对抗知识焦虑,从看懂这条开始
App 下载
AI看视频流:少存68%内容,还能快10倍回答
响应速度提升|数据压缩|复旦大学|视频流处理|HERMES系统|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载响应速度提升|数据压缩|复旦大学|视频流处理|HERMES系统|多模态视觉|人工智能
当你盯着直播看球赛,突然有人问“刚才谁进球了”,你不用回放整段直播,就能立刻说出答案——这是人类的本能:把刚发生的画面放在“注意力前台”,把关键的进球瞬间藏进长期记忆。但对AI来说,这曾是个不可能的任务:要么把所有画面都存进GPU导致显存爆炸,要么存得太少答不上来,要么要等半天检索完历史才能开口。
直到复旦大学、上海创智学院和新加坡国立大学的团队拿出了HERMES。这套系统能在砍掉68%视频数据的前提下,把AI回答的响应速度提快10倍,甚至理解准确率还能更高。它到底是怎么让AI学会像人一样“记视频”的?
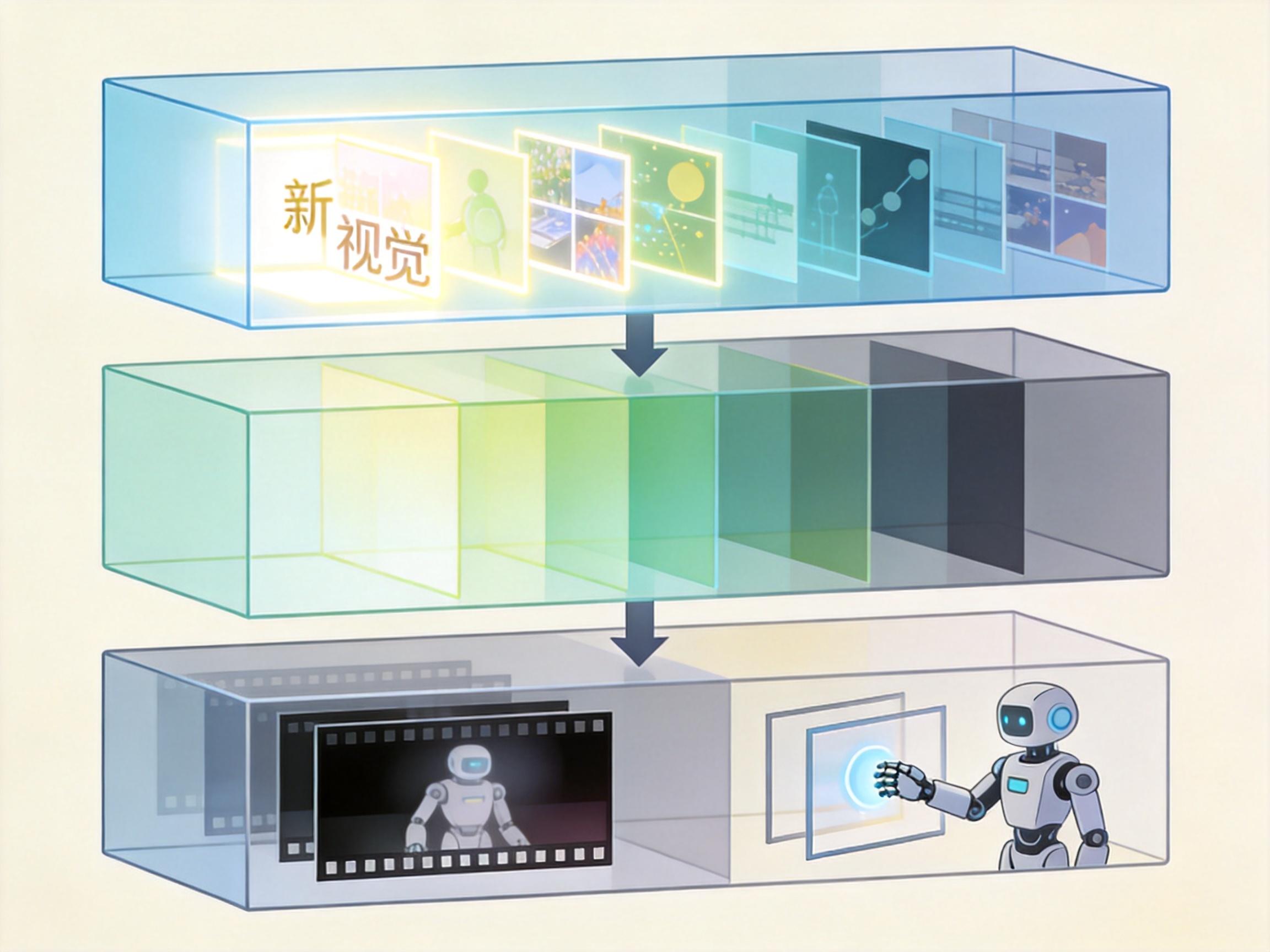
要理解HERMES的厉害,得先明白AI处理视频流时的尴尬。传统离线视频理解是“先存后看”:整个视频给过来,AI挑几帧采样分析就行。但流式视频是“边看边存”——直播、监控、机器人视角,画面一帧接一帧涌进来,用户什么时候提问、问什么全是未知。
这就把AI逼进了三难:要记得住关键信息,就得占更多GPU显存;要实时回答,就不能等检索历史;要显存不爆炸,就得删内容,但删多了又答不对。之前的解法要么是把历史视频存到外部硬盘,提问时再慢慢调回来,延迟高到能让人睡着;要么是粗暴压缩缓存,常常把关键帧也给删了,结果就是“一问三不知”。
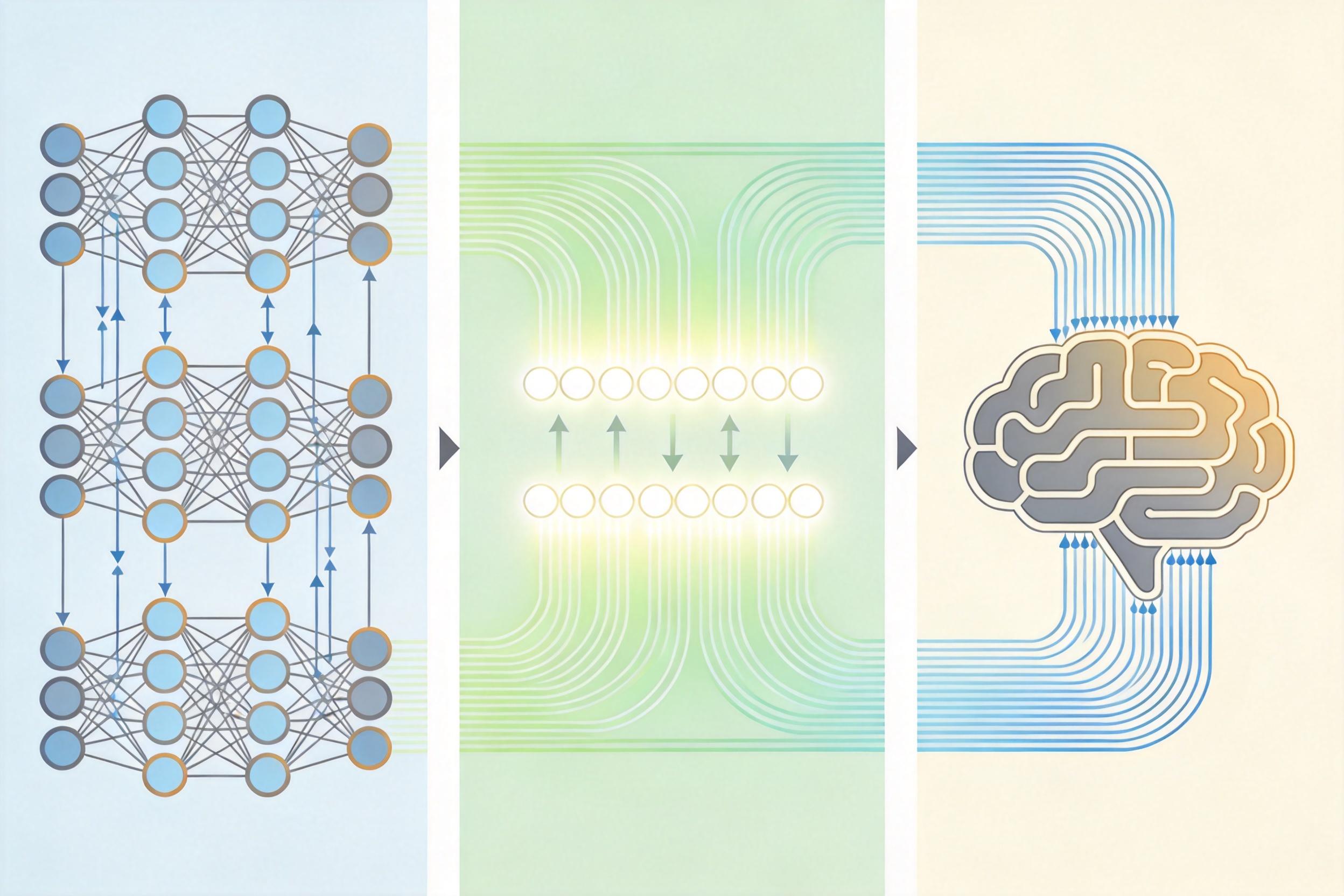
HERMES的破局点,是把AI里一个叫KV Cache的东西重新定义了——这本来是AI推理时临时存数据的“草稿本”,团队把它改成了模拟人类记忆的三层系统。
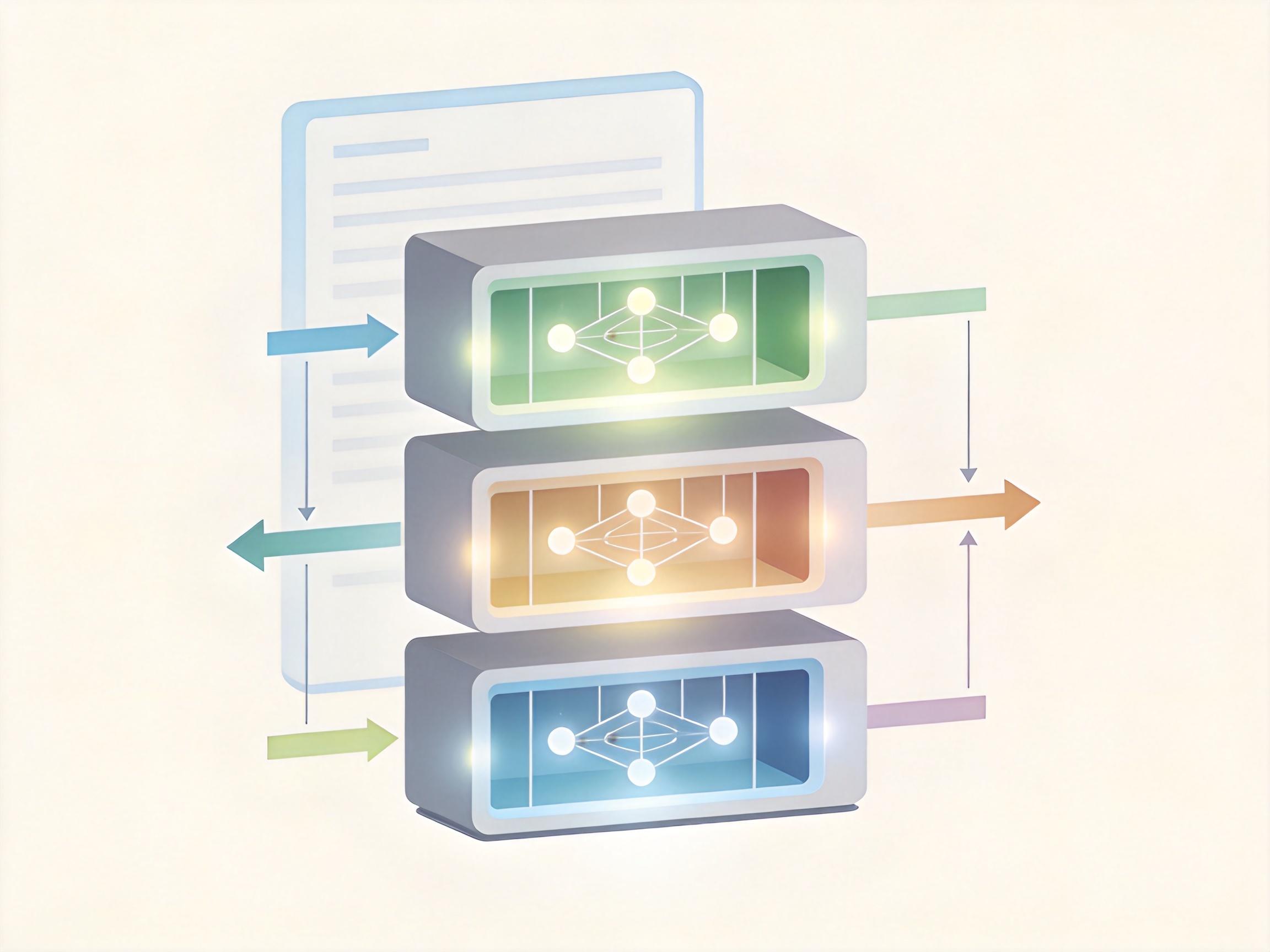
