23 天前
23 天前
你有没有见过这样的AI:能写通顺的文案,却画不出匹配的图;能识别照片里的猫,却理解不了“猫在笑”的文字描述。这不是AI笨,是它的“大脑”里正在发生一场隐秘的内战——处理文字和处理图像的神经通路,在争抢同一个参数的控制权,结果谁都干不好。
就在2026年ICLR大会上,一支团队拿出的Uni-X模型,用最朴素的“分家”思路解决了这个问题:让文字和图像在模型的两头各走各的路,只在中间的“大脑皮层”汇合。结果,只有30亿参数的它,在图像生成测试里干赢了不少70亿参数的前辈。这背后,藏着多模态AI卡了3年的核心死结。
要理解这场内战,得先搞懂梯度冲突——你可以把它想象成两个教练同时教一个运动员:一个让他练短跑爆发力,一个让他练马拉松耐力,运动员的肌肉在两种完全相反的训练指令下,只会越练越废。
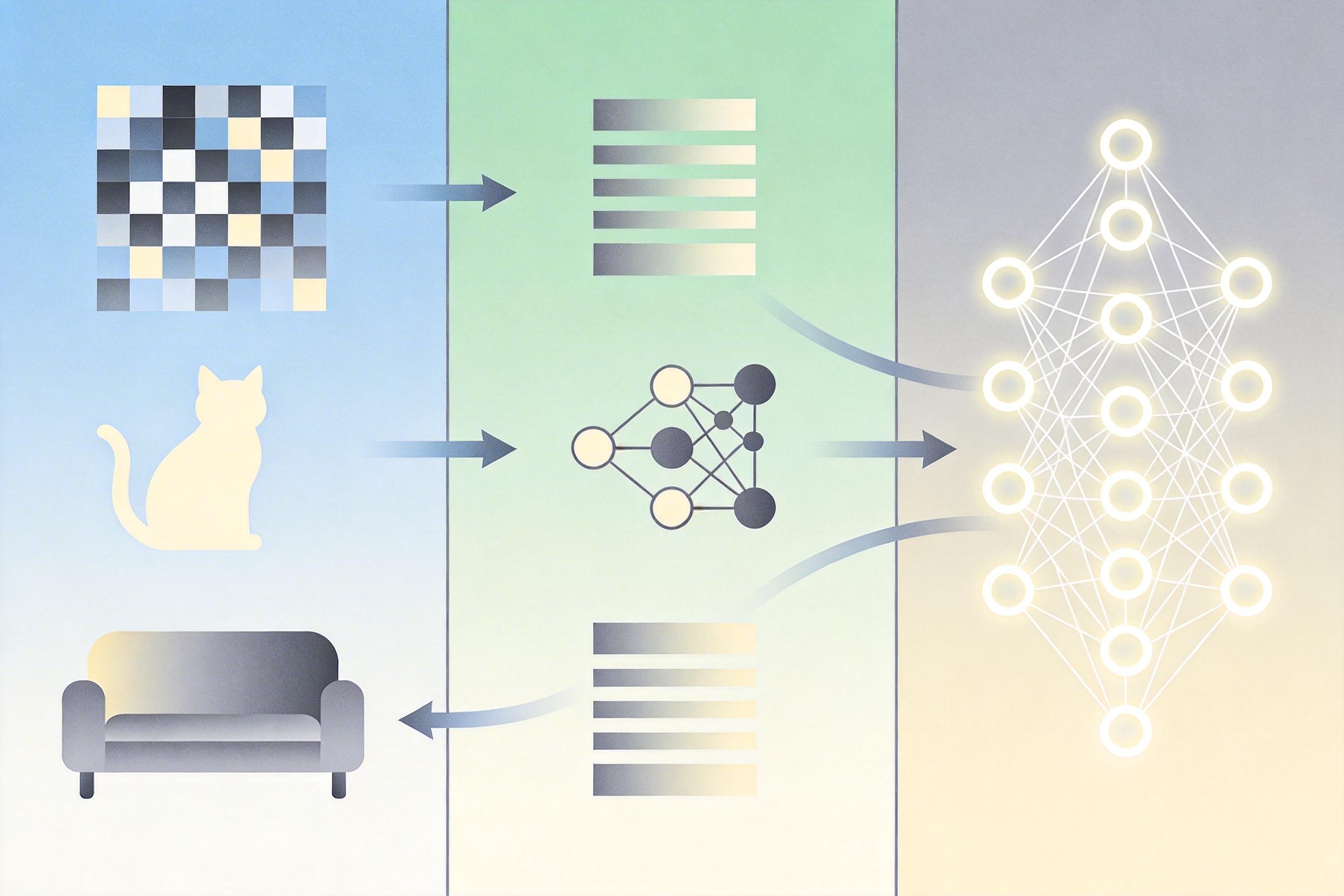
