对抗知识焦虑,从看懂这条开始
App 下载
AI燃料快烧完了,人类要给机器造数据
规模定律|科技公司|AI训练数据|数据危机|高质量文本数据|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载规模定律|科技公司|AI训练数据|数据危机|高质量文本数据|大语言模型|人工智能
2026年春,一份报告给所有AI从业者浇了盆冷水:按当前的训练速度,人类攒了几十年的公开高质量文本数据,会在2026到2032年间被彻底耗尽。你手机里的聊天机器人、写文案的AI工具、甚至帮医生读片的智能系统,它们的“智力”都依赖这些数据喂出来——就像汽车要烧汽油。可现在,油库快空了。更棘手的是,人类每年新产出的数据,根本赶不上AI胃口膨胀的速度。这不是科幻小说里的危言耸听,是摆在所有科技公司面前的现实难题。
要理解这场数据危机,得先搞懂AI的“吃饭逻辑”。过去十年,AI的进步遵循一条简单的“规模定律”:模型参数越多、喂的数据越足、给的算力越强,AI就越聪明。OpenAI的GPT系列就是最好的例子——从GPT-1到GPT-4,参数翻了几十万倍,训练数据从几亿token涨到了几千亿,性能也从只会简单补全句子,变成能写代码、答高考题。
但这条定律有个致命的bug:AI吃的是人类积累了几十年甚至几千年的“库存”数据。维基百科是几千人维护20年的成果,经典图书是人类文明几千年的沉淀,互联网数据是过去几十年网民攒下的内容。这些数据是“不可再生资源”,用完就没了。
