对抗知识焦虑,从看懂这条开始
App 下载
从照片到悬浮影像,三维视觉的进化密码
相位信息|光场重建|光学元件|树莓派|全息发光显示|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载相位信息|光场重建|光学元件|树莓派|全息发光显示|多模态视觉|人工智能
整理旧照片时,我在工位上摆了个奇怪的相框——没有玻璃,中间空空如也,却能让老照片里的人“浮”在半空中。凑过去看,相框里藏着树莓派和一堆光学元件,既不是早年靠玻璃反射的“伪全息”,也不是需要激光才能启动的实验室装置。它靠的是一种叫全息发光显示的技术,能把普通2D照片直接转换成有真实深度的3D影像。这背后,是人类用了80年,才把“让记忆立体起来”的幻想,从实验室搬到了书桌。
你可以把普通照片想象成一张“平面收据”——它只记录了光线的明暗(也就是振幅),却弄丢了光线的“走位”(也就是相位)。就像你只知道朋友的身高,却不知道他站在房间的哪个角落,自然没法还原整个场景。
全息技术的核心,就是把这丢失的“走位”找回来。1947年丹尼斯·加博尔提出这个概念时,还没有合适的光源,直到1960年激光出现,才真正让全息从理论落地。激光是一种“步调完全一致”的光,把它分成两束:一束照在物体上,带着物体的所有光影信息(物光);另一束直接照在记录介质上(参考光)。两束光相遇时会像水波一样干涉,在介质上留下密密麻麻的条纹——这些条纹就是包含了振幅和相位的“完整光场密码”。
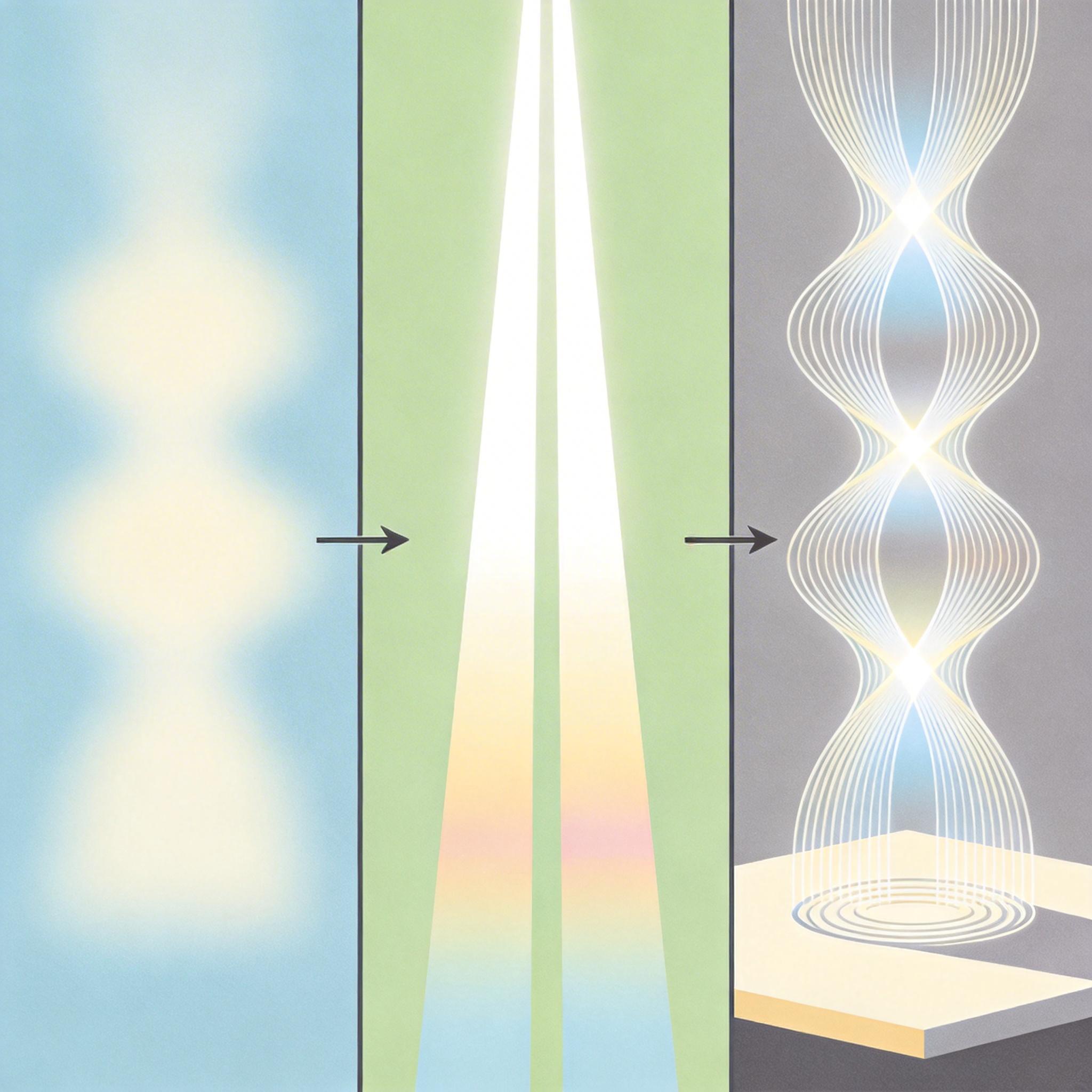
当用同样的激光再照射这些条纹时,就会还原出当初物体反射的所有光线,哪怕物体已经不在,你也能从各个角度看到它的立体影像,就像它真的在那里一样。但早期全息必须依赖激光,设备庞大还只能在黑暗环境下观看,离日常使用差得远。
真正让三维影像走进日常的,是把全息原理和普通显示技术结合的新方案——比如那个悬浮相框用到的全息发光显示(HLD)。它没有用复杂的激光系统,而是在普通高清液晶屏后加了一层“全息背景层”,这层固定的光学结构会在屏幕内部构建出一个有真实深度的“光场容积”。