在多模态AI里,文字和图像就是这两个“教练”。文字是低熵的:每个字的出现都有明确的语法逻辑,比如“我吃饭”不能说成“饭吃我”,模型只需要学习这种有序的规律。但图像是高熵的:一张512×512的图会被转换成1024个视觉Token,每个Token的出现几乎没有固定逻辑,模型得学习像素间复杂的空间依赖——这难度相当于让写散文的人突然去解量子物理题。
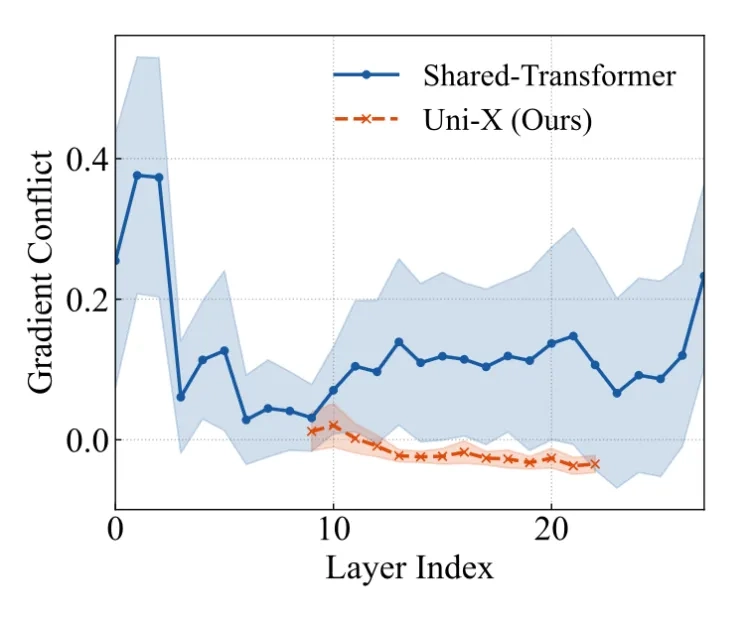
当用一个完全共享参数的Transformer同时处理两者时,就会出现诡异的梯度拔河:
研究者用余弦相似度量化了这种冲突:浅层和深层的梯度方向相似度不到0.3,相当于两个完全相反的向量在死拉硬拽。而Uni-X做的,就是把这两个“教练”的训练场彻底分开。
Uni-X的解决思路说穿了很简单:让文字和图像在模型的浅层和深层各走各的路,只在中间层共享参数——就像一个X形的路口,两头是专属车道,中间是公共换乘站。
你可以把这个过程拆成三步:
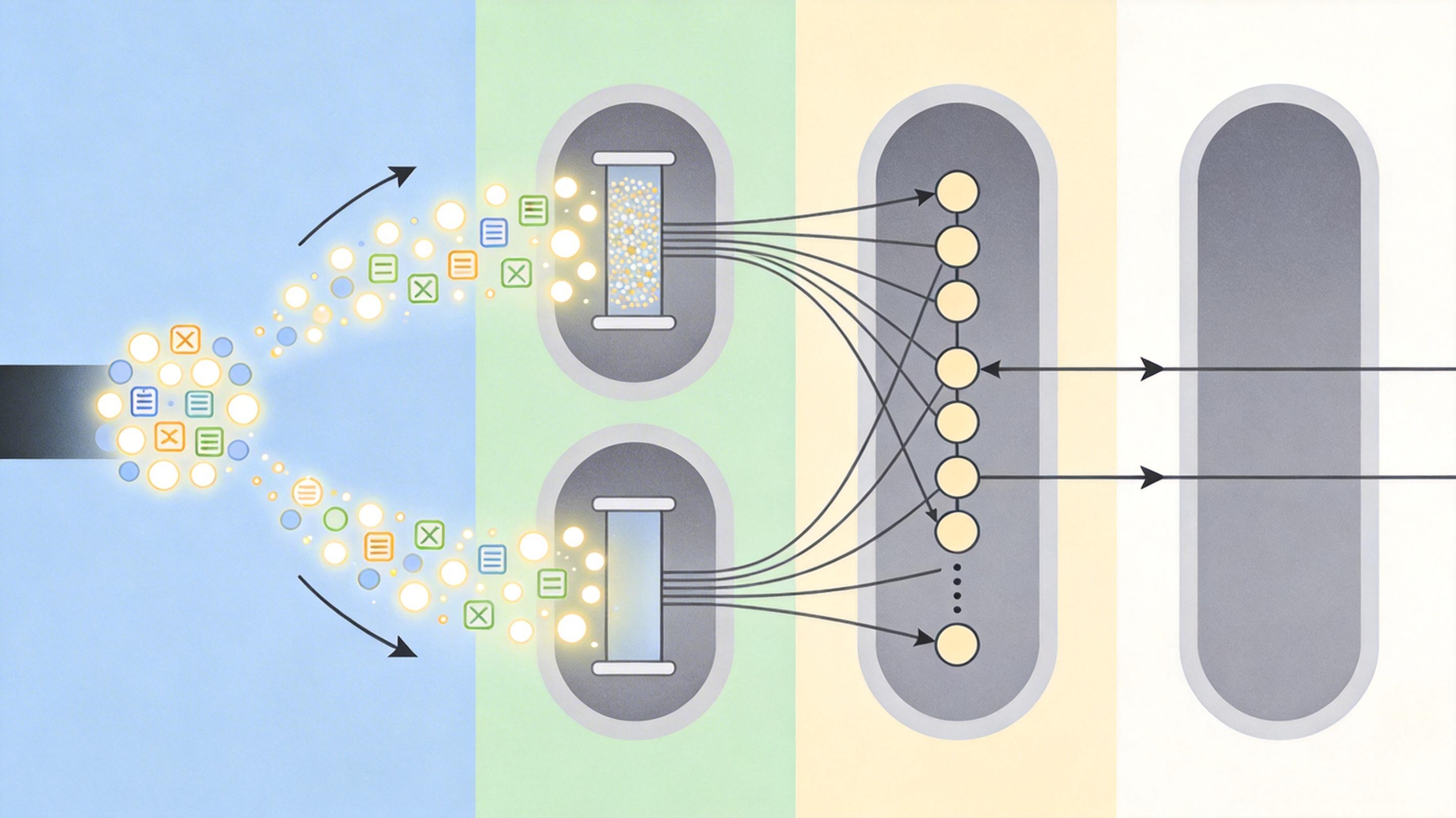
