对抗知识焦虑,从看懂这条开始
App 下载
全能图像修复夺冠的不是大模型,是它
真实世界应用|训练技巧|Stable Diffusion 3|中小模型|LoViF图像修复挑战赛|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载真实世界应用|训练技巧|Stable Diffusion 3|中小模型|LoViF图像修复挑战赛|多模态视觉|人工智能
你手机里那张拍糊的雨夜街景、雪天里过曝的全家福、雾霾天模糊的远山合影,终于不用在五个修图APP里反复横跳了——2026年LoViF全能图像修复挑战赛上,一支靠中小模型+训练技巧的团队,击败了用Stable Diffusion 3大模型的对手,拿下了冠军。这场汇聚124支队伍的顶级竞赛,暴露了一个残酷的真相:能在实验室拿高分的模型,到真实世界可能寸步难行;而真正能落地的技术,藏在那些不为人知的细节里。
你可以把传统图像修复想象成医院里的专科门诊:去雾的模型不会修低光,去雨的模型搞不定模糊。而全能图像修复的目标,是训练一个“全科医生”——一张模型通吃模糊、低光、雾霾、雨雪五种最常见的真实图像退化。
但这个目标卡在了一个核心难题上:域鸿沟。过去的模型大多用算法合成的“假退化图”训练,就像医生只在模拟病人身上练习,真遇到真实世界里“多种病一起得”的患者,立刻手足无措。比如合成的雨丝是均匀分布的,但真实的雨会受风力、光照影响,有的地方密有的地方疏,还会和低光、模糊混在一起。
LoViF挑战赛的破局点,是用了一个叫FoundIR-LoViF的真实数据集——24500对在真实场景下拍摄的“退化-清晰”图像对,没有一张是算法合成的。这相当于给所有参赛模型提供了一批“真实病人”,终于能测出谁是真本事,谁是纸上谈兵。
