对抗知识焦虑,从看懂这条开始
App 下载
不用干净样本,AI靠土豆切片原理修复X射线图
AI图像修复|肺栓塞|低剂量CT|哈尔滨医科大学|HorusEye模型|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI图像修复|肺栓塞|低剂量CT|哈尔滨医科大学|HorusEye模型|大语言模型|临床诊疗技术|医学健康|人工智能
当医生盯着一张满是噪点的低剂量CT片时,可能正错过藏在模糊里的肺栓塞——这种致命疾病在原始低剂量图像里,只有3.3%的医生能揪出来。但2026年3月,哈尔滨医科大学、哈工大与KAUST的团队用HorusEye模型改变了这一切:它修复后的CT片,让80%的医生精准识别出病灶。更颠覆的是,这个AI根本不需要干净的图像样本当参考,它靠的只是一个被忽略的物理常识——就像你切土豆时,相邻两片的纹路永远连着,但每片上的泥点都是随机的。
你可以把CT扫描想象成切土豆:机器把人体切成一层层1毫米厚的“薄片”,堆叠成三维图像。这些薄片的结构是连续的——这一片有根血管,下一片肯定也有,只是位置挪了一点点;但扫描时产生的噪点不一样,它来自X射线光子随机撞向探测器,每一片的噪点都是独立的,和上下片毫无关系。
HorusEye就抓住了“结构连续,噪声不连续”这个关键点。它设计了一个“猜中间片”的游戏:给AI看第h-1和h+1张带噪切片,让它预测中间的第h张。因为结构是连续的,AI能精准猜出血管、骨骼的位置;但噪声是随机的,AI根本猜不出来,所以它给出的预测片天然就是“降噪版”。
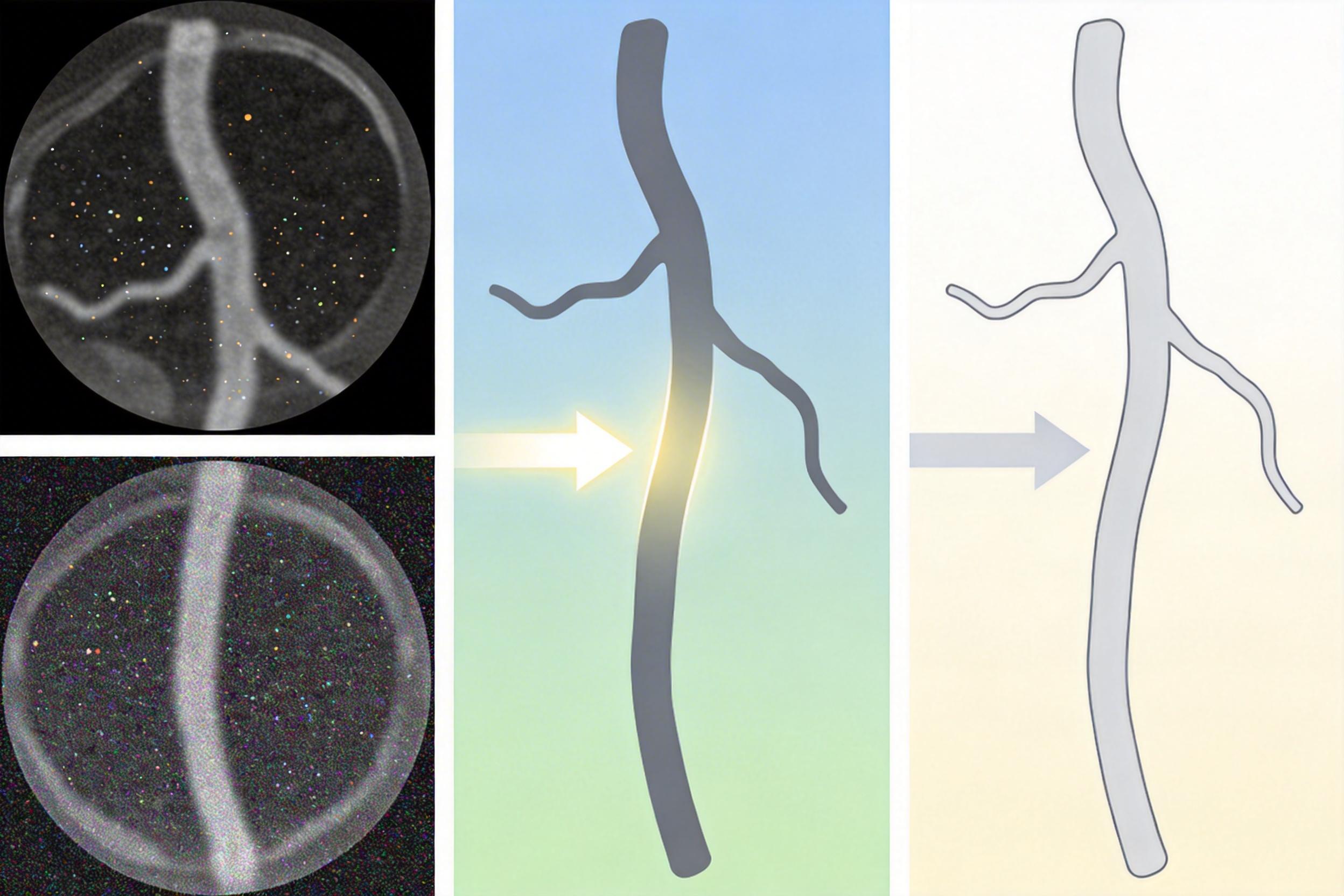
用真实的第h张切片减去AI的预测片,得到的残差就是纯粹的真实噪声。就像你把土豆上的泥点抠下来,得到了一份“泥点样本”——这一步完全不需要干净图像当参照,AI自己从数据里“挖”出了训练素材。
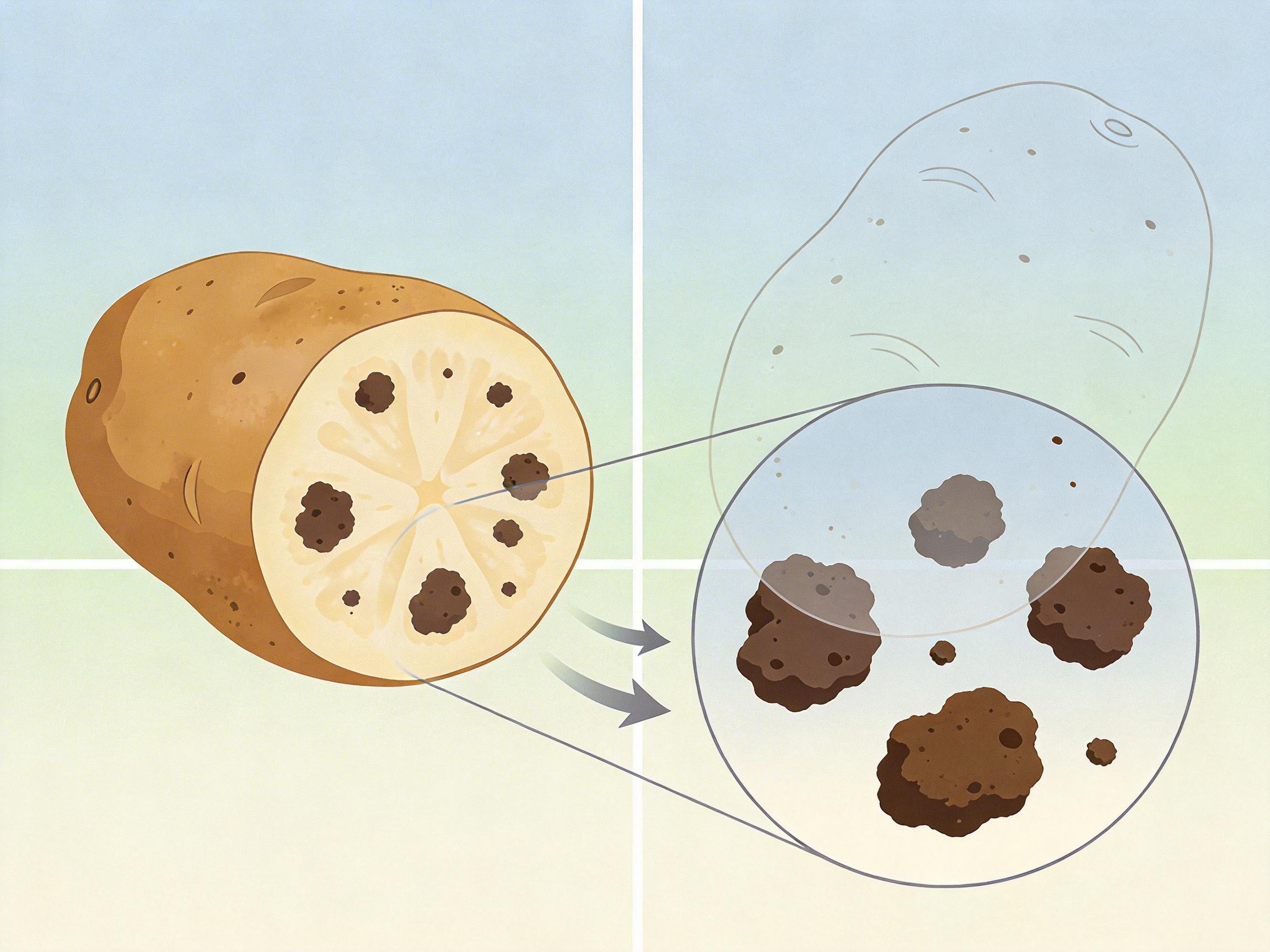
光有噪声样本还不够,得让AI学会“擦泥点”。HorusEye的第二步,是用抠出来的真实噪声去“污染”相对干净的图像——比如高剂量扫描的图像,或者从海量数据里筛选出的质量较好的片,这样就造出了“带噪图-干净图”的伪配对数据。