团队先做了个有意思的观察:AI的Transformer模型不同层,本来就有不同的“注意力偏好”——浅层爱盯最新的画面,中层会平衡新旧信息,深层则会盯着那些关键的“锚点帧”,比如进球瞬间、机器人拿起零件的时刻。这不正好对应人类的感官记忆、工作记忆和长期记忆吗?
HERMES就顺着这个天然分工,给KV Cache做了三层管理:
光分层还不够,团队加了两个关键补丁:一是跨层记忆平滑,让深层的关键信息能同步给浅层,避免不同层“记岔了”;二是位置重索引,解决视频太长导致的索引溢出问题,保证AI不会“越记越乱”。最关键的是,这套系统不用额外训练,直接就能插到现有大模型上用。
实验数据把这些设计的优势拍得明明白白:在StreamingBench等流式视频基准测试中,HERMES用Qwen2.5-VL-7B模型时,只用到原来32%的视频token,准确率却比基座模型高了6.13个百分点;在开放式问答任务里,最高能提分11.4%。
速度上更是夸张——首个token生成时间(TTFT)最高能快10倍,比如256帧输入时,HERMES的TTFT稳定在28毫秒左右,相当于用户刚问完,AI就开始回答了。而且不管视频流多长,它的显存占用都保持恒定,不会像传统方法那样看几个小时就把显存撑爆。
有意思的是,团队还在离线视频任务上测了HERMES,发现它的表现居然也和基座模型持平甚至更好——这说明这套分层记忆逻辑,不止能应付流式场景,还能通用到长视频理解里。
当我们谈论AI理解视频,过去总在想“怎么让它看得更全”,但HERMES给了另一个思路:让AI学会“怎么记才对”。就像人类不会记住每一秒的画面,只会把关键线索分层存进脑子里,AI也不需要当一个“硬盘”,而是要做一个会筛选信息的“观察者”。
记忆的本质不是存储,而是选择。这句话放在AI身上同样成立。未来在智能安防、机器人监控、实时视频助手这些场景里,我们不需要能存下所有画面的AI,需要的是能像人一样,盯着关键信息、立刻给出答案的AI——而HERMES,就是往这个方向迈的关键一步。