对抗知识焦虑,从看懂这条开始
App 下载
AI越流畅,越要给信任加点摩擦
第三方证据|内容验证|数据集更新|自动化自满|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载第三方证据|内容验证|数据集更新|自动化自满|大语言模型|人工智能
我曾花五分钟让AI更新完一篇基建论文的数据集,它返回的内容格式规整、数字看起来完全合理,我扫了一眼就直接粘进了草稿——直到第二天才发现,我根本没读过那些数字。我把「格式顺眼、没报错」当成了「内容正确」,甚至在后来意识到这点时,第一反应不是「AI会不会错了」,而是「我当时怎么没发现」。这才是最可怕的:我默认了「检查已经发生」,却忘了真正的检查从来不是看「感觉对不对」,而是找「AI碰不到的第三方证据」。为什么我们会把AI的流畅输出,错当成已经验证过的真相?
这种把工具输出当标准答案的状态,有个专门的名字——自动化自满(automation complacency),指的是当我们习惯了工具的可靠,注意力会慢慢漂移,最终无条件接受它的输出。不管是资深专家还是新手,都逃不开这个陷阱:医生会跟着AI的错误诊断修改判断,律师会把AI编造的判例当成真实依据,就连写论文的研究者,也会像我一样把「格式正确」等同于「内容正确」。
这不是粗心,是大脑的自我保护。当认知负荷过载、时间紧张时,我们会自动选择「省力模式」——既然AI总能给出流畅的答案,为什么还要花力气质疑?但AI的「流畅」和「正确」根本是两回事:它只是在预测最符合语言逻辑的句子,不是在验证事实的真实性。就像你问它一个不存在的知识点,它也能一本正经编出一套听起来无比专业的解释——这就是AI的「幻觉」,而我们的自动化自满,会把这种幻觉当成真相。
工程领域早就有了应对这种风险的标准答案——独立验证与确认(IV&V),简单说就是找一个和AI「没关系」的第三方来做检查。美国国家标准与技术研究院(NIST)定义它为「客观第三方执行的评审」,NASA甚至要求评审者必须在技术、管理、财务上完全独立于开发团队,就是为了避免「自己人查自己人」的漏洞。
