对抗知识焦虑,从看懂这条开始
App 下载
AI视频推理不靠逐帧,靠一遍遍涂改草稿
推理范式|扩散模型|AI视频生成|南洋理工|商汤|多模态视觉|人工智能
让AI生成一段“机器人走迷宫”的视频,你猜它会怎么思考?过去所有人都默认,它会像拍电影一样,先画第一帧的第一步,再根据第一步画第二帧的第二步——就像我们用逐帧动画的方式创作。但商汤、南洋理工等机构的最新研究,把这个默认认知彻底砸碎了。他们用一系列实验“剖开”了AI的“大脑”,发现它根本不是逐帧推理的。那它的思考逻辑到底是什么?这不仅关乎AI视频的未来,更牵扯到我们对机器智能的底层理解。
从逐帧到步骤:推理范式的彻底反转
要理解这个新发现,得先搞懂扩散模型的基本逻辑——你可以把它想象成一个从混沌到清晰的画家:学习时,它会把一张干净图片一步步加噪到全是雪花点;生成时则反过来,从雪花点开始,根据提示词一步步去噪,最终还原出清晰画面。
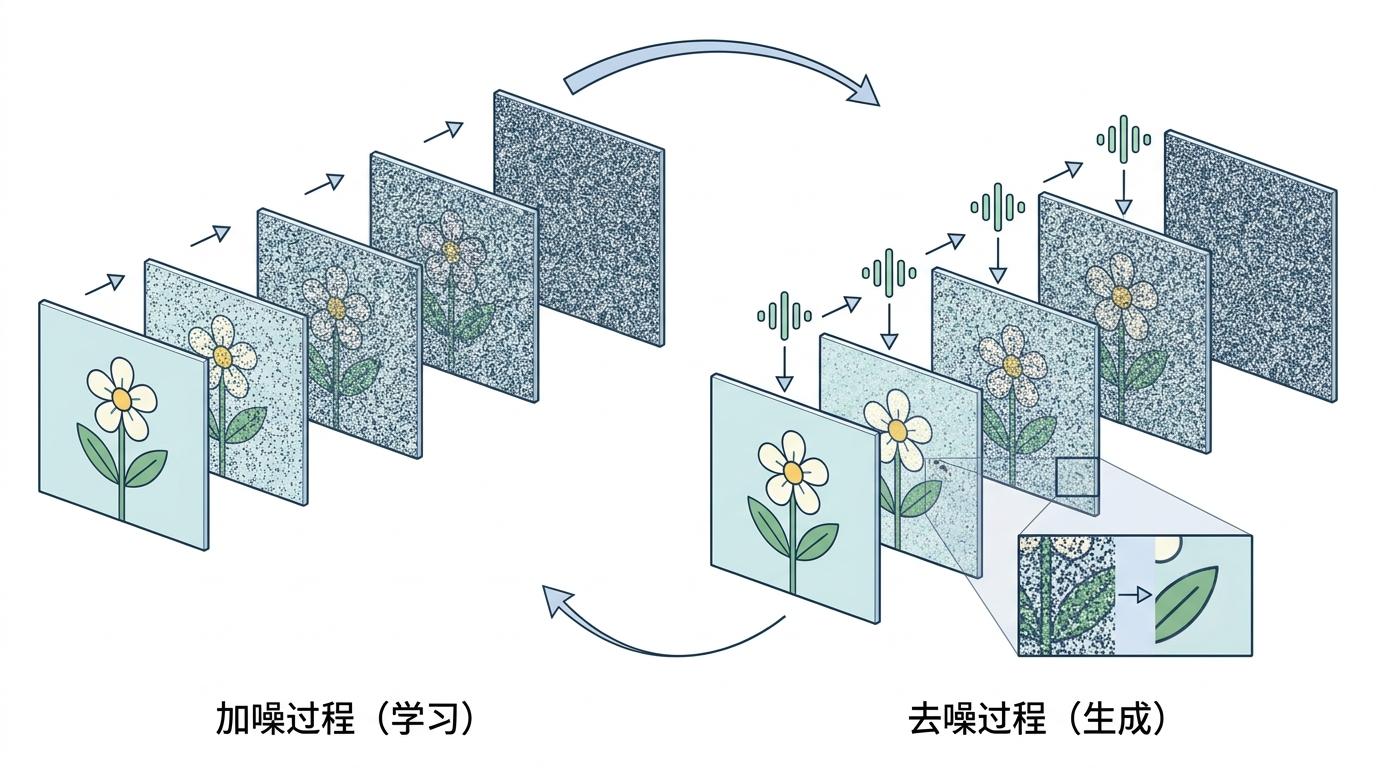
过去我们以为,AI的推理就发生在最终的画面序列里:先想第一帧怎么走,再想第二帧。但研究团队通过观察每一步去噪后的中间状态发现,推理的痕迹根本不在帧的顺序上,而在每一轮去噪的步骤里。他们给这个新机制起了个名字:步骤链(Chain-of-Steps)。
简单说,AI不是一帧一帧画,而是一遍遍涂改整个视频草稿:早期去噪步骤,它会在草稿上同时画好几条可能的迷宫路径;中期步骤开始擦掉走不通的路;到了最后几步,一条清晰正确的路径才会显现。
