对抗知识焦虑,从看懂这条开始
App 下载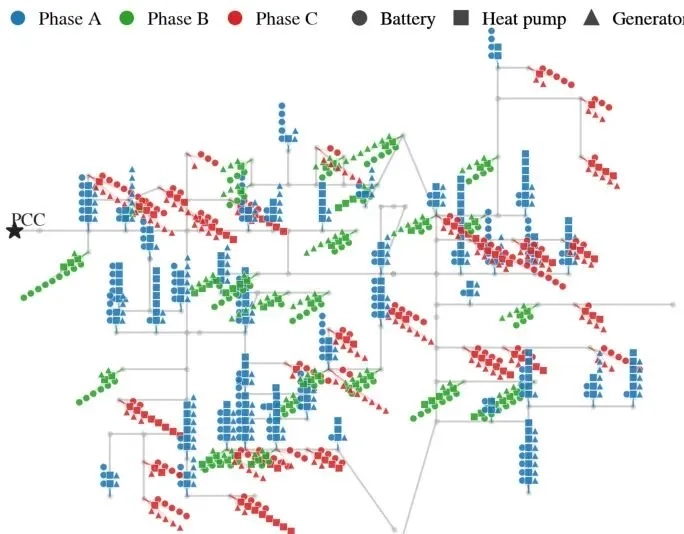
千台电网设备15分钟协同,牛津方法破局集中式瓶颈
分布式调度|隐式微分|电网设备协同|GradMAP方法|牛津大学|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载分布式调度|隐式微分|电网设备协同|GradMAP方法|牛津大学|AI产业应用|人工智能
想象一下:你家的光伏板、邻居的电动车、街角的储能站,成千上万台设备同时接入电网——既要让每台设备都发挥最大价值,又不能让电网过载、电压失衡,甚至引发故障。这曾是电网运营商的噩梦:集中式调度中心算不过来,传统分布式方法要么慢得离谱,要么根本扛不住规模。但牛津大学的团队用一套叫GradMAP的方法,在单张GPU上15分钟就训练出了1000台设备的协同策略。这不是实验室里的小把戏,它直接戳破了大规模电网协调的核心死穴:为什么我们之前总在「算得准」和「跑得快」里二选一?
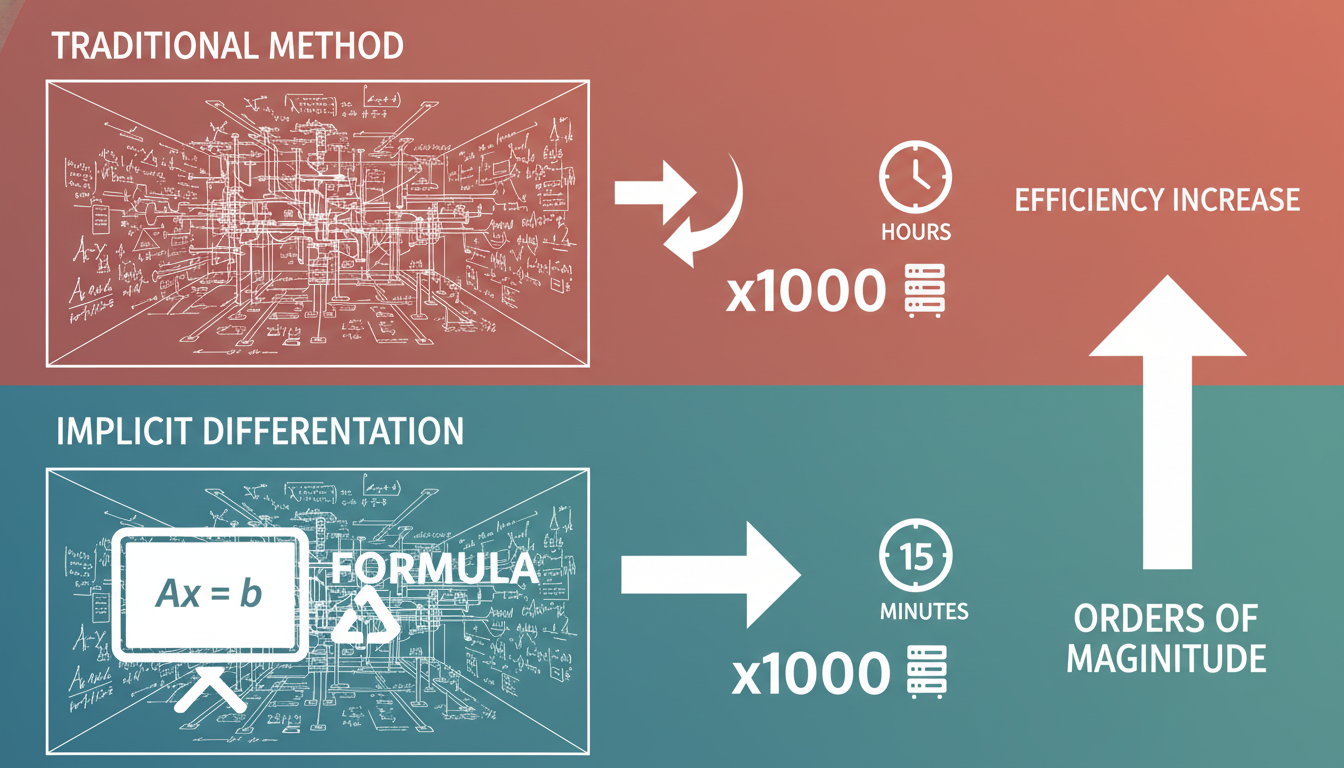
你可以把传统的电网优化想象成解一道超复杂的数学题——每台设备都是一个变量,电网的物理规则是约束条件。以前的解法要么是硬算,把所有步骤拆开来一步步推导,结果算到天荒地老;要么是用黑箱AI瞎蒙,完全不管电网的物理规律,最后经常闯祸。
