对抗知识焦虑,从看懂这条开始
App 下载
长读测序补上自闭症遗传率的缺失拼图
遗传因素|加州大学圣地亚哥分校|基因组暗区|长读测序|自闭症谱系障碍|基因组学|生命科学
对抗知识焦虑,从看懂这条开始
App 下载遗传因素|加州大学圣地亚哥分校|基因组暗区|长读测序|自闭症谱系障碍|基因组学|生命科学
当一位母亲带着3岁仍不会说话的孩子走进诊室,医生写下“自闭症谱系障碍”诊断时,背后是一个困扰科学界20年的谜题:明明双胞胎研究显示自闭症遗传率高达70%-90%,可现有的基因检测只能解释不到一半的病例。那些“失踪”的遗传因素藏在哪?加州大学圣地亚哥分校的研究团队用63个家庭、267份样本给出了答案——答案在被传统测序技术彻底忽略的基因组暗区里。
你可以把传统短读测序想象成用剪刀把一本30亿字的书剪成150字的碎纸片,再试图拼回原样——遇到重复段落、跨页批注或者被撕掉又粘回的页面,这种方法根本无能为力。人类基因组里藏着大量这样的“复杂段落”:长达数千碱基的串联重复、像俄罗斯套娃一样嵌套的复制-缺失片段、只在某条染色体上出现的新生变异。
短读测序的读长只有150-300碱基,面对这些区域只能给出碎片化的模糊信号,甚至直接跳过。在自闭症研究中,这意味着约一半的遗传贡献成了“遗失的拼图”——不是不存在,而是我们的工具看不见。
一组数据能直观体现这种局限:传统技术只能检测到约70%的基因破坏性结构变异,串联重复序列的检测率更是不足62%。那些藏在基因组褶皱里的变异,就这样成了漏网之鱼。
长读长全基因组测序把碎纸片直接换成了整页书页。
它能一次性读取10kb到百万级碱基的DNA片段——相当于从读一个词,变成读一整段话。研究团队用这种技术重新分析63个自闭症家庭的样本时,结果超出预期:结构变异检测率直接提升33%,串联重复序列检测率提升38%。更关键的是,他们发现了短读测序从未捕捉到的全新变异:比如只在孩子体内出现的外显子新生结构变异,还有像“嵌套式复制-缺失”这样此前未被记录的复杂模式——就像一本书里某段文字被复制后,又在原位置删去了一部分,短读测序只能看到零散的字,长读测序却能看清整个修改逻辑。
