对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶事故率降为人类1/10,靠的不是传感器堆料
人机反应时间|感知决策一体化|事故率数据|端到端神经网络|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载人机反应时间|感知决策一体化|事故率数据|端到端神经网络|自动驾驶|人工智能
想象你开在深夜的高速上,眼皮开始打架,前车突然急刹——人类的反应时间通常是0.2到0.5秒,而一套系统能在0.05秒内完成感知、决策和制动。这不是科幻:2025年的数据显示,采用端到端神经网络的自动驾驶车辆,平均每行驶1077万公里才发生一次事故,而人类驾驶的事故间隔仅为113万公里。10倍的安全差距,到底是怎么来的?不是靠堆更多摄像头或雷达,而是靠一种能让汽车像人类一样“直接学开车”的技术逻辑。
传统自动驾驶系统像个分步骤解题的学生:先让摄像头“看”清楚路上的车和人(感知),再让算法“想”该怎么走(规划),最后让执行模块“踩”刹车或打方向(控制)。每一步的信息传递都可能损耗,遇到没见过的场景——比如飘在路中间的塑料袋——就容易卡壳,因为它的“知识点”里没有这个标签。
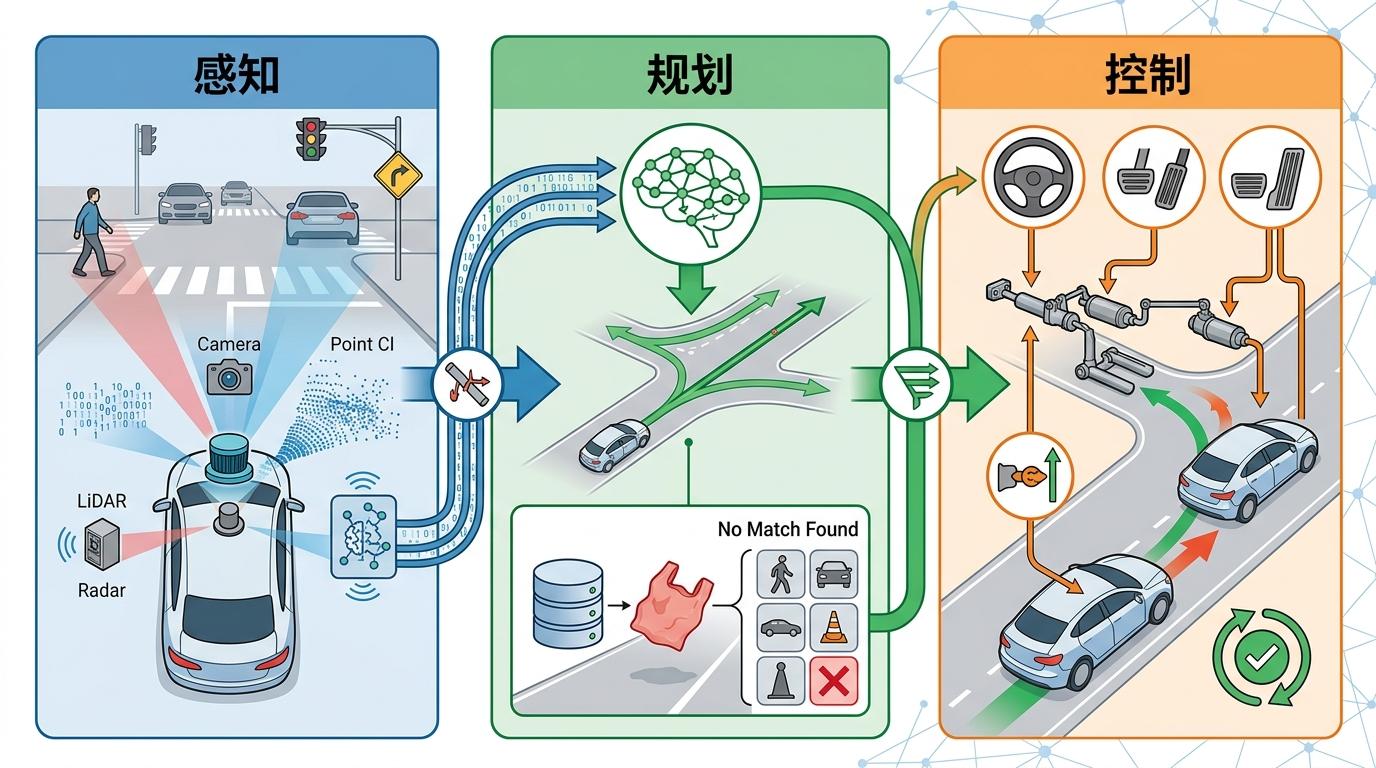
端到端神经网络则是直接“看题答题”:把摄像头、车速、导航等所有原始数据一股脑喂进一个模型,输出端直接就是方向盘角度、刹车力度——没有中间步骤,也不需要人工预设任何规则。你可以把它想象成一个跟着老司机学开车的学徒:不用先学“什么是红灯”“什么是行人”,只要看老司机遇到各种情况时怎么操作,慢慢就学会了“看到红灯踩刹车”“看到行人打方向”。