更糟的是,人类每年新产生的数据,大多是重复、低质的内容——比如网上的口水帖、重复的新闻稿,真正能用来喂AI的高质量数据,增长速度慢得像蜗牛。AI的胃口却在指数级膨胀,就像一个每天饭量翻倍的巨人,早晚会把家里存的粮吃光。
既然人类的库存不够用,有人想了个办法:让AI自己造数据。这听起来像“让母鸡自己生蛋自己孵”,但已经有不少公司在这么干了。
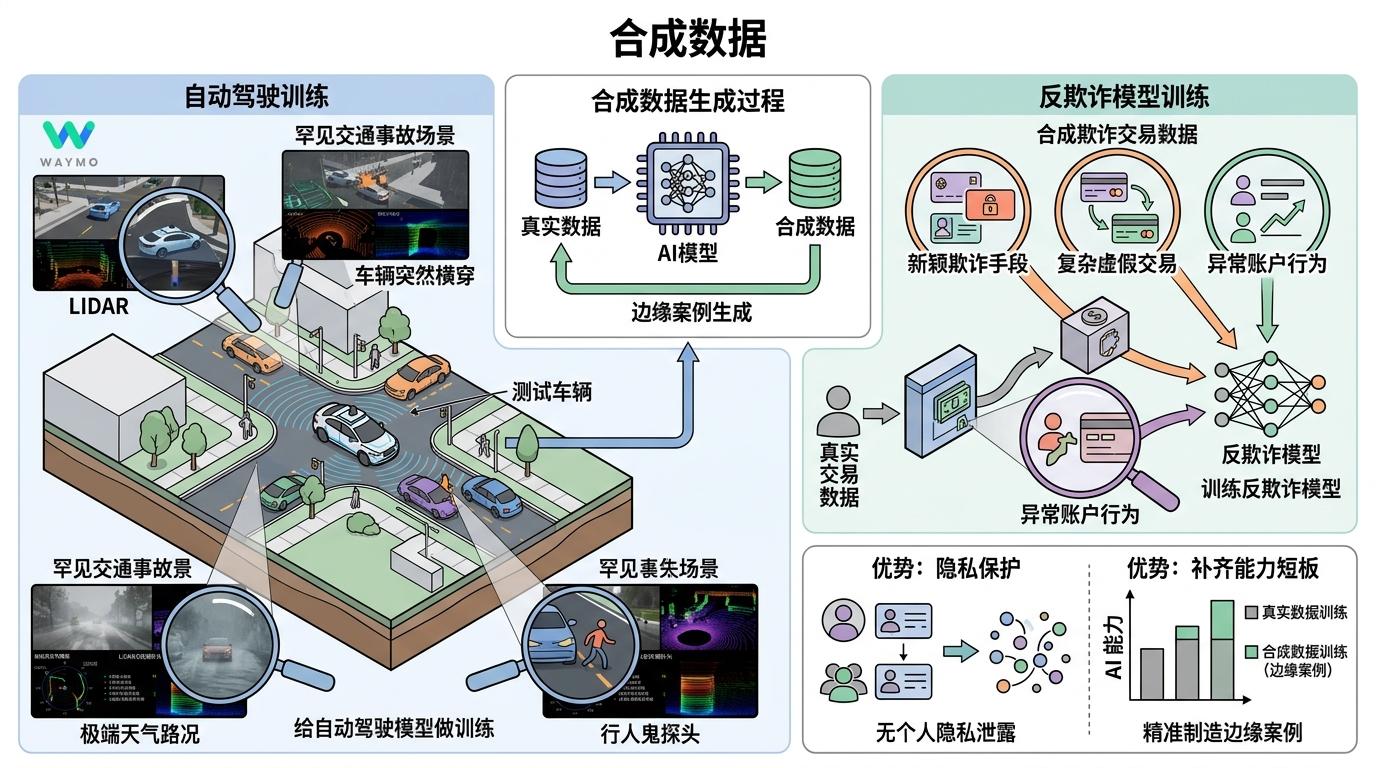
最常见的是“合成数据”——用AI生成和真实数据差不多的内容。比如Waymo用AI模拟各种罕见的交通事故场景,给自动驾驶模型做训练;银行用AI生成假的欺诈交易数据,训练反欺诈模型。这些合成数据不用怕隐私泄露,还能精准制造那些真实世界里很少发生的“边缘案例”,帮AI补上能力短板。
还有一种更聪明的玩法:“知识蒸馏”。让大模型当“老师”,把它学到的知识教给小模型。比如让GPT-4解数学题,把它的解题思路整理出来,再去训练更小的模型。这样既不用再啃那些已经被嚼烂的真实数据,还能把大模型的能力“压缩”到小模型里,降低成本。
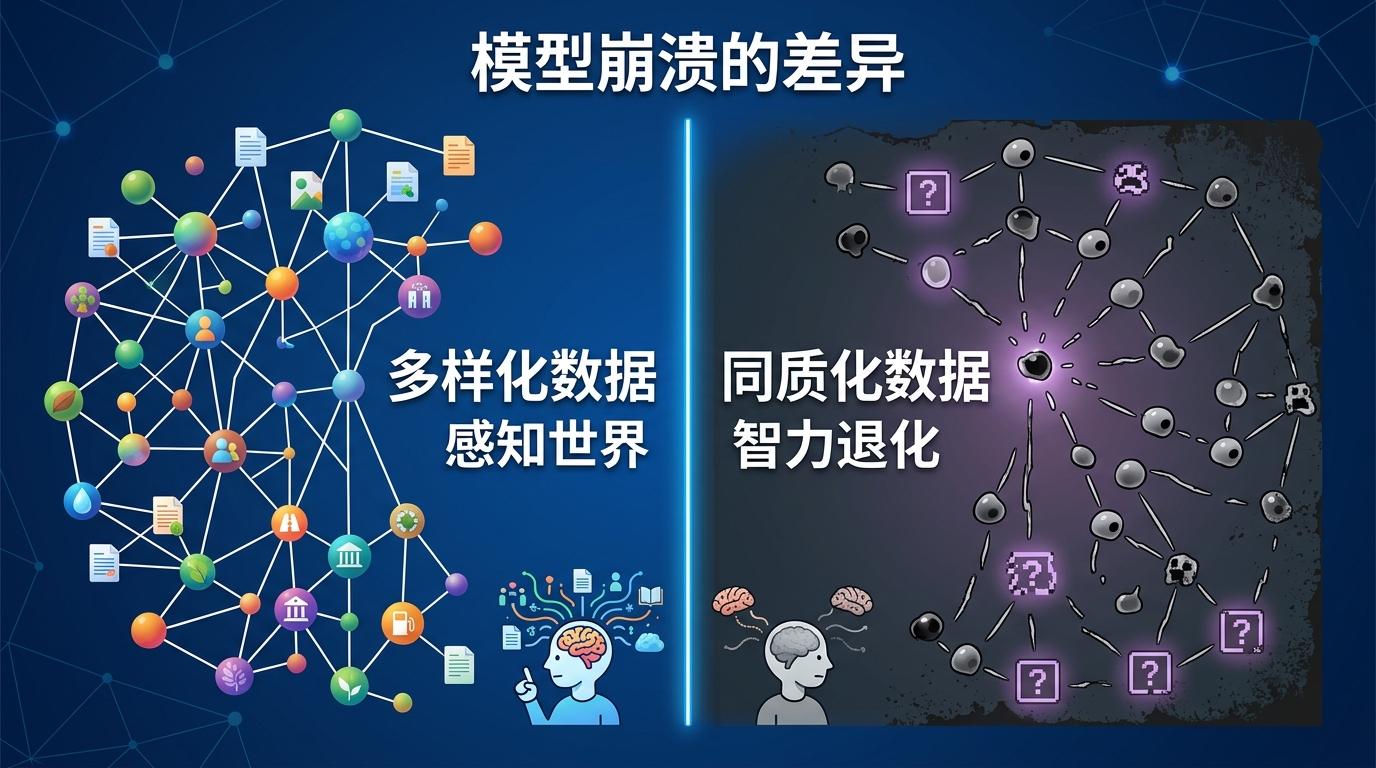
但这种方法也有风险。如果AI一直吃自己造的数据,就像人只吃自己做的饭,早晚会营养不良——模型会变得越来越同质化,失去对真实世界的感知能力,甚至会生成错误的信息。这就叫“模型崩溃”,相当于AI的“智力退化”。
