对抗知识焦虑,从看懂这条开始
App 下载
AI看了段摆锤视频,自己悟出了物理课本知识
物理变量提取|信息瓶颈理论|无监督学习|埃默里大学|应用数学|大语言模型|数理基础|人工智能
对抗知识焦虑,从看懂这条开始
App 下载物理变量提取|信息瓶颈理论|无监督学习|埃默里大学|应用数学|大语言模型|数理基础|人工智能
想象你给AI看一段28×28像素的模糊摆锤视频——没有标注摆角,没有标注角速度,连“这是个摆锤”的提示都不给。你觉得它能学到什么?可能是“识别出这是个来回晃的东西”,最多是“预测下一秒它晃到哪”。但埃默里大学的团队让AI做到了更离谱的事:它盯着像素点的变化,无监督地“悟”出了和物理课本完全一致的二维相空间——角度和角速度这两个核心变量,连拓扑结构都分毫不差。这不是图像识别,是AI第一次像物理学家那样,从混乱的观测里提炼出了世界的底层规律。
要理解AI怎么做到的,得先搞懂它背后的“信息瓶颈”理论——这是以色列科学家Naftali Tishby在1999年提出的框架,简单说就是“学习的本质是遗忘”。 你可以把AI的学习过程想象成筛沙子:输入的像素数据是一堆混着碎石、尘土和金粒的沙子,AI要做的就是用筛子把金粒(对预测未来有用的核心信息)留下来,把碎石和尘土(光照、像素噪点这些无关细节)筛出去。这个筛子就是“信息瓶颈”——它压缩输入数据,只保留对预测未来最关键的信息。
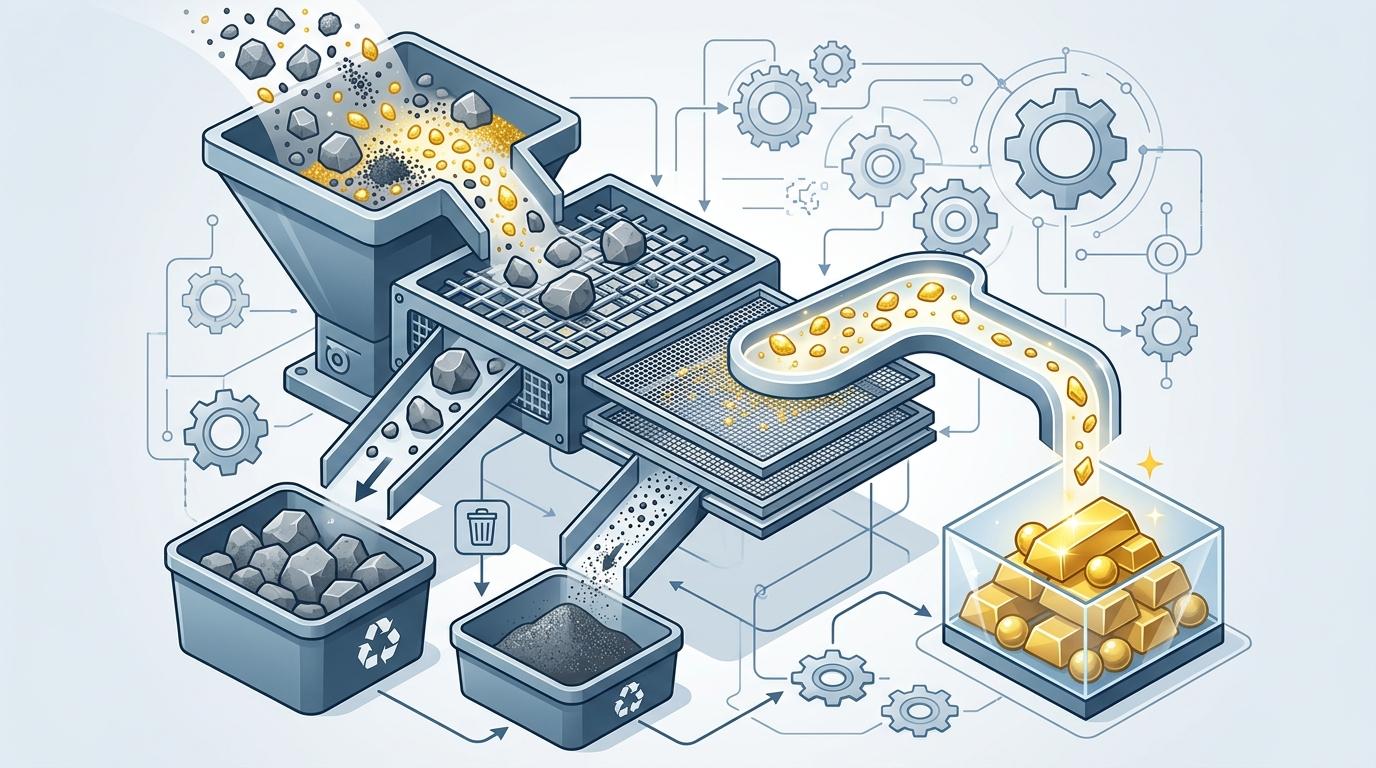
传统的AI模型比如VAE,会试图把像素原样“还原”出来,相当于把所有沙子都留下,自然分不清金粒和尘土。而这次的DySIB模型,完全跳过了“还原像素”的步骤,它的目标只有一个:用过去的像素预测未来的像素,在这个过程中自动把最核心的变量挤出来。 直给补刀:DySIB的核心是对称信息瓶颈——它同时压缩过去和未来的观测数据,然后最大化两者压缩表示之间的互信息。说人话就是,AI会反复问自己:“从刚才的画面里,我最少需要记住哪几个数,就能准确猜到下一秒的画面?”
