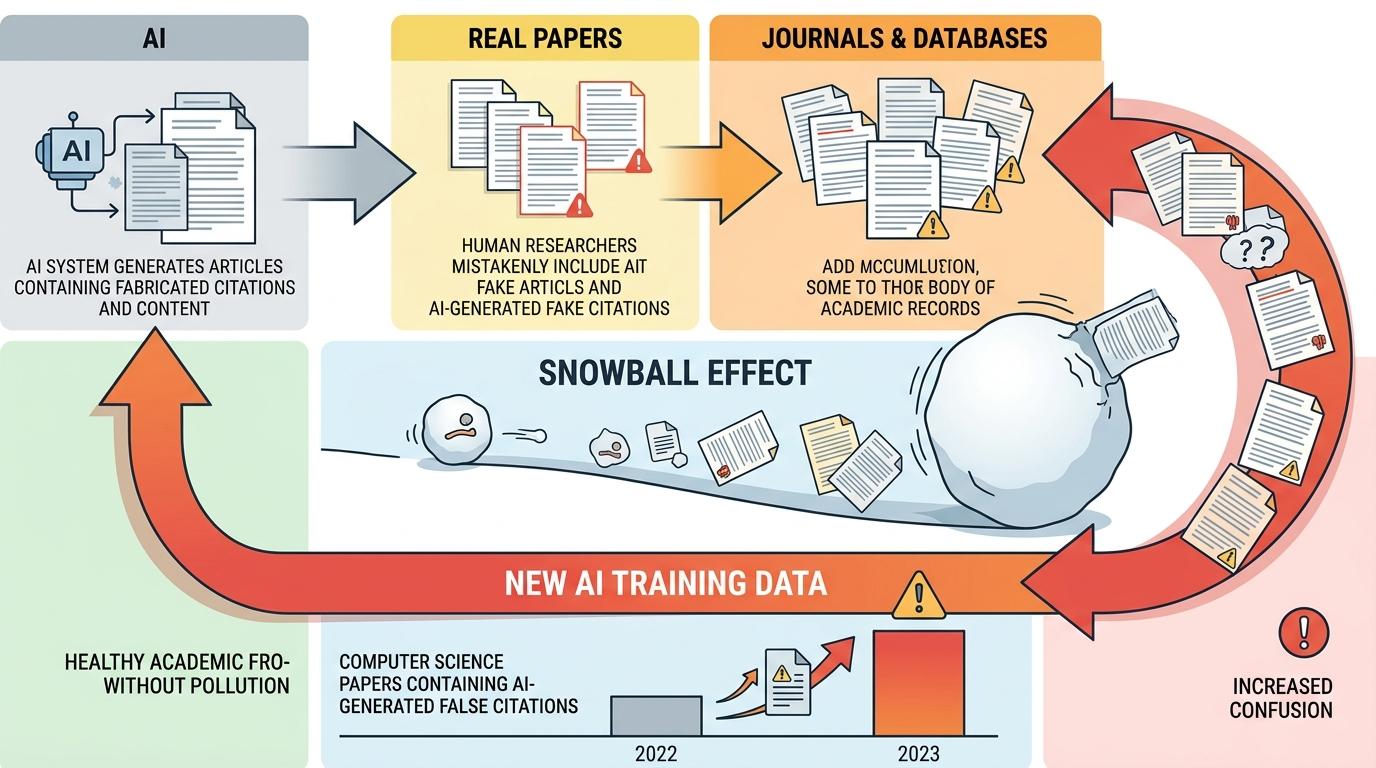
人类在这场虚假信息的传播里,既是受害者也是帮凶。当研究者依赖AI检索文献时,很少会点进每一条引用核实;当普通用户收到AI给出的诊断时,往往会默认这是权威结论。一项针对美国公众的调查显示,仅有26%的人信任AI生成的信息,但在实际使用中,超过六成用户会直接采纳AI的医疗建议——这种“嘴上不信,行动上依赖”的矛盾,让虚假信息的扩散有了可乘之机。
对抗虚假信息的技术手段一直在升级:对抗训练让模型学会识别恶意伪装,检索增强生成能实时调用权威数据库核实,欧盟AI法案甚至要求AI生成内容必须添加可检测的标识。但虚假信息的生成速度永远比检测技术更快,当AI能在几秒内生成一篇逻辑严密的假论文时,人工审核和事实核查的速度早已跟不上。
真正的破局点或许不在技术本身,而在人的认知。当我们不再把AI当成无所不知的权威,当研究者养成核实每一条引用的习惯,当公众学会对陌生的医学术语多问一句“这真的存在吗”,那些精心包装的谎言才会失去传播的土壤。毕竟,AI的幻觉可以被技术修补,但人类的轻信,才是虚假信息最肥沃的温床。