对抗知识焦虑,从看懂这条开始
App 下载
ViT高分辨率推理瓶颈被破:快52倍还更准
萨格勒布大学|SPAR训练方法|高分辨率推理|视觉Transformer|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载萨格勒布大学|SPAR训练方法|高分辨率推理|视觉Transformer|多模态视觉|人工智能
当你让AI识别一张高清壁画里“戴帽子的猫”时,它要么像蜗牛爬一样慢,要么把猫耳朵当成帽子——这就是ViT(视觉Transformer)卡在高分辨率密集预测任务里的死局:要精度就得用滑窗反复计算,要速度就得接受“近视眼”式的错误。直到萨格勒布大学的团队拿出了SPAR:一个不用改模型结构的训练方法,让AI一次扫完高清图,速度和单次推理一样快,精度却比慢工出细活的滑窗还高,甚至快了52倍。这到底是怎么做到的?
你可以把ViT看成一个只见过邮票的人——它预训练时只看224×224这类低分辨率图,就像用小格子坐标纸记位置。突然给它一张壁画大的图,它只能把坐标纸强行拉大,结果格子变形,连“猫在哪个位置”都认不清,这就是单次推理:快是快,精度直接跳水。
那给它配个“放大镜”?就是滑动窗口:把大图切成邮票大小的块,每块都用熟悉的低分辨率处理,最后拼起来。这就像让邮票专家蹲在壁画前,一格一格挪动放大镜看,精度上去了,但每挪一次就要重新算一遍,计算量直接爆炸——步长越小,看得越细,速度就越慢,慢到根本没法实用。
之前所有人都以为这是鱼和熊掌的选择题:要快就别要准,要准就别要快。
SPAR的核心逻辑简单到像找了个学霸当家教:用滑窗这个“慢老师”的经验,教单次推理这个“快学生”做题。
具体来说,先让慢老师用小步长滑窗把高清图仔仔细细看一遍,生成一张标注着所有细节的“标准答案”特征图——这张图里,每一个像素的上下文信息都被反复验证过,准确但耗时长。然后让快学生直接看整张高清图,输出自己的特征图,再用均方误差当“批改标准”,让学生的图和老师的图越像越好。