光靠AI自己造数据还不够,人类得从“库存”里抠出更多能用的东西。比如那些被锁在各个企业、医院里的“数据孤岛”——医院的病历、工厂的设备数据、银行的交易记录,这些都是高质量的数据,但因为隐私、合规的问题,一直没法用来训练AI。
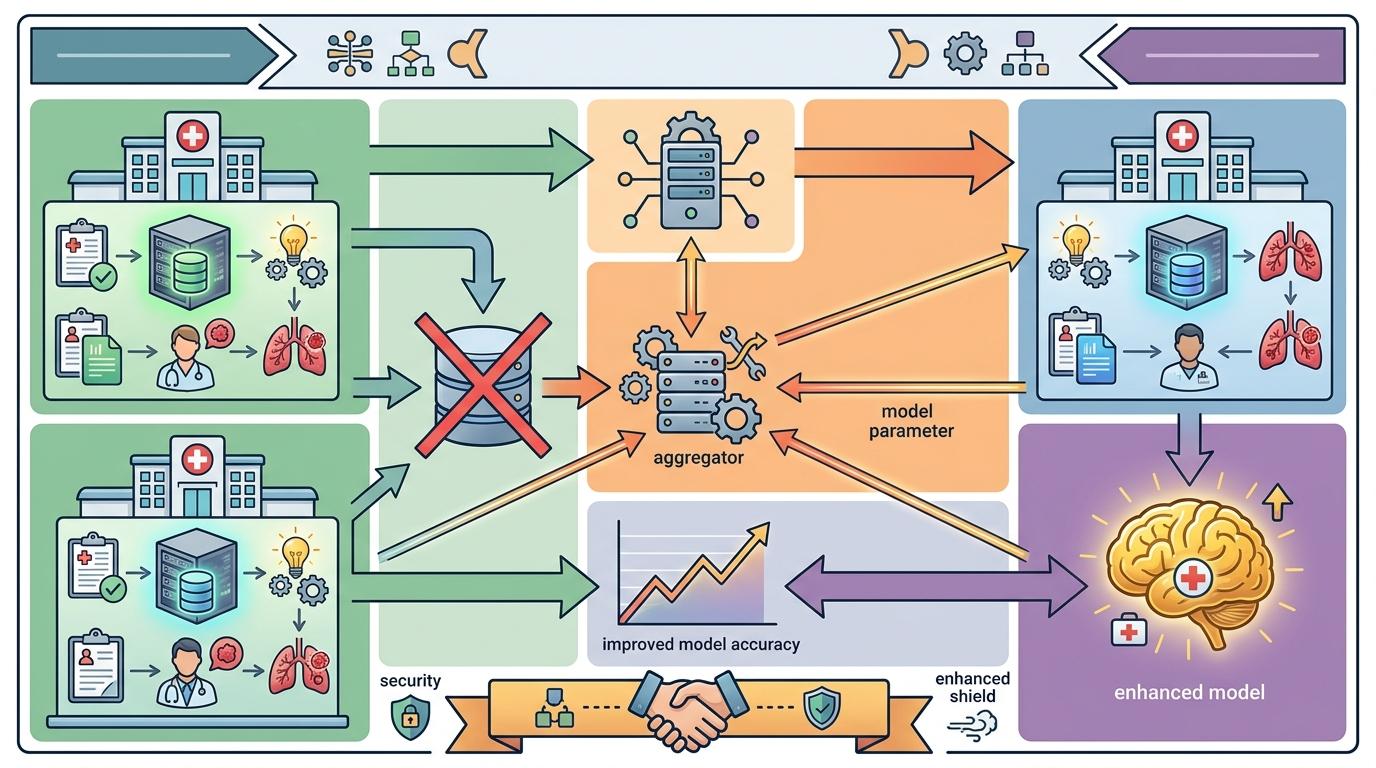
现在有了“联邦学习”技术,不用把数据集中到一起,就能让多个机构一起训练模型。比如几家医院可以联合训练癌症诊断模型,每家医院的 data 都留在自己服务器上,只把模型的更新参数传出去,既保护了患者隐私,又能用上所有医院的数据。
还有一个被忽略的宝藏:人类的“隐性知识”。比如医生看病时的思考过程、老工匠的手艺、企业家做决策的思路,这些都是没法写成文字的“活知识”。现在有人在研究怎么把这些知识“数字化”——比如让医生一边看片一边说出自己的思考,录下来给AI做训练;或者用传感器记录老工匠的动作,让AI学习手艺。这些数据的价值比网上的口水帖高得多,可能是AI突破瓶颈的关键。
这场数据危机,其实是AI发展的一个转折点。过去我们总觉得,AI的进步靠的是更大的模型、更多的算力、更多的数据,但现在才发现,数据不是无限的,我们得学会“精打细算”地用数据。
未来的AI,可能不再是“吃得多就聪明”的巨人,而是“会挑食、会自己做饭、还会向人类请教”的学习者。这不仅是技术的进步,更是我们对AI的理解的转变——AI不是一个只会消耗资源的机器,而是一个能和人类一起创造、一起进化的伙伴。
数据枯竭不是终点,是AI学会独立的起点。