最有力的证据来自噪声扰动实验:如果在某个关键去噪步骤注入噪声,AI的推理性能会直接暴跌;但如果持续污染某一帧,性能下降却温和得多——因为AI每一步都会参考所有帧的信息,单帧的错误很容易被修复,可步骤被打断,整个推理逻辑就崩了。
像人一样慢思考:涌现的三大智能行为
随着对步骤链机制的深入拆解,研究团队还发现了更惊人的事:AI在一遍遍涂改草稿的过程中,自发涌现出了类人的推理能力。
第一个能力是工作记忆。在“物体返回原位”的任务中,AI会在所有去噪步骤里始终“记住”物体最初的位置;即使小泰迪熊被大熊完全挡住,AI在早期步骤也会保留它的轮廓信息,确保后续帧能正确再现——这解决了视频生成中经典的“物体恒存性”难题。
第二个能力是自我修正。生成“球反弹击中目标”的视频时,AI早期步骤画的轨迹模糊又不完整,但随着去噪推进,它会慢慢把轨迹补全、修正;甚至一开始画错了立方体的旋转结果,后面也能自己调整到正确状态。
第三个能力是先感知后行动。生成“汽车撞开门”的视频时,AI早期步骤只会先定位出画面里的“汽车”和“门”,等搞清楚了“是什么”和“在哪里”,才会在后期步骤规划汽车的运动轨迹和撞击的物理交互——完全符合人类解决问题的逻辑。
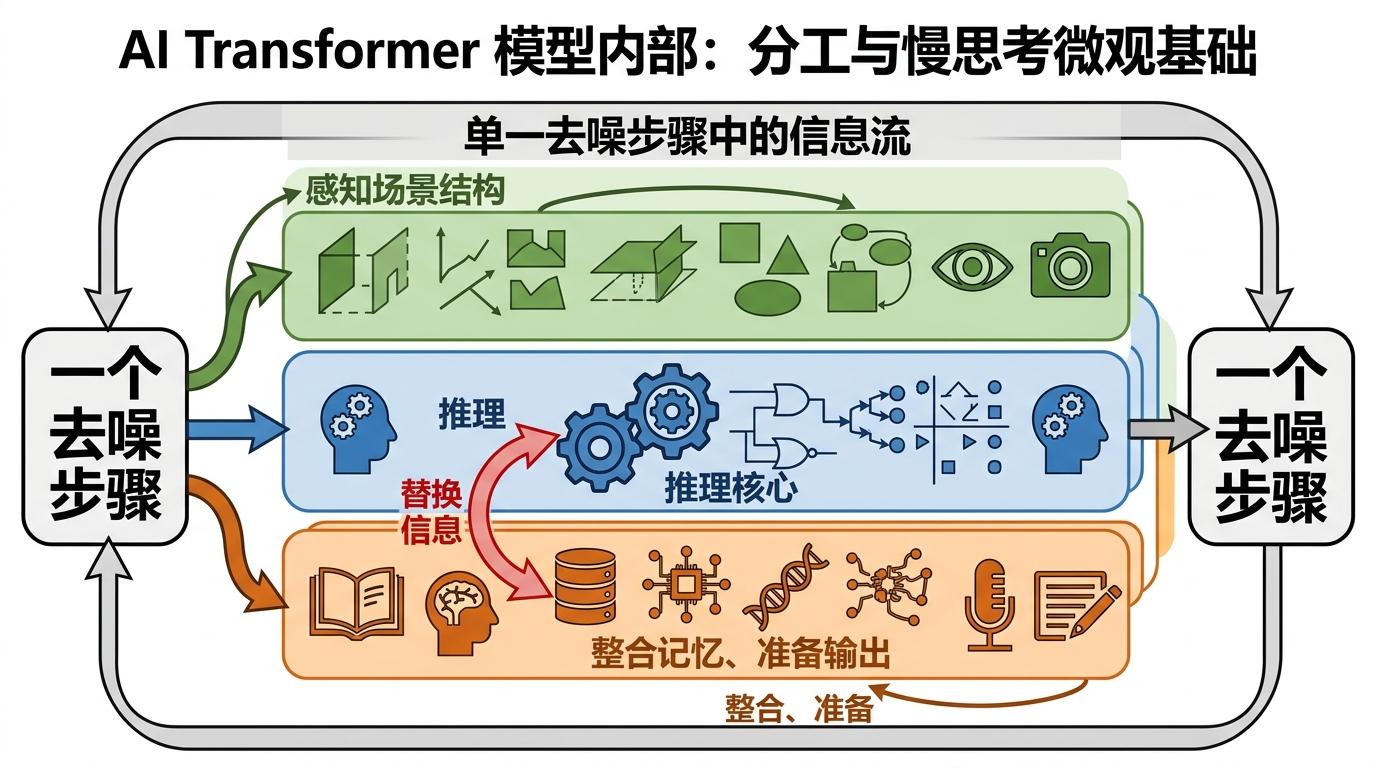
更有意思的是,AI的Transformer模型内部还形成了明确的分工:早期层负责感知场景结构,中间层是推理的核心(替换这部分的信息会直接改变最终结果),后期层则负责整合记忆、准备输出。这种“感知-推理-整合”的循环,在每个去噪步骤里重复上演,构成了AI慢思考的微观基础。
