对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶AI学会了:先做梦,再复盘
安全门槛|决策链|华为|上海交大|VLA-World模型|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载安全门槛|决策链|华为|上海交大|VLA-World模型|自动驾驶|人工智能
想象你在晚高峰的中环上跟车,前车突然踩了一脚急刹——你的大脑会在0.1秒内完成三件事:先预判“它要停”,再模拟“我追尾的画面”,最后果断踩下刹车。这是人类驾驶的本能,却是过去十年自动驾驶AI最难跨越的坎:要么只会“按规则推理”不会预判,要么只会“瞎想未来”不会判断风险。直到上海交大与华为的团队拿出了VLA-World模型,它第一次让AI完整复刻了人类“做梦-复盘”的决策链,把自动驾驶的安全门槛拉高了一个量级。为什么这个“闭环”能解决行业多年的顽疾?
过去的自动驾驶AI一直分裂成两个互不兼容的阵营:一派是擅长推理的VLA模型——像个能背出所有交规的学霸,能清晰解释“为什么要变道”,但对“后车会不会加速超车”这种动态预测一塌糊涂;另一派是擅长想象的世界模型——像个只会画未来场景的预言家,能生成10秒后的道路画面,却看不出画面里的行人正准备闯红灯。
这种割裂直接导致了现实中的安全隐患:VLA模型可能在复杂路口因“反应慢半拍”发生碰撞,世界模型可能因为“想错了未来”做出匪夷所思的决策。行业试过无数种缝合方法:给VLA模型加个预测模块,给世界模型套个推理外壳,但都因为“两张皮”的问题效果惨淡——就像让学霸去学画画,让预言家去背公式,两边的能力始终无法打通。