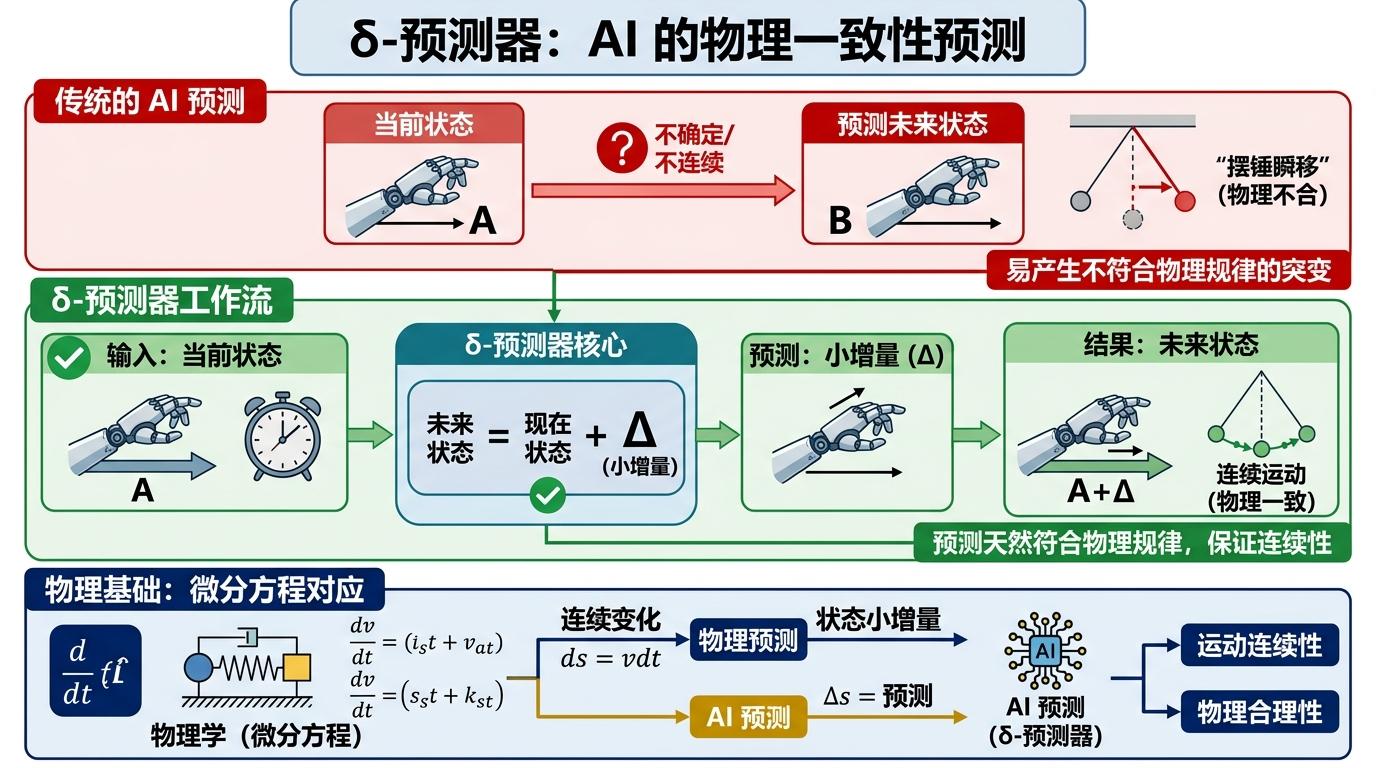
光靠信息瓶颈还不够,AI得有点“物理直觉”才能不跑偏。DySIB给AI加了两个物理归纳偏置,相当于给它装了个简化版的“物理脑”。 第一个是共享编码器——不管是过去的画面还是未来的画面,AI都用同一个编码器处理。这符合物理世界的时间平移不变性:摆锤的运动规律不会因为你今天看还是明天看就变了。这个设计强制AI忽略时间起点的干扰,只盯着运动本身的规律。 第二个是δ-预测器——AI不会直接预测未来的完整状态,而是预测“未来状态=现在状态+一个小增量”。这刚好对应物理里的微分方程:物体的运动是连续的,下一秒的状态只和当前状态以及微小的变化量有关。这个设计让AI的预测天然符合物理规律,不会出现“摆锤突然瞬移”这种离谱的结果。