无需训练:一个简单技巧提升推理性能
基于对步骤链机制的理解,研究团队还提出了一个无需任何额外训练就能提升AI推理性能的技巧——说出来简单到离谱:用同一个模型,三个不同的随机种子生成三条推理轨迹,然后在每个去噪步骤,把三条轨迹的潜表示取平均,作为下一步的输入。
本质上就是让AI“集思广益”,在早期步骤能探索更多可能性,从而更大概率收敛到正确答案。这个方法成本极低,只是推理时多算两遍,但效果显著:在VBVR视频推理基准测试中,原本得分0.685的模型,用了这个技巧后直接涨到0.716,几乎所有子任务的性能都有稳定提升。
当然,我们也得清醒地看到局限:目前AI的推理能力还高度依赖训练数据,在跨领域泛化上表现很差;而且这个技巧虽然有效,但也让推理成本翻了三倍。更重要的是,人类在VBVR测试中的得分是0.974,即使是最优的AI模型,和人类的差距依然巨大——它只是学会了像人一样“思考”的形式,还远没达到人类的理解深度。
当我们把AI的“黑箱”剖开一层,会发现它的智能涌现比我们想象的更接近人类——不是靠精准的线性计算,而是靠模糊的并行探索、逐步的筛选修正。这打破了我们对AI“机械性”的刻板印象,也让我们意识到:机器智能的进化,可能不是在模仿人类的“结果”,而是在复刻人类的“过程”。
慢思考,才是智能的本质。 这个发现不仅能帮我们优化AI视频生成的性能,更能让我们重新思考:到底什么是智能?当AI开始像人一样“涂改草稿”“反复琢磨”,我们和机器的边界,会不会比想象中更模糊?