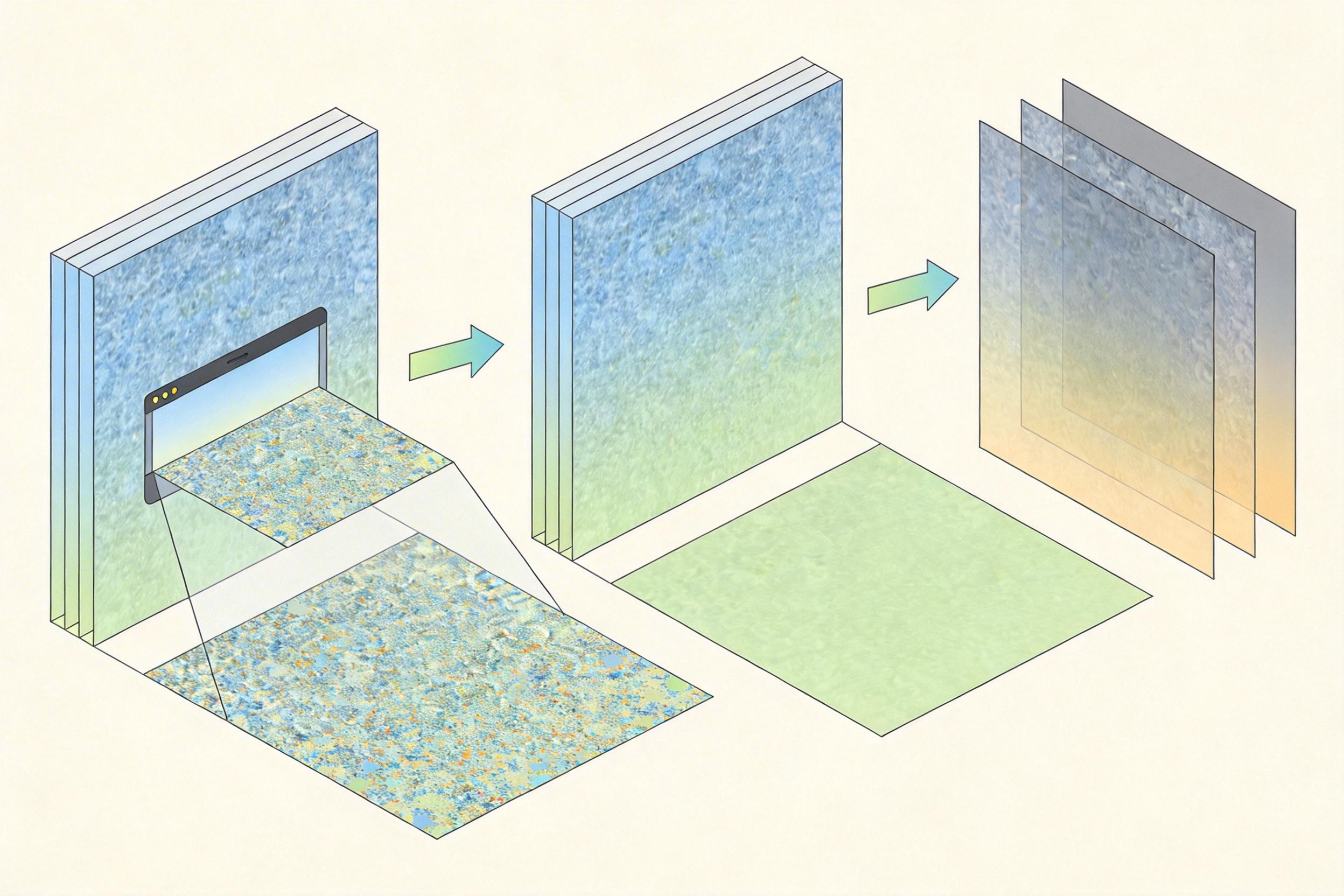
最聪明的地方在于,它不用让学生重新学一遍所有知识,只需要微调ViT最后两层——这两层负责理解全局语义,也是处理非训练分辨率时最“懵”的部分。就像只需要教邮票专家学会看壁画的整体布局,而不是重新教他认猫。
训练时还会给学生看各种尺寸、各种长宽比的图,让它“见多识广”,不管是正方形的海报还是长条的横幅,都能一次看懂。
实验结果比预想的更惊人:学生不仅学会了老师的本事,还青出于蓝。在六个开放词汇分割数据集上,SPAR比单次推理的平均精度提升了6.7到10.5个百分点,甚至比慢老师的滑窗还高2.4个百分点。
为什么学生能超过老师?因为慢老师的滑窗特征图是一块块拼起来的,在窗口边界难免有缝隙和噪声,就像用邮票拼壁画,边缘总会有错位。而学生是一次看完整张图,学到的是更平滑、更连贯的全局特征,相当于直接看高清扫描件,自然比拼起来的邮票更清楚。

更关键的是速度:SPAR的推理速度和单次推理一模一样,比慢老师的滑窗快了52倍。相当于之前要花52分钟才能做完的题,现在1分钟就做完了,还考了更高的分。而且它对各种ViT模型都有效,不管是SigLIP、CLIP还是DINOv3,都能用上这招。
SPAR的出现,打破了人们对“模型性能和效率不可兼得”的固有认知。它没有搞复杂的结构创新,只是换了一种训练思路——用已经存在的“慢精度”,去喂出更高效的“快精度”。这背后其实是AI研究的一个新趋势:与其在模型结构上死磕,不如在训练方法上找巧劲。
改训练不改结构,这可能是AI落地的下一个突破口。毕竟对很多实际应用来说,能不能用、能不能快,比能不能达到理论上的最高精度更重要。好的AI,从来不是最快或最准的,而是刚好能用的。