VLA-World的核心突破,是用一个“想象-反思”闭环把两个流派的能力焊在了一起。它的运行逻辑完全复刻人类驾驶的思考链:
首先,模型会先做一个“直觉预判”——基于当前路况预测0.5秒后的短期轨迹,这不是凭空瞎猜,而是基于实时感知数据的快速推导,相当于人类司机的“本能反应”。
接着是“做梦”环节:用这个短期轨迹当“剧本”,生成0.5秒后的多视角道路画面。这里的关键是,它不是生成随便什么未来,而是严格基于自己预判的动作来生成——就像你在脑海里模拟“我踩刹车后,前车和后车的位置变化”,每一个像素都和你的动作挂钩。
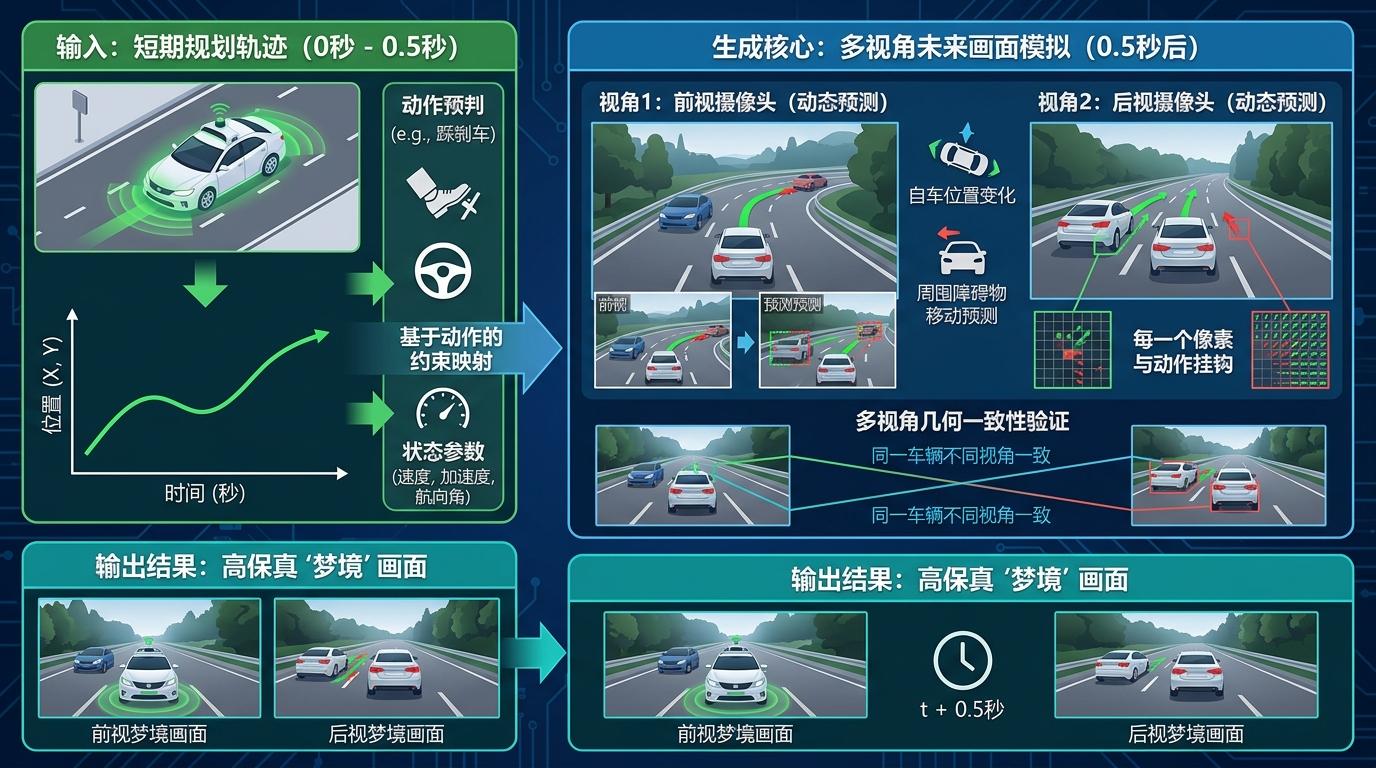
最关键的一步是“复盘”:模型会对着自己生成的未来画面做推理分析——识别画面里的行人、判断后车的距离、评估当前轨迹的安全性,再根据这些分析修正最初的短期轨迹,最终输出3秒后的长期规划。
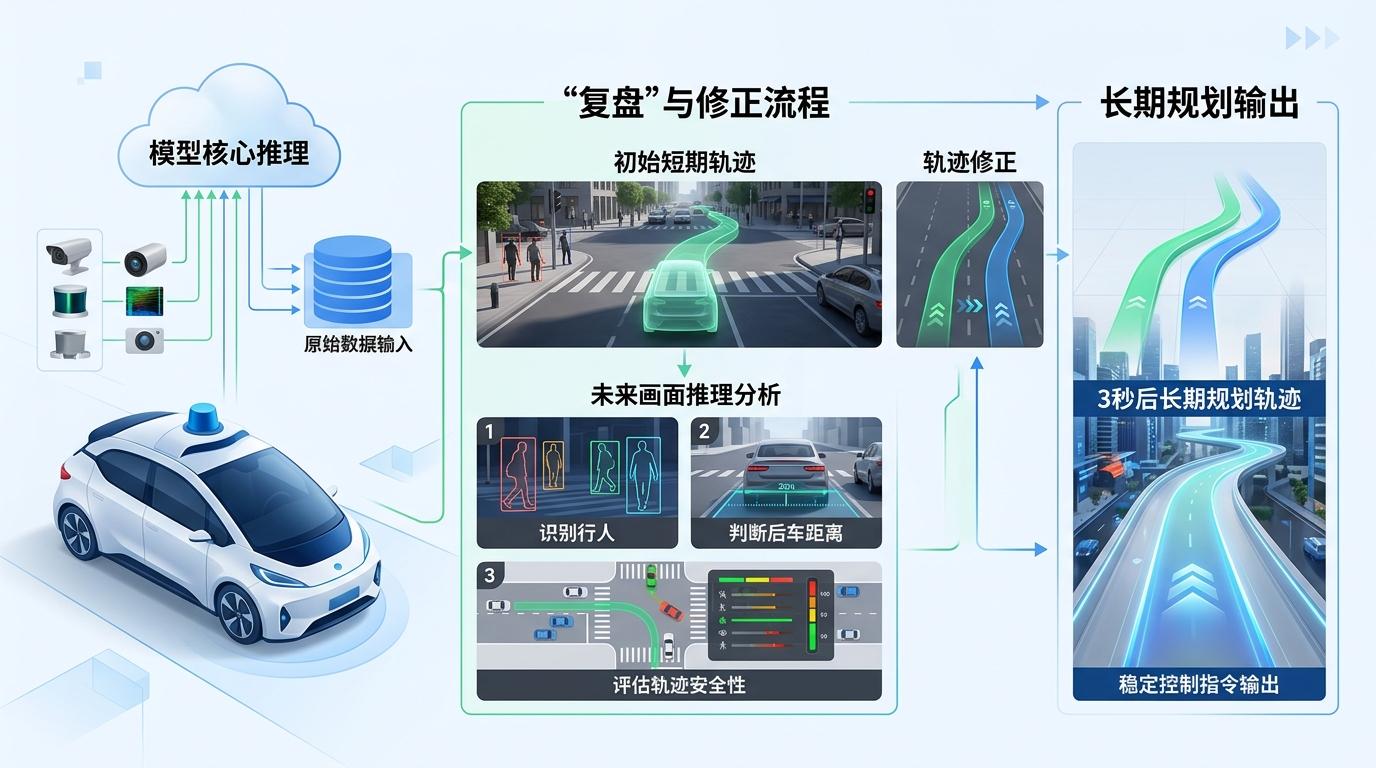
你可以把这个过程想象成:先凭直觉画一张草稿,再对着草稿反复修改,直到画出最安全的路线。而不是像之前的模型那样,要么直接交一张没有细节的推理答卷,要么画一张不知道要干嘛的未来画。
为了让这个闭环真正生效,团队设计了一套三阶段训练法:先用视觉预训练让模型“学会画画”,再用监督微调让它“懂交规”,最后用强化学习让它“学会自己改草稿”。每一步都精准对应能力的递进,没有任何冗余。
