对抗知识焦虑,从看懂这条开始
App 下载
大模型正在亲手训练替代自己的小模型
垂直领域创业|算力资源|小模型训练|人类投票数据集|Arena ML|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载垂直领域创业|算力资源|小模型训练|人类投票数据集|Arena ML|大语言模型|人工智能
2026年3月的一个播客里,Arena ML的两个研究员吵到面红耳赤。Derry攥着手里5600万张人类投票的数据集,坚持AI的未来属于通才大模型——那些吞掉整个互联网数据、烧光亿级美元算力的庞然大物,能写代码能搞科研,像个无所不能的瑞士军刀。Evan却拍着桌子反驳:创业公司拿不到GPUs,根本玩不起这场游戏,只有把模型钉死在某个垂直领域,才能在巨头的夹缝里活下来。没人想到,这场争论的最终落点,不是谁赢了谁,而是一个更惊悚的事实:大模型正在亲手训练出替代自己的小模型。
你可以把大模型理解成读遍了全世界图书馆的学霸,上知天文下知地理,但让他算个公司财报的精准数据,未必比专门学了十年会计的实习生快。Evan给通才大模型的定义直白得像大白话:参数量动辄上千亿,训练数据是整个互联网的边角料,烧的钱能买下半条街的服务器,换回来的是「给啥活都能搭把手」的通用能力。
而专精小模型,就像把人送进了职业技术学校——只学Excel函数的精准运用,只啃医疗病理的切片数据,训练成本可能只有大模型的千分之一,但在自己的一亩三分地里,能把大模型甩出去一条街。