GradMAP的第一个绝招是「隐式微分」。它没有把电网的物理模型当成外部规则,而是直接嵌进了算法的学习过程里。就像你解几何题时,不用把所有辅助线都画出来,而是直接利用三角形的内角和定理推导——它跳过了反复求解电网潮流的繁琐过程,直接算出「某台设备多发一度电,会让某条线路的电压变化多少」。
这带来的效率提升是数量级的:传统方法要把电网潮流的求解过程全展开,相当于把一道题的草稿纸写满一整个房间;而隐式微分只需要求解一个线性方程,就像直接用公式得出答案。在1000台设备的测试里,这直接把训练时间从几小时压缩到了15分钟。
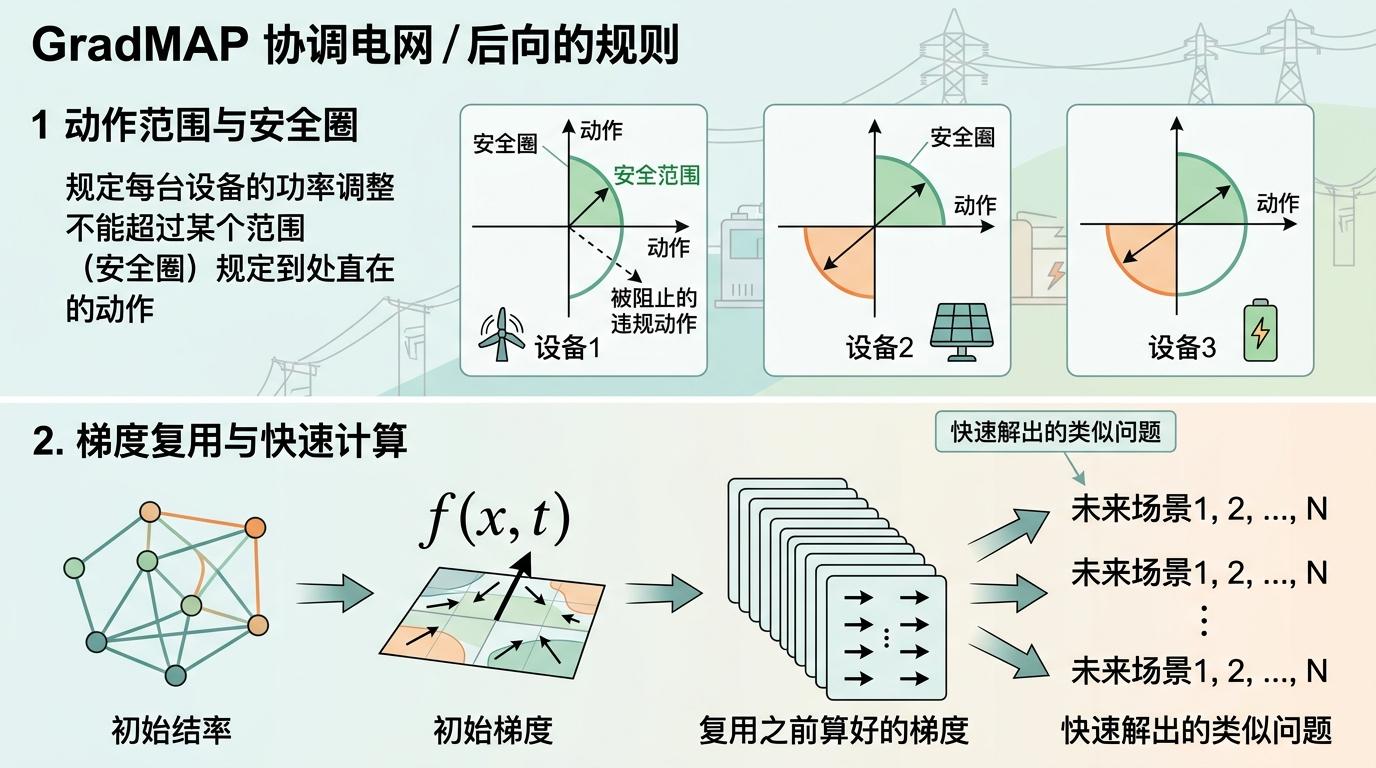
GradMAP的第二个创新,是把「信赖域」直接建在了设备的动作上,而不是传统强化学习常用的概率分布里。
你可以把信赖域理解成一个安全圈:每次调整策略时,不能跳出这个圈,否则容易失控。传统方法的安全圈画在「设备做某个动作的概率」上,相当于管的是「设备有多大可能会多发电」,但最后真正影响电网的是「设备实际发了多少电」——这就像你给司机定规矩,不说「不能开超过100码」,而是说「你踩油门的力度不能超过50%」,中间隔着一层模糊地带。
GradMAP直接把安全圈画在动作本身:规定每台设备的功率调整不能超过某个范围。这相当于直接给司机定死了最高车速,既精准又简单。它还能复用之前算好的梯度——就像你解出一道题后,用同样的思路快速解出类似的100道题,不用每次都从头开始。