这个看似简单的逻辑,背后是海量数据的支撑。比如某厂商的车队每天能收集相当于500年驾驶时长的数据,这些数据不是随便堆给模型,而是通过“影子模式”筛选高价值样本:当AI的决策和人类司机不一样时,这段数据就会被标记为“需要重点学习”,送回超级计算机训练。
端到端模型的安全优势,本质是“数据飞轮”在转动:跑在路上的车越多,收集到的场景数据就越丰富;数据越丰富,模型的决策就越准确;模型越准确,就有越多用户愿意使用,反过来又能收集更多数据。
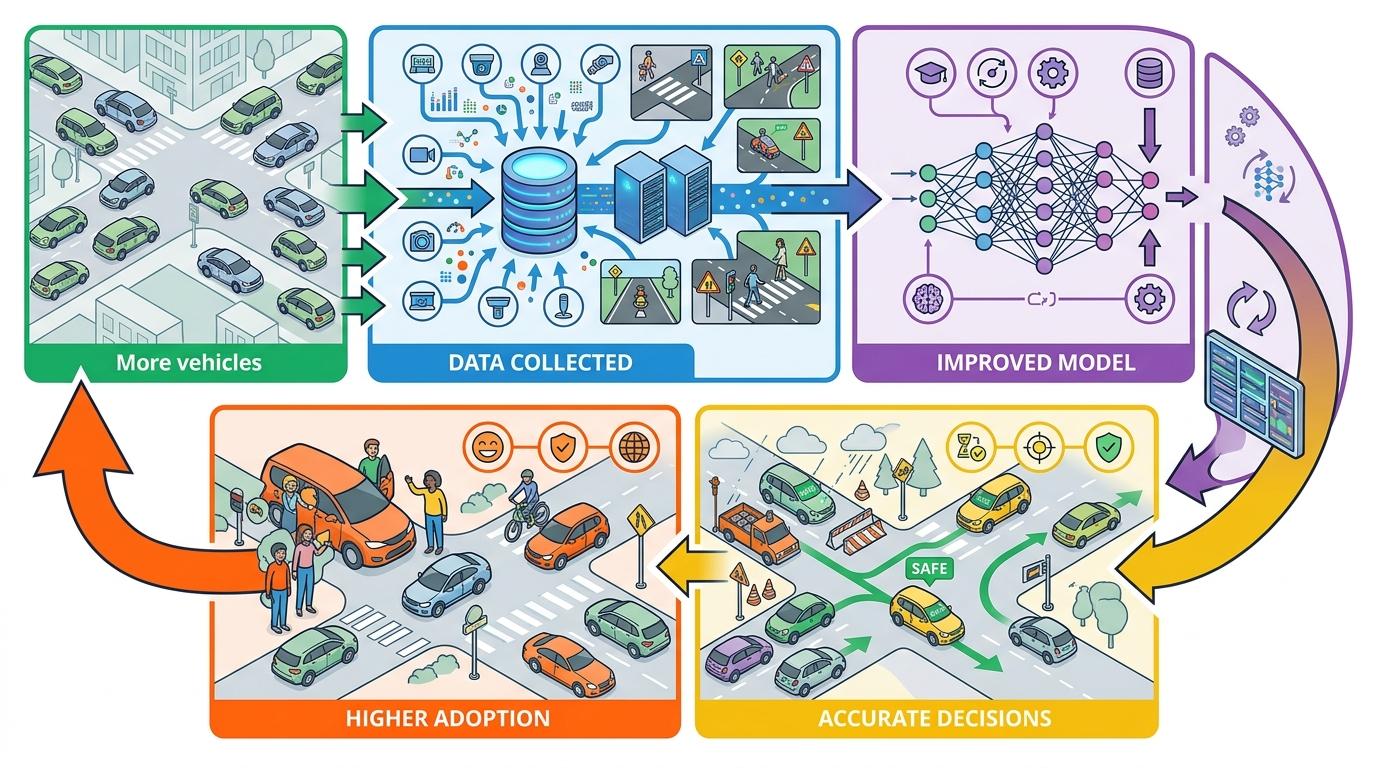
这个飞轮的核心是“边缘场景”——那些罕见但致命的情况,比如突然横穿马路的行人、掉在路中间的货物。传统方法靠人工设计规则应对这些场景,永远赶不上现实的复杂;而端到端模型靠数据说话:只要车队里有一辆车遇到过,所有车的模型就都能学会应对。
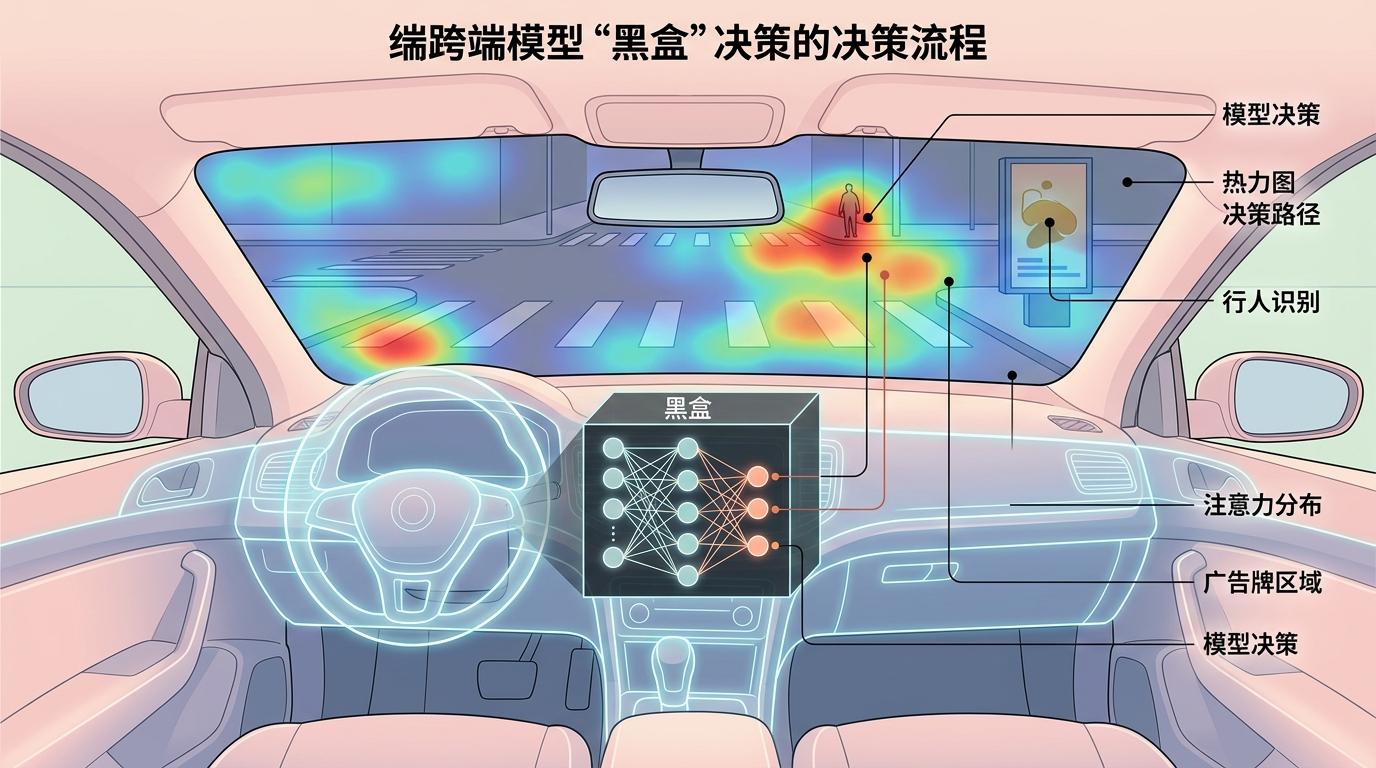
但这也带来了新的挑战:端到端模型是个“黑盒”,你不知道它为什么做出某个决策。比如它突然刹车,可能是识别到了远处的行人,也可能是把路边的广告牌当成了障碍物。为了破解这个黑盒,研究者们正在用“热力图”等可视化工具,让模型的决策过程变得可见:你能看到它在处理画面时,重点关注了哪些区域,就像看老司机开车时的视线落点。