这早已不是技术参数的差异,是两条完全不同的赛道。大模型的玩家是手握GPU集群的科技巨头,小模型的阵地是开源社区和拿着几十万天使轮的创业公司。一边押注「通用即正义」,一边坚信「专精才是活路」,中间隔着的,是算力、数据和商业逻辑的天堑。
前两年市面上冒出来二三十家「Excel AI」创业公司,有的专攻函数生成,有的擅长数据可视化,各有各的生存空间。直到Claude推出了Excel集成——那个通才大模型只是伸了个触角,整个赛道瞬间就凉了。Evan把这比作Agar.io里的泡泡:大泡泡越胀越大,小泡泡的生存空间被挤得只剩缝隙。
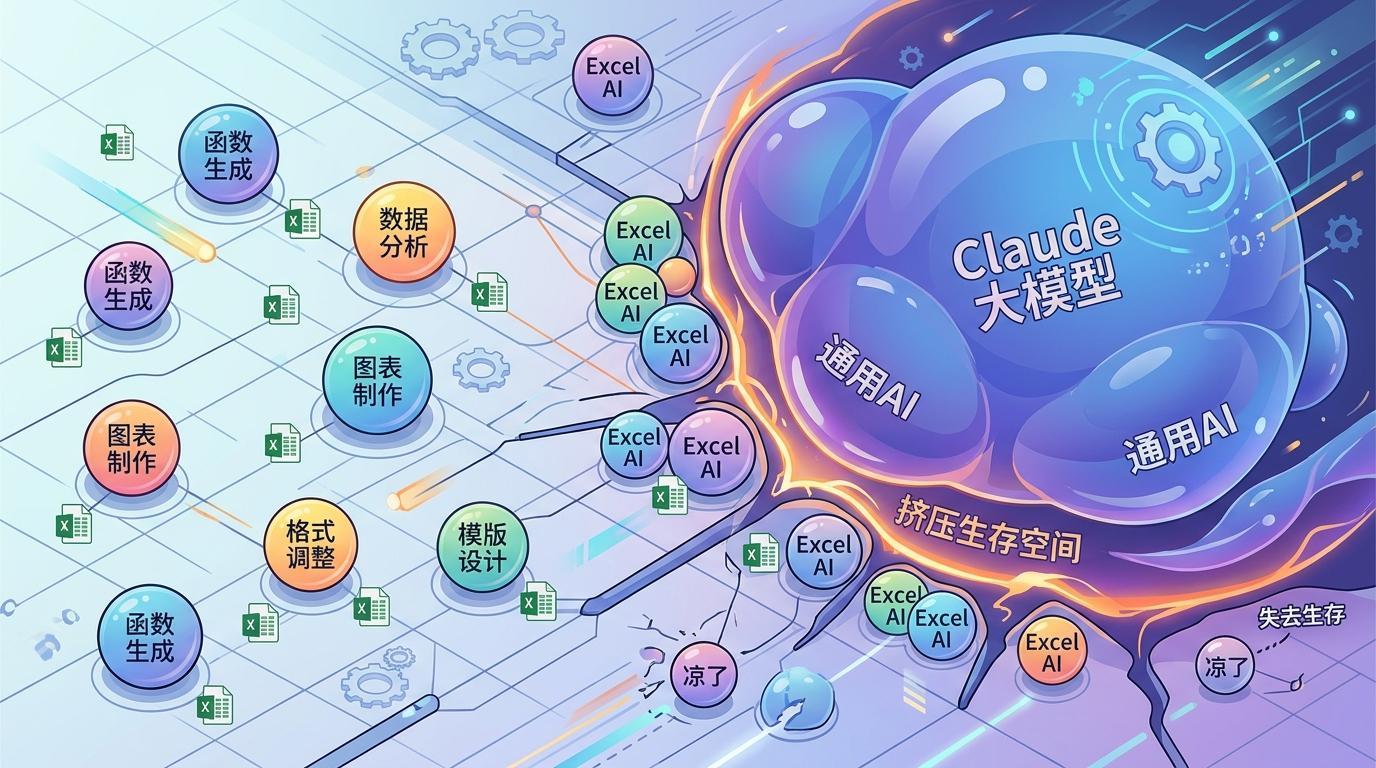
Derry曾举过一个病理图像分析的例子,说这是小模型的天然领地——数据专有、任务垂直,大模型根本插不进来。但Evan的回答像一盆冷水:现在确实是小模型的地盘,但等大模型学会自己训练小模型呢?
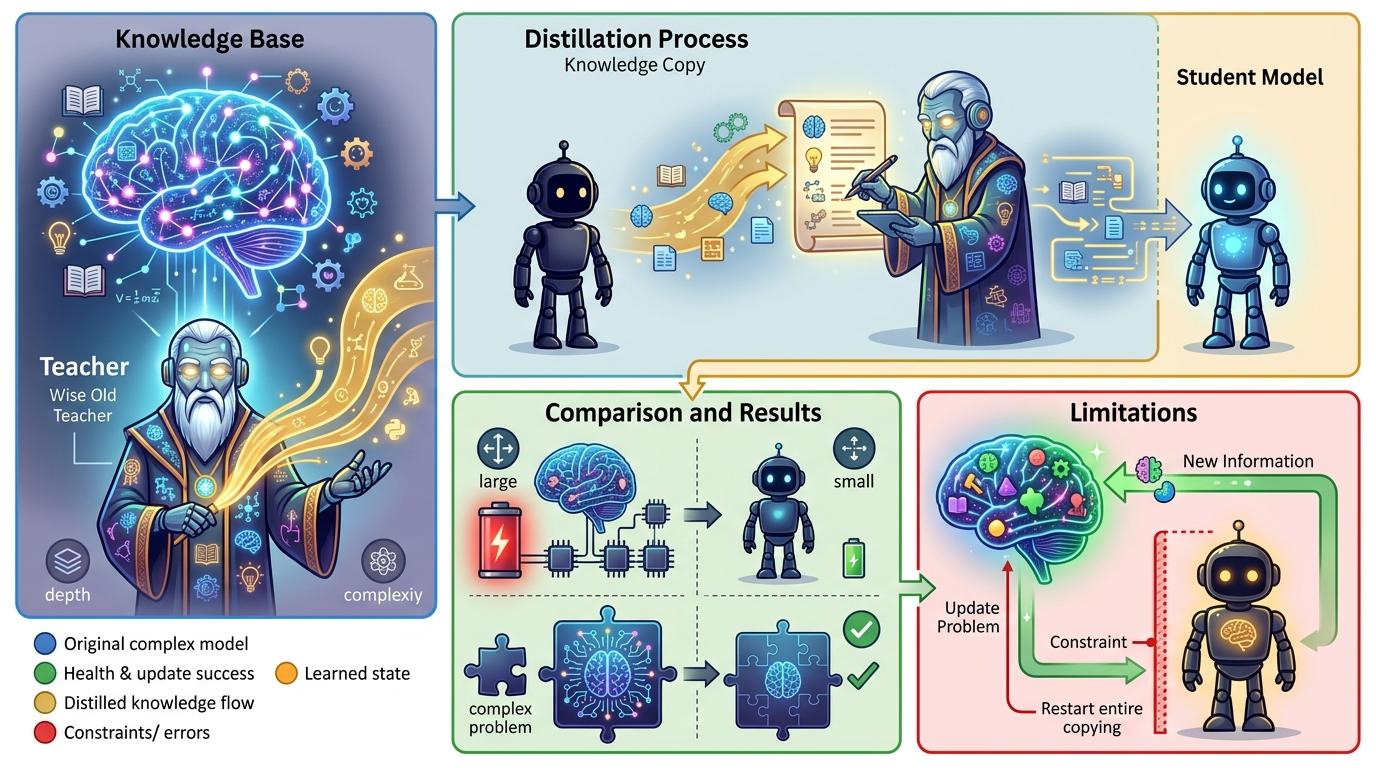
这不是科幻。大模型已经能生成高质量的垂直领域数据,用这些数据去「蒸馏」小模型——就像老师把自己的知识浓缩成笔记,学生靠笔记就能快速掌握核心能力。创业公司辛辛苦苦调出来的小模型,可能只是大模型花几分钟生成的「精简版」。更要命的是,当大模型的推理成本降到比小模型还低时,小模型最后一条护城河也会被冲垮。
你可以把「蒸馏」理解成一场知识的COPY:大模型是那个读了万卷书的老师,把自己的解题思路、知识框架,用小模型能听懂的语言写出来,小模型照着学,就能拥有接近老师的能力,却只需要老师十分之一的饭量。但问题是,老师的知识更新了,学生就得重新学——小模型的天花板,从一开始就被大模型攥在手里。