实验数据直接证明了这个闭环的力量:在nuScenes数据集的3秒轨迹预测任务中,VLA-World的碰撞率比当前最先进的FSDrive模型降低了27%;在高密度交叉口的极端场景测试中,碰撞率更是降低了近80%。
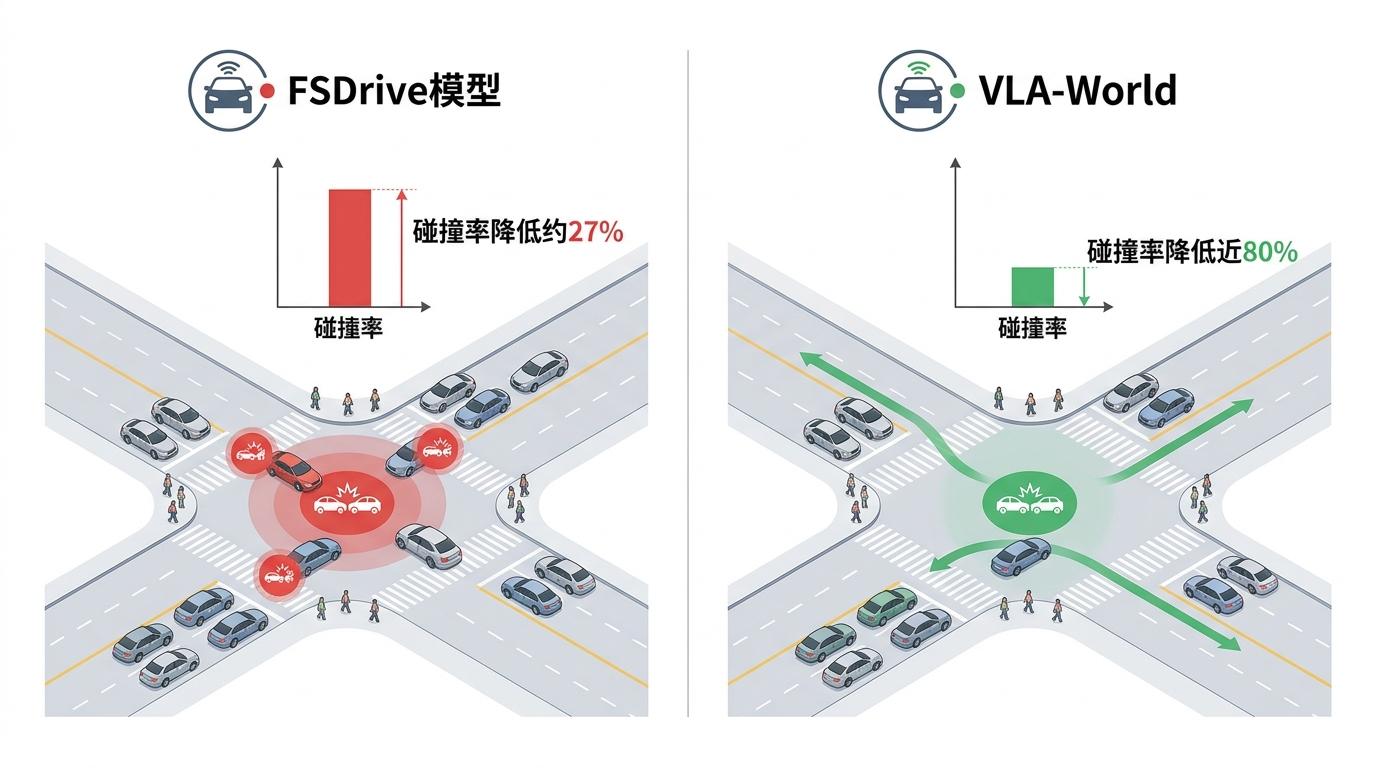
更有意思的是消融实验的结果——如果跳过“复盘”环节,只让模型生成未来画面,碰撞率会直接飙升3倍;如果用真实的未来轨迹代替模型自己的预判,性能反而会下降。这说明,模型自己“做梦”再“复盘”的过程,是不可替代的——就像人类不能靠别人的预判来开车,AI也必须学会自己对自己的决策负责。
当然,它也不是完美的:生成的未来画面偶尔会出现“幻觉”,比如把路牌看成行人;推理环节的深度也还停留在“识别风险”,而不是“模拟多种避险方案”。但这些都是可以通过迭代解决的技术问题,而它解决的“割裂”难题,是行业卡了多年的战略级瓶颈。
自动驾驶的终极目标,从来不是让AI“像机器一样开车”,而是让AI“像人类一样思考开车”。VLA-World的意义,不是又刷新了某个数据集的指标,而是第一次让AI拥有了“预判-评估-修正”的完整决策逻辑——这是从“执行规则”到“理解驾驶”的关键一步。
未来的自动驾驶AI,会在脑海里模拟出上百种可能的未来,再逐一评估风险,最终选出最安全的那条路。而我们今天看到的“做梦-复盘”闭环,就是这个未来的第一块拼图。
预判风险,比应对风险更重要。