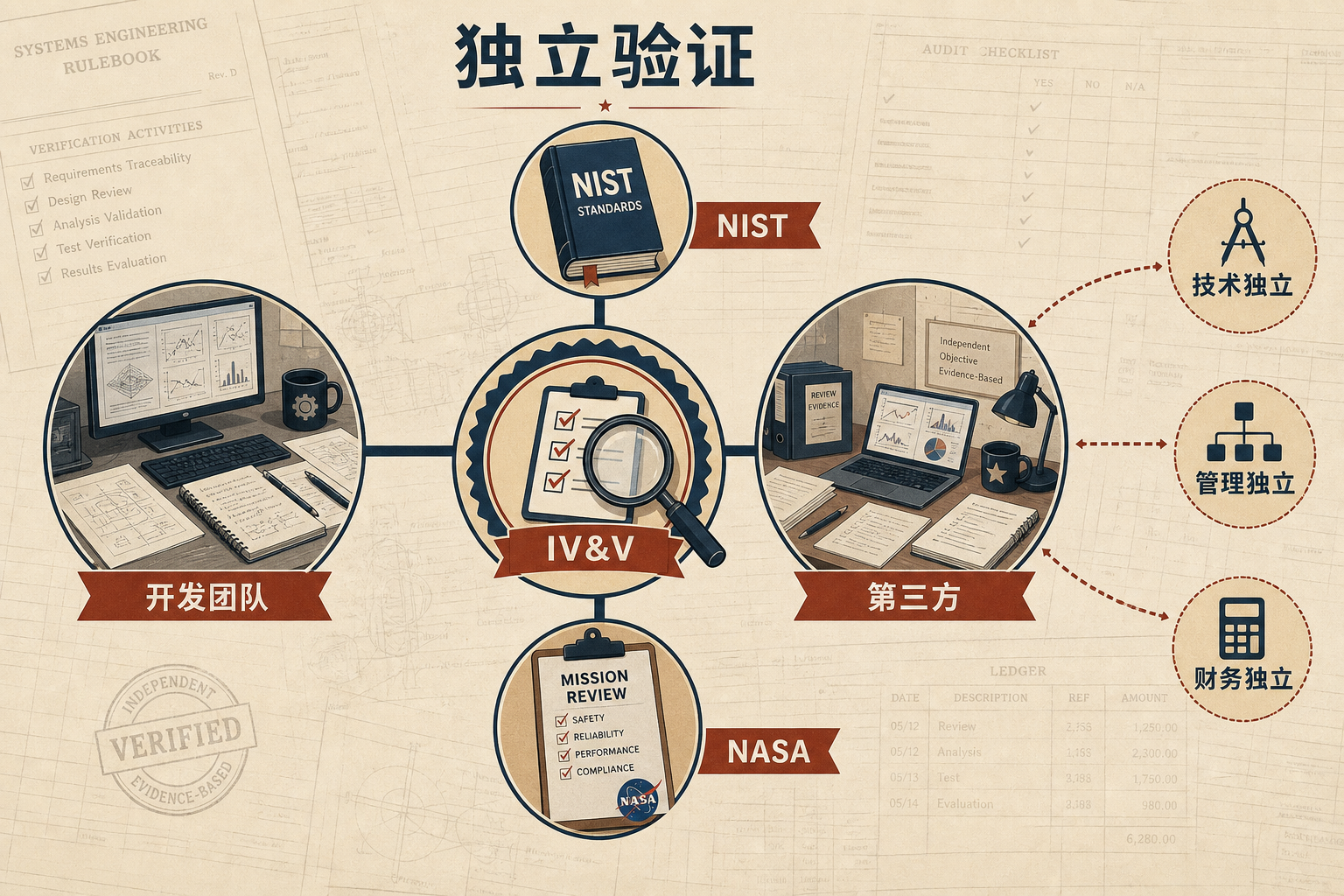
这个逻辑放到AI时代依然成立:真正的验证,必须来自AI生成环节之外的「盲区」。你可以试试这三个办法:一是换个AI模型交叉验证,不同模型的「幻觉」往往不一样,差异会帮你发现问题;二是把AI输出打印出来,换个房间重读——陌生的物理环境能打破你对「流畅文本」的熟悉感,让你重新用批判的眼光看内容;但最有效的,还是找同行或者领域专家帮你看,他们带着不同的知识背景和利益立场,不会像你一样被AI的流畅感迷惑。
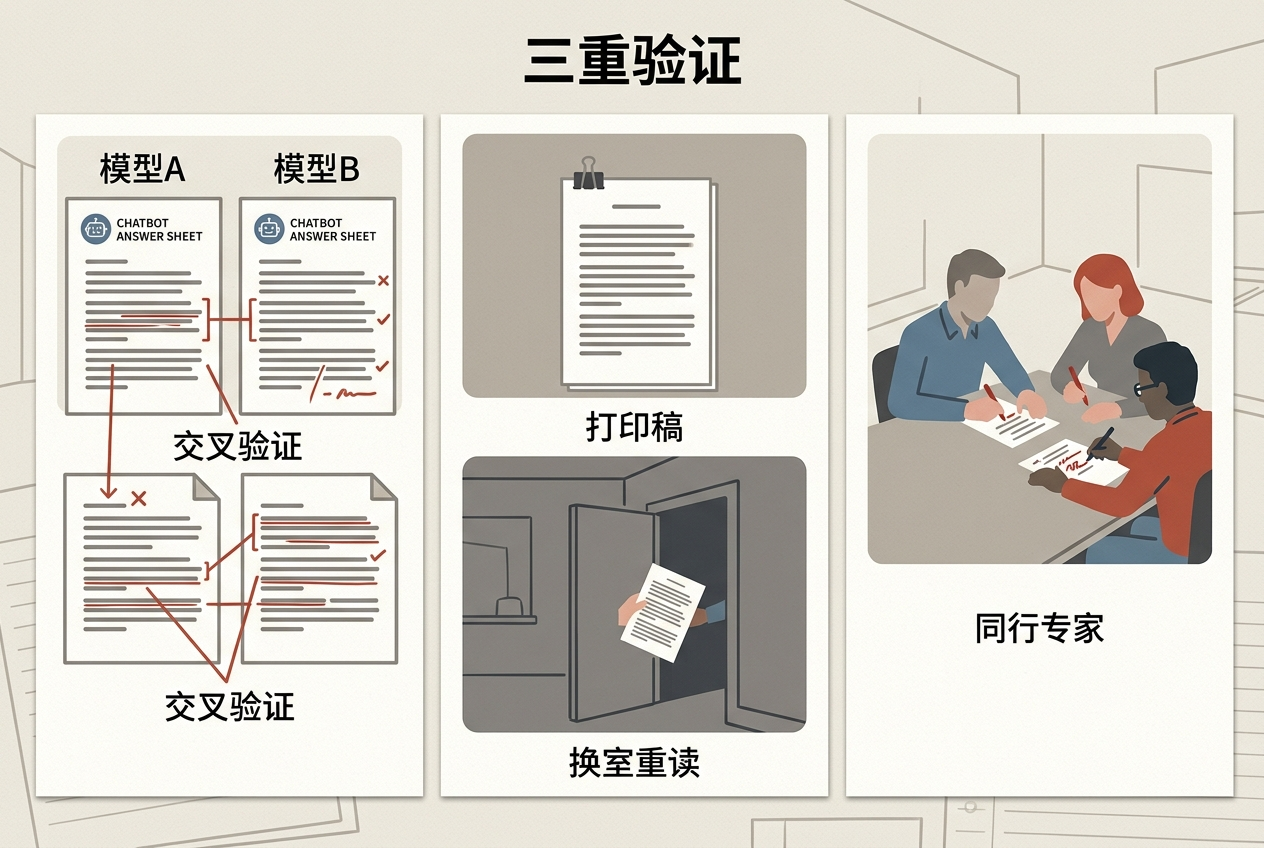
但要记住,前两个方法只是「辅助检查」,只有第三方的独立判断,才是真正能守住错误的最后一道防线。
现在越来越多的行业已经开始把独立验证写进规则里:加州律师协会要求律师必须亲自验证AI生成的所有内容,英国NHS的乳腺癌筛查项目强制引入外部独立验证,NIST的AI风险管理框架也把「独立验证」列为高风险AI系统的必备要求。这些规则不是为了限制AI,而是为了让我们在享受AI效率的同时,不失去对真相的掌控。
但规则只是底线,真正的安全来自我们的「认知自觉」。我们要学会把「AI给了答案」和「答案是对的」分开,要主动给自己的信任加点「摩擦」——不要因为AI输出流畅就放松警惕,不要因为节省时间就跳过验证,更不要把「我应该发现错误」当成「我已经发现了错误」。毕竟,AI可以帮我们省力气,但不能替我们负责任。
AI的出现,不是为了让我们变成「按按钮的人」,而是为了让我们有更多时间去做「判断的人」。我们追求效率,但效率的前提是真相;我们信任工具,但信任的基础是验证。
信任不是无底线的接纳,而是带摩擦的协作。 未来的AI时代,真正的竞争力不是谁能用AI更快完成工作,而是谁能在AI的流畅输出里,始终保持质疑的本能,守住独立验证的底线。