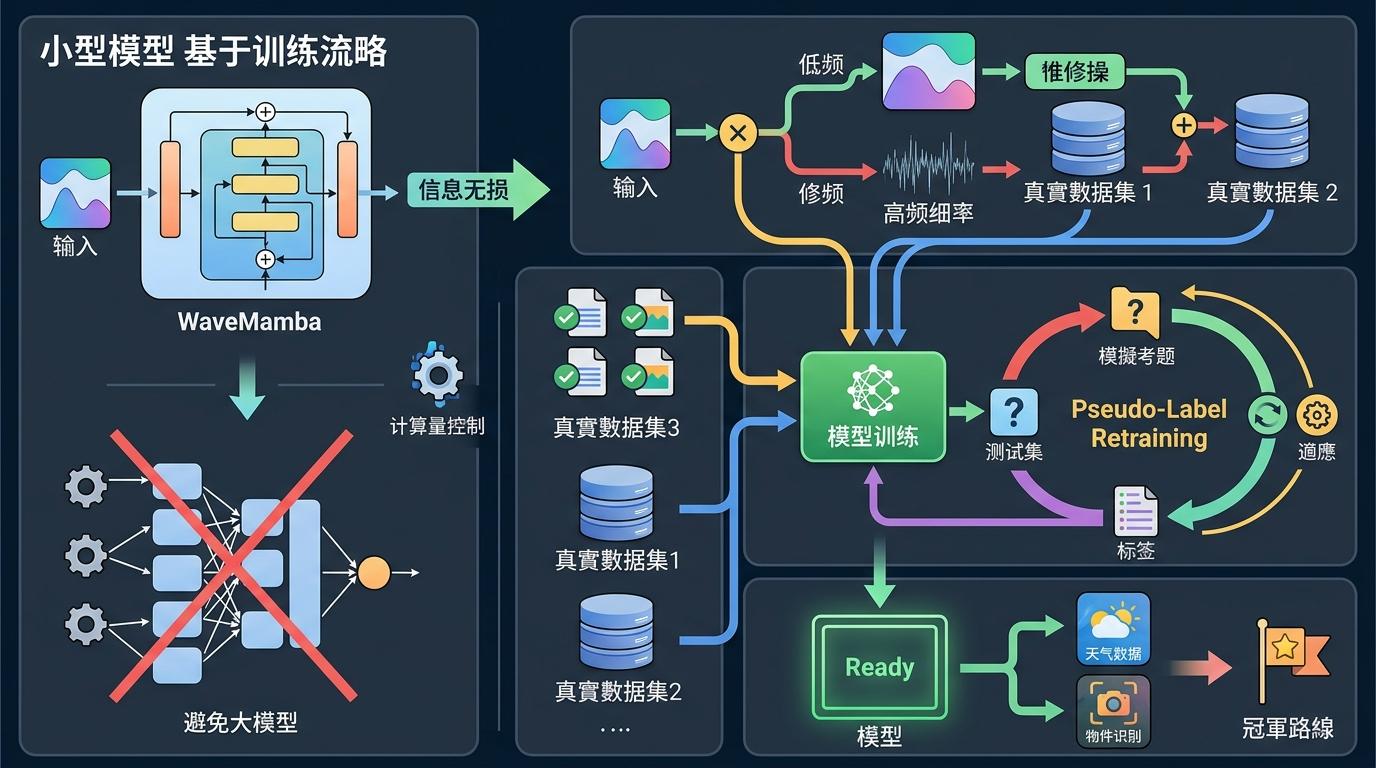
最终进入决赛的9支队伍,走出了三条完全不同的技术路线,得分咬得极紧:冠军HJHK-ClearVision得分33.86,亚军RedMediaTech33.58,季军%sIR32.63,冠亚军差距只有0.28分。
冠军路线:中小模型+极致训练技巧。他们没有用大模型,而是基于WaveMamba架构——一种结合小波变换和状态空间模型的轻量网络,像给图像做“CT扫描”,把低频的全局内容和高频的细节分开修复,既避免了信息丢失,又控制了计算量。真正的杀招是训练策略:除了官方数据集,他们额外加了FoundIR和WeatherBench两个百万级真实数据集,还用上了“伪标签重训练”——先用初步模型修复测试集,把修复结果当“模拟考题”再练一遍,让模型提前适应真实场景的“出题风格”。
亚军路线:大模型先验+细节精修。他们直接请了Stable Diffusion 3这个“外援”,用三阶段训练把大模型的生成能力迁移到修复上:先在百万级数据集上学修复的基本逻辑,再在比赛数据集上微调,最后接一个轻量U-Net专门补细节。推理时还用上了Canny边缘检测,边缘区域用精修结果保锐利,非边缘区域混合初始结果求自然,相当于让大模型画初稿,小模型做润色。
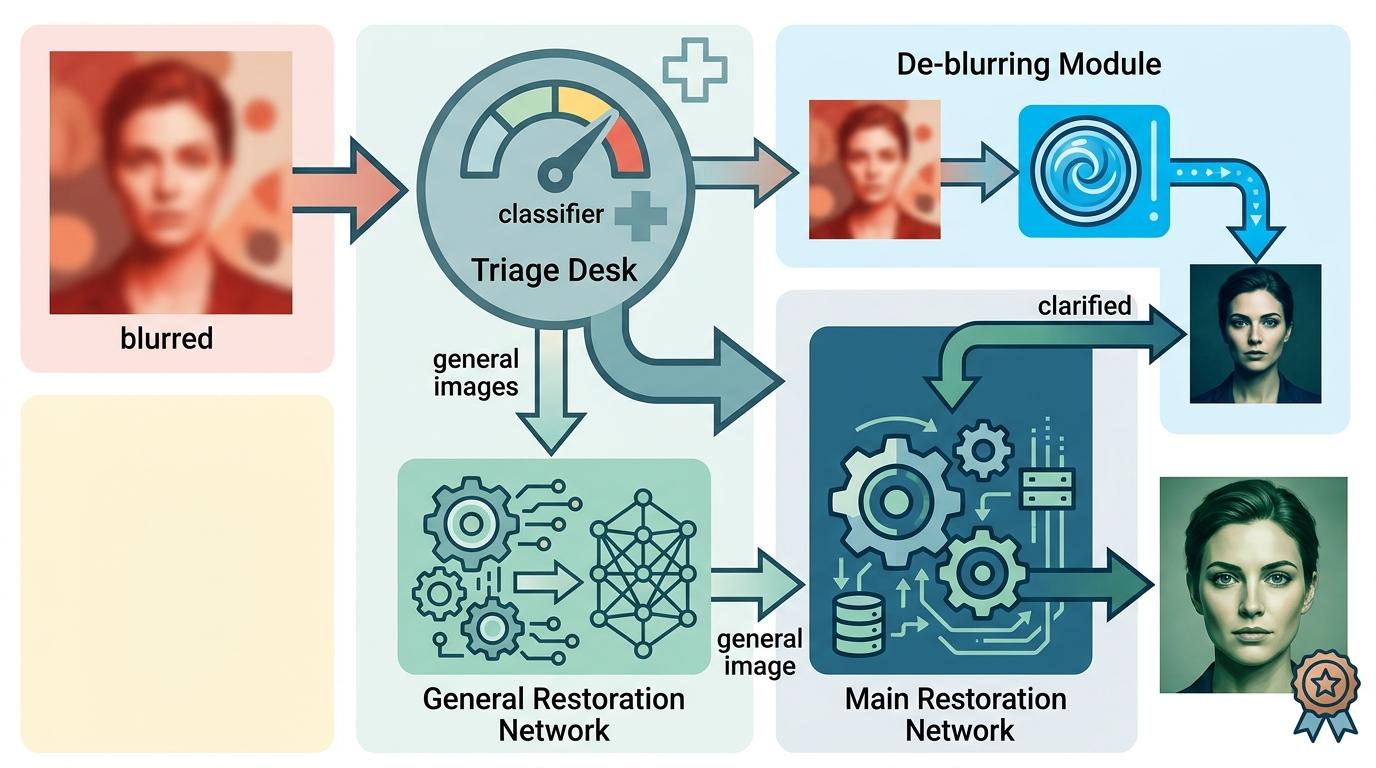
季军路线:精准分诊+条件化处理。他们发现“模糊”是全能模型的软肋,于是加了一个“分诊台”:先用轻量分类器判断图像是不是以模糊为主,如果是,就先送进专门的去模糊模块NAFNet预处理,再进主修复网络。这种“针对性治疗”虽然牺牲了一点通用性,但把模糊图像的修复效果拉到了顶级水平。