这种设计不止解决了冲突,还偷偷提升了效率:原本共享Transformer的自注意力计算复杂度是O((图像Token数+文字Token数)²),现在变成了O(图像Token数² + 文字Token数²),相当于把“两个人挤一条路”变成“两个人走两条路”,速度快了近30%。
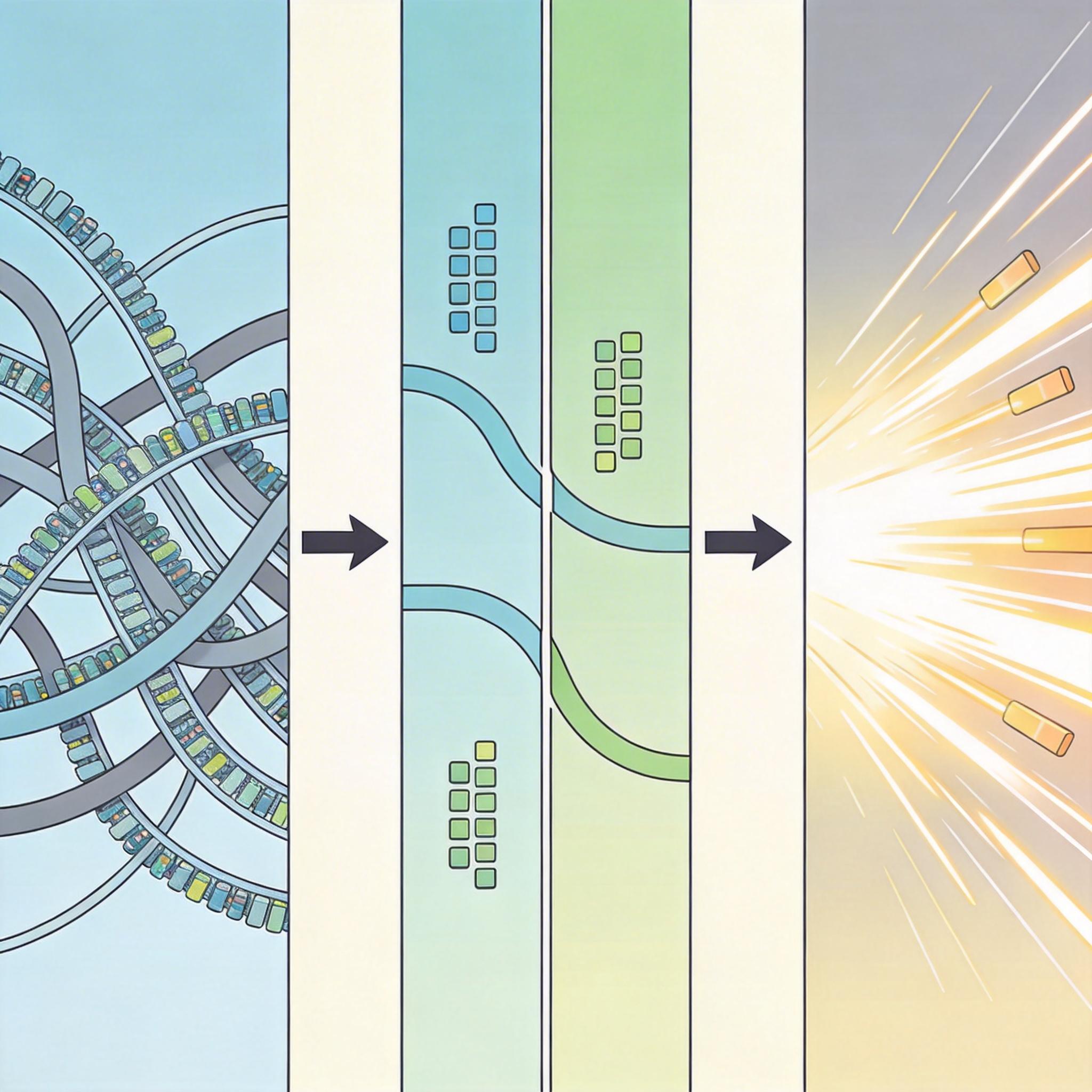
实验数据最能说明问题:在相同的训练预算下,3B参数的Uni-X在GenEval图像生成基准上拿到了82分,超过了不少7B参数的模型;在零样本图像编辑任务中,只用9万张数据微调,性能就追平了用了更多数据的Bagel模型。
很多人会觉得,Uni-X的设计不算“颠覆性创新”——不就是加了两个分支吗?但恰恰是这种“不炫技”的思路,戳中了多模态AI最核心的问题:我们之前一直在强迫AI用同一套逻辑处理完全不同的东西,却忘了尊重不同模态的本质差异。
之前的解决方案,要么是给模型加更多的专家分支,结果模型变得越来越复杂,训练成本指数级上升;要么是用更复杂的量化方法,试图把图像“掰成”文字的样子,结果丢失了大量视觉信息。而Uni-X的聪明之处,在于它没有试图“改造”模态,而是“顺应”模态:
当然,Uni-X也不是完美的。它目前还依赖VQGAN把图像转换成Token,相当于中间多了一个“翻译官”,会损失一部分图像细节。团队的下一步计划,就是去掉这个翻译官,让模型直接处理原始像素——真正实现从像素到文字、从文字到像素的端到端统一。
当我们谈论AI的“智能”时,总习惯追求更复杂的模型、更多的参数、更大的数据集,却常常忽略最基础的逻辑:不同的信息,本来就该用不同的方式处理。
Uni-X的成功,本质上是一次“减法胜利”——它没有给AI的大脑加更多东西,只是把原本打架的通路分开,让每个部分都能专注做自己擅长的事。这就像一个混乱的公司,不是靠招更多人解决问题,而是靠理清部门职责,让专业的人做专业的事。
尊重差异,比强行统一更接近智能。未来的多模态AI,或许不会是一个无所不能的“超级大脑”,而是一个能让不同模态各展所长、和谐共生的“协作网络”——毕竟,人类的智能,本来就是眼睛、耳朵、嘴巴各司其职又互相配合的结果。
点击充电,成为大圆镜下一个视频选题!