我认为最值得关注的,是这项技术把遗传检测从“找单个突变”推进到“看全局影响”。研究人员同时读取了DNA序列和甲基化标记——这相当于不仅看文字,还能看到哪些句子被标了重点、哪些被划了删除线。他们发现FMR1基因中35-54次的CGG重复,会导致基因启动子区域被过度“标记沉默”,而这个基因正是脆性X综合征的致病根源,也是自闭症最常见的单基因病因之一。
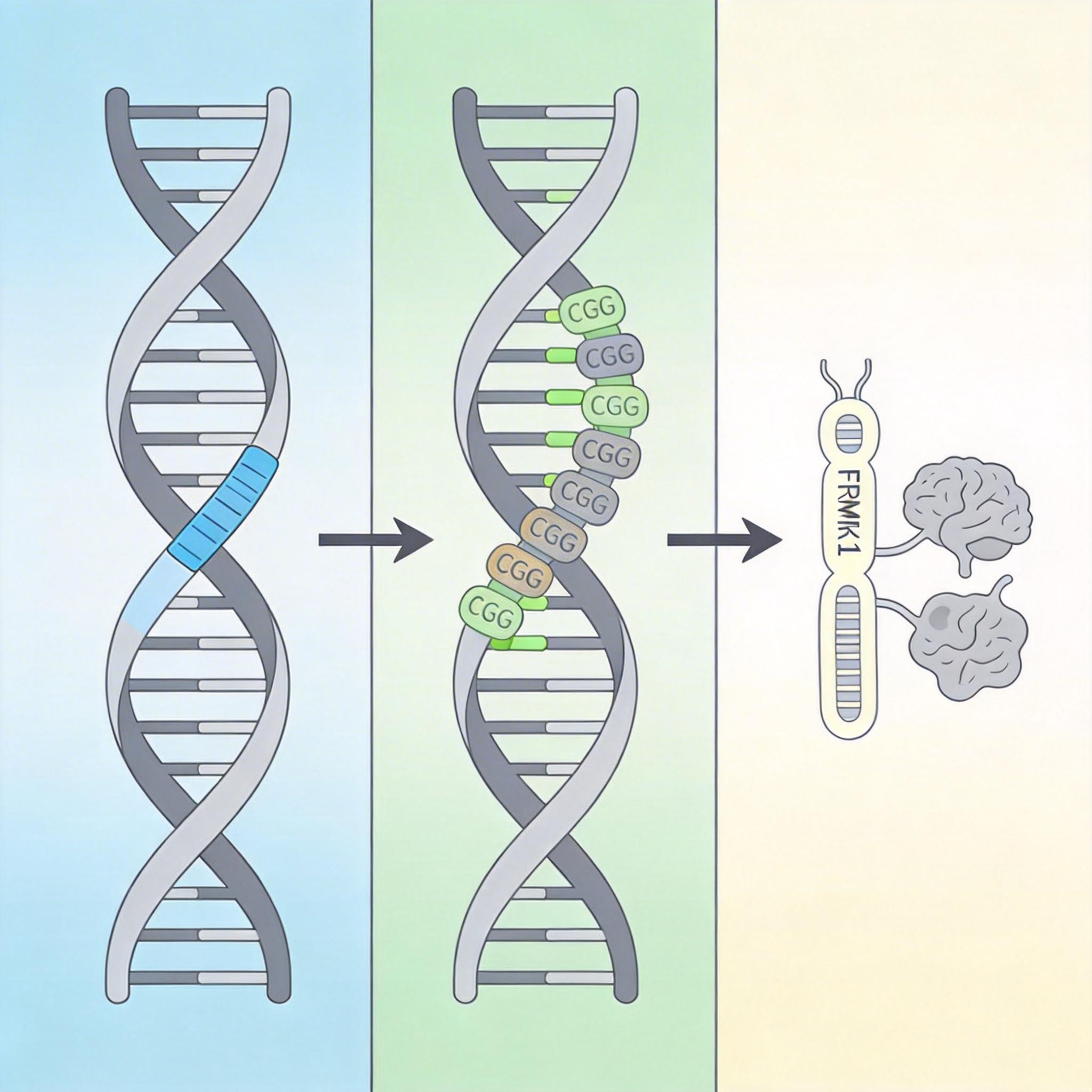
回到中国的现实语境:我们有超过200万0-14岁自闭症儿童,平均诊断延迟近11个月,专业诊断人员缺口超10万。长读测序带来的不仅是科研突破,更是临床端的精准诊断可能。
但技术落地的障碍也很明确:目前长读测序的成本是短读测序的3-5倍,一台Oxford Nanopore测序仪的价格仍让多数基层医疗机构望而却步;更重要的是,我们缺乏自己的多民族自闭症基因数据库——现有研究多基于欧洲人群,而不同种族的基因变异频率存在差异,直接套用国外数据可能导致误诊。
不过趋势已经在形成:国内已有机构开始引入长读测序技术,针对自闭症家庭开展小规模研究。一旦成本随着技术迭代下降,结合我们庞大的患者基数,中国完全有可能在自闭症精准诊断领域实现弯道超车。
当研究团队把长读测序的结果递给那些等待答案的家庭时,他们递出的不只是一份检测报告,更是一个被推迟了太久的希望。这项研究目前只解释了7.4%的“遗失遗传率”,但研究者推测,随着样本量扩大,这个数字可能翻倍。
**看见,是改变的第一步。**从只能读取碎片化的碱基,到能看清基因组的完整段落,长读测序正在把自闭症的遗传谜题从“找不到答案”变成“答案就在眼前”。未来某一天,当一位母亲带着孩子走进诊室,医生或许能直接指向某个基因变异,给出明确的干预方案——而这一切,始于我们终于拥有了能看清整个基因组的眼睛。