比赛结果里藏着一个更现实的矛盾:性能和效率的天平严重倾斜。排名第四的GKD_IR模型计算量高达1004.48 GFLOPs,而排名第六的GU-dayMate只有68.07 GFLOPs,相差近15倍;参数量从160万到1亿多不等。这意味着,有些高分模型是靠“堆算力”堆出来的——在服务器上跑得分很高,但要放到手机、监控摄像头这类资源有限的设备上,根本跑不动。
更关键的是,就算解决了算力问题,模型的泛化能力还是个大问题。这次比赛只覆盖了五种退化,但真实世界里的图像可能同时遇到“雨夜+运动模糊+低光”,甚至出现训练集里完全没有的退化类型,比如镜头眩光、摩尔纹、玻璃反射。就像一个医生只会治五种病,遇到罕见病还是束手无策。
就连评价体系都还在“摸着石头过河”。比赛用的综合评分公式:PSNR+10×SSIM-5×LPIPS,试图兼顾像素准确和人眼感知,但LPIPS是用预训练神经网络测的,还是没法完全等同于人类的主观感受——比如有的模型修复的图像像素误差很小,但看起来就是“假”,而有的模型像素误差大一点,但更符合人眼的审美。
这场竞赛最有价值的,不是决出了谁是第一,而是证明了全能图像修复没有“标准答案”。大模型有大模型的优势,中小模型有中小模型的灵活,条件化设计有条件化设计的精准。
但所有技术路线都指向同一个核心:让AI真正理解图像,而不是只会像素级的“填空”。未来的全能修复模型,不该是一个只会处理预设退化的工具,而该是一个能像人眼一样“看懂”图像语义的智能体——知道哪里是雨,哪里是雾,哪里是真实的阴影,哪里是噪声。
修复的不是图像,是AI对世界的理解。这才是全能图像修复最终要抵达的地方,而我们现在,才刚走完第一步。