还有一个更现实的问题:数据隐私。每辆车收集的驾驶数据里,可能包含车主的路线、习惯等敏感信息。现在的解决方案是“联邦学习”——让模型在本地车机上训练,只把学到的“经验”传到云端,而不是上传原始数据,既保护了隐私,又能让模型持续进化。
很多人担心自动驾驶会取代人类司机,但从数据看,它更像人类司机的“完美补全”。人类容易疲劳、分心、情绪化,而端到端模型永远保持冷静,能360度无死角观察环境,反应速度是人类的10倍以上;但在一些需要创造力的场景——比如突然遇到道路施工需要临时借道——人类的灵活性还是更胜一筹。
现在的自动驾驶系统,大多采用“人机协作”的模式:在高速、环路等简单场景下,系统全权接管;在城市道路、复杂路口等场景下,人类司机随时准备介入。这种模式下,事故率能降到人类的1/10,因为它把人类的优势和机器的优势结合在了一起。
当然,它也不是万能的。在极端天气——比如暴雨导致摄像头模糊——或者完全没有道路标线的荒野,端到端模型的表现会大打折扣。这也是为什么现在的系统都配备了冗余设计:摄像头失效了,还有雷达;主系统出问题了,备用系统能立刻接管。
当我们谈论“10倍安全”时,我们谈论的不是一个完美的机器,而是一种全新的学习方式:让汽车从真实世界中学习,而不是从工程师的图纸里学习。
端到端神经网络的真正价值,不是让汽车变得比人类更聪明,而是让它变得比人类更“可靠”——不会因为熬夜开车而反应迟钝,不会因为看手机而错过红灯,不会因为情绪激动而猛踩油门。
数据喂大的模型,终将补全人类的短板。 未来的道路上,人和机器不是对手,而是搭档,一起把事故率压得越来越低,让每一次出行都更安心。