接下来,AI用这些伪配对数据训练一个降噪自编码器,就像学擦土豆的手法:看到带泥点的土豆,就知道该怎么擦干净。最巧妙的是,这两步是循环的:降噪器练得越好,就能生成越干净的“预测片”,抠出来的噪声样本就越精准;噪声样本越精准,造出来的伪配对数据就越接近真实场景,降噪器就能练得更强。
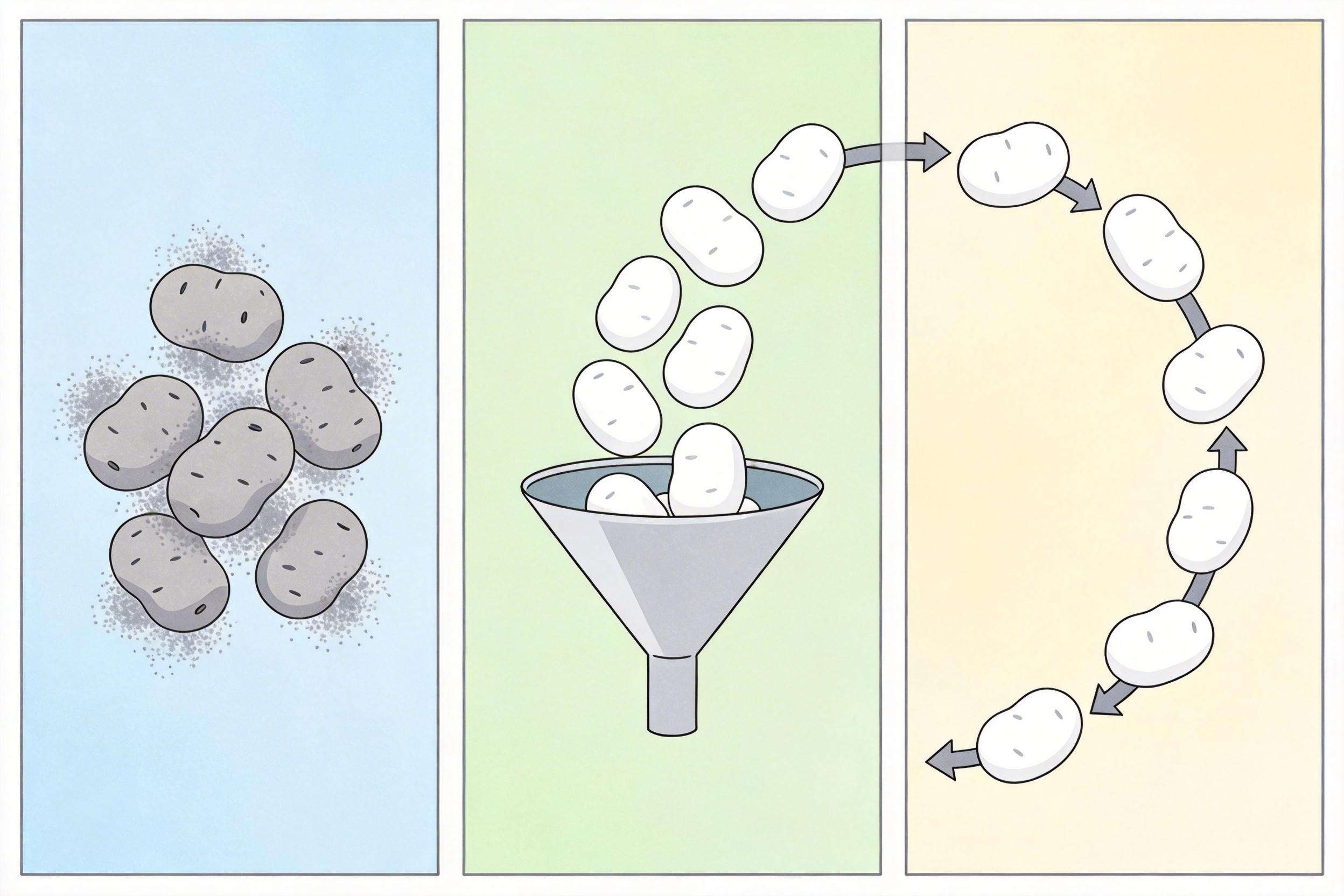
这个正反馈循环让AI越练越“懂”真实世界的噪声。它用1亿张跨模态X射线图像练出了扎实的基本功——从临床CT到科研用的微纳CT,什么噪点都见过,换个扫描设备、降个剂量,它也不会“水土不服”。
HorusEye的野心不止于去噪。它是一个“基础模型”——就像大语言模型能写文案也能算数学题,它靠预训练学到的X射线图像通用规律,能轻松适配各种修复任务:把模糊的低分辨率图像放大4倍、把5mm厚的切片“拆”成1mm的薄层、去掉金属假牙在CT里留下的条纹伪影……