争论到最后,两人聊起了一个玄乎的东西:「大模型气质」。不是看参数量有多大,而是你和模型对话时,能感觉到它不是在背答案,而是在「思考」——遇到刁钻的问题不会绕圈子,能给出逻辑通顺的解法,甚至会「举一反三」。
Evan说,这种气质来自干净的预训练数据和轻触式的后训练。有些模型为了在排行榜上刷分,用高强度的后训练把模型「掰」成了只会答固定题目的机器,换个场景就懵圈。而那些预训练扎实的模型,只需要轻轻引导,就能在陌生场景里游刃有余——就像一个真正的学霸,换了个考场也能拿高分。
这其实戳中了小模型的另一个痛点:就算在垂直领域能超过大模型,也很难拥有这种「灵活的智慧」。小模型更像个熟练工,重复任务做得快,但遇到新问题,还是得靠大模型的「底层智识」。
Evan最后给还在做小模型的人提了个建议:别想着打败大模型,要在大模型不愿意做的地方找活路——比如数据不出本地的隐私场景,比如需要毫秒级响应的边缘设备。
其实这场争论从一开始就没有赢家。大模型和小模型的未来,从来不是非此即彼,而是共生共存。大模型负责开疆拓土,小模型负责落地生根;大模型是那个站在山顶的瞭望者,小模型是在山脚下开垦的农夫。
通用打底,专精落地,才是AI的未来。
就像这个世界既需要能上天的火箭,也需要能耕地的拖拉机——没有高低之分,只有分工不同。而那些还在夹缝里挣扎的小模型,终会明白:它们的对手从来不是大模型,而是如何在大模型的阴影里,找到自己不可替代的位置。