实验数据最有说服力:它把电网的最高电压偏差从0.0362 p.u.降到了0.0095 p.u.,相当于把电网的电压波动从「坐过山车」变成「走平路」;同时训练速度比传统梯度方法快了3到5倍。

当然,GradMAP不是万能的。它的第一个局限是「依赖精确的电网模型」——就像你解几何题得先知道准确的三角形边长,如果电网的实际线路参数和模型有误差,算法的效果就会打折扣。现实中,有些老旧电网的参数本身就不全,新兴的微电网更是缺乏精确数据,这会成为它落地的第一道坎。
第二道坎是「参数的手动调节」。算法里有个叫M的成本缩放因子,论文里用的是200,这个参数直接影响训练速度,但目前只能靠人工试出来。如果换一个电网场景,可能得重新调参数,这显然不适合大规模推广。
第三道坎是「非凸性的天花板」。三相不平衡的配电网本身就是个非凸优化问题,GradMAP能找到很好的局部最优解,但没法保证是全局最优——就像你在山里找到一个风景不错的山谷,但没法确定它是不是整个山区里最低的那个。
当数以亿计的分布式设备接入电网时,我们需要的从来不是「完美的算法」,而是「能在现实里跑起来的解法」。GradMAP最值得关注的,不是它在实验室里刷出了多少漂亮数据,而是它终于把「尊重物理规律」和「高效分布式学习」这两个之前看似矛盾的点捏在了一起。
它给我们的启发远不止电网:机器人集群、自动驾驶编队、甚至是城市的智能交通调度——所有需要大规模分布式协同的场景,都可以用「把物理模型嵌进算法」+「直接约束动作」的思路破局。
懂物理的AI,才是能落地的AI。