要切换任务,只需要冻结预训练好的“大脑”(编码器),微调一下负责输出的“小手”(解码器)就行。在临床测试里,它修复的低剂量CT片,让10位资深放射科医生的评分追上了高剂量扫描的金标准;给下游AI诊断工具当输入,肺动脉静脉分割的准确率从70%跳到了88%,能识别的血管分支多了90%。
当然它也有局限:遇到骨小梁这种和噪声纹理接近的细微结构,偶尔会误当成噪声擦掉;面对极端低剂量(比如常规剂量的1%),性能也会打折扣。而且它至今还是个“黑箱”——医生只知道它修图修得好,不知道它是怎么判断哪是噪点哪是病灶的。
HorusEye的本质,是让AI放下人类给它预设的“噪声模型”,转头去看数据自己的规律——这是医学影像AI的一次转向:从“让AI学人类总结的规则”,变成“让AI学自然本身的逻辑”。
它不止是修好了一张张CT片,更重要的是,它证明了在医学这种数据稀缺又要求极高的领域,自监督基础模型能走通一条新路——不用依赖昂贵的标注数据,不用预设复杂的规则,只要抓住领域里最本质的物理规律,AI就能学会解决一整个赛道的问题。
未来的医学影像AI,或许会像HorusEye一样,不再是人类规则的执行者,而是自然规律的学习者。