对抗知识焦虑,从看懂这条开始
App 下载
多模态AI能推理了,但还没学会不犯错
语音图像转换|3D壁纸生成|空间理解|统一语义空间|跨模态推理|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载语音图像转换|3D壁纸生成|空间理解|统一语义空间|跨模态推理|多模态视觉|人工智能
当你对着手机说“把这张风景照做成3D壁纸,再配一段符合意境的文案”,AI能在10秒内完成从图像到三维模型再到文本的跨模态转换——这不是科幻片,是2026年已经实现的日常。但很少有人知道,这些看似流畅的操作背后,AI正卡在从“能感知”到“会思考”的关键门槛上。为什么能同时看懂图像、听懂语音的AI,连“把杯子放到桌子左边”这种简单空间推理都会出错?
要理解这个矛盾,得先搞懂多模态AI的核心逻辑:它不是把图像、文本、音频的模型简单拼接,而是要在一个统一的语义空间里,让不同模态的信息“说同一种语言”。打个比方,就像把中文菜谱、英文视频、法语烹饪教程翻译成同一种通用语,让AI能同时看懂步骤、听懂讲解、认出食材。这个统一空间的构建,靠的是跨模态注意力机制——AI会自动找出图像里的“杯子”和文本里的“杯子”是同一个东西,再把它们的特征绑定在一起。
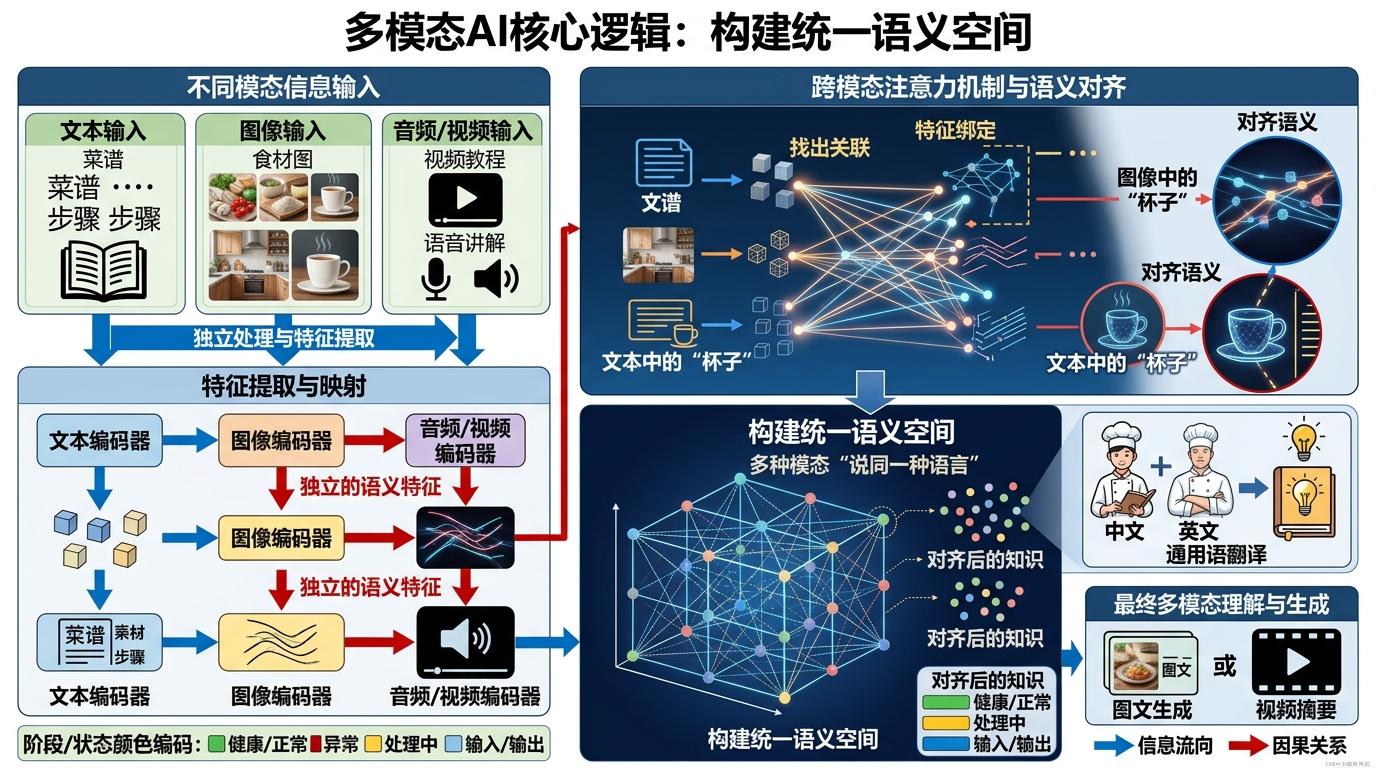
但这种绑定还停留在“感知对齐”的层面,一旦涉及需要多步推理的复杂任务,AI的弱点就暴露无遗。比如让它设计一个模拟电路,它能画出电路图,却算不对电压参数;让它处理多模态长文本,前面提到的“红色按钮”,到后面就会被它当成“蓝色开关”。这是因为当前的多模态推理大多用链式结构,一步错就会步步错,而且它没办法像人类一样,在推理到一半时“回头检查”。更关键的是,AI对空间关系、因果逻辑的理解,还停留在统计关联上,没有真正建立起“物理世界的常识”。
现在的研究者们正在尝试用更灵活的推理拓扑解决这个问题——比如把链式推理改成树状,让AI能同时探索多个推理路径,或者用图结构把不同模态的信息节点连接起来,像人脑的神经网络一样传递信息。还有团队用强化学习训练AI“自我纠错”,让它在推理出错时能自动调整路径。但这些方法都面临同一个难题:计算成本的暴涨。要支撑树状推理,模型的算力消耗是链式的3到5倍,这对普通开发者来说几乎是不可承受的。
另一个容易被忽略的挑战是数据。训练多模态AI需要大量对齐准确的跨模态数据,比如标注了“杯子在桌子左边”的图像和文本对,但现实中这样的数据少之又少。很多数据集里的模态对齐只是“大概匹配”,比如一张风景照配一句“美丽的风景”,这种模糊的对齐训练出来的AI,自然做不出精准的推理。而且数据里的偏见还会被放大——如果训练数据里的杯子大多在桌子右边,AI就会默认杯子应该在右边。
多模态AI的未来,不是要做一个能同时处理所有模态的“超级模型”,而是要做一个能像人类一样,用多模态信息辅助思考的“智能伙伴”。它不需要完美,但要能在出错时给出明确的推理过程,让人类能快速修正;它不需要记住所有知识,但要能像查资料一样,通过检索增强自己的推理能力。当AI能把“感知到的信息”真正变成“能思考的知识”,它才算是跨过了从工具到伙伴的那道坎。
这一天不会太远,但在此之前,我们得接受AI的不完美——就像接受刚学走路的孩子会摔跤一样。毕竟,人类学会思考用了几百万年,给AI多一点时间,也给我们自己多一点耐心。