当你导入一张2D照片时,配套的AI算法会先把画面拆分成前景和背景,估算出每个部分的深度,再把2D画面“嵌入”到这个光场容积里。你从不同角度看,会像看真实物体一样看到不同的侧面,影像看起来就像悬浮在相框的中空部分,不需要戴眼镜,也不用站在特定角度。
这和早年的裸眼3D技术完全不同:以前的视差屏障或柱状透镜,本质是让左右眼看到不同的画面,靠大脑合成立体感,一旦偏离“甜区”就会重影;而HLD是直接重建了光场,就像把真实场景的光影复制了一份。当然它也有局限——目前的视觉深度只有5厘米左右,还没法还原大场景的立体效果,而且AI对复杂场景的深度估算偶尔会出错,比如把头发丝和背景混在一起。

现在的三维显示技术,已经解决了“能不能做”的问题,但“能不能普及”还有三道坎。
第一道是硬件成本。高精度的光学元件比如空间光调制器,目前主流产品的分辨率只有4K,要实现大尺寸、全视角的全息显示,需要像素间距缩小到1微米以内,成本会飙升到几十万元,根本没法走进普通家庭。就算是HLD这种简化方案,目前的消费级产品价格也在千元以上,比普通相框贵了好几倍。
第二道是内容瓶颈。高质量的3D内容需要专业建模,成本是2D内容的数倍,就算有AI辅助2D转3D,生成的效果也远不如原生3D内容细腻。现在网上的3D资源少得可怜,就像买了一台蓝光播放器,却找不到碟片。
第三道是认知和体验的平衡。长时间看裸眼3D,有些人会出现视觉疲劳,这是因为大脑需要不断调整视觉焦点,来适应屏幕上的“虚拟深度”。目前的技术还没法完全模拟人眼看真实物体时的焦点变化,这也是未来需要突破的核心问题之一。
那个悬浮在相框里的老照片,其实是人类对“真实感”的执念——我们不满足于用平面记录记忆,总想把那些光影、温度和空间感一起留住。从加博尔在实验室里的第一幅全息图,到现在书桌上的悬浮相框,每一步都在把“立体”从科幻拉到现实。
未来的三维显示,可能不是科幻电影里那种能触摸的全息投影,而是像现在的智能手机一样,悄悄融入生活的每个角落:汽车挡风玻璃上的导航会“浮”在路面上,医生看着全息影像就能完成手术,甚至课本里的恐龙会从页面里“走”出来。
我们记录世界的方式,正在重新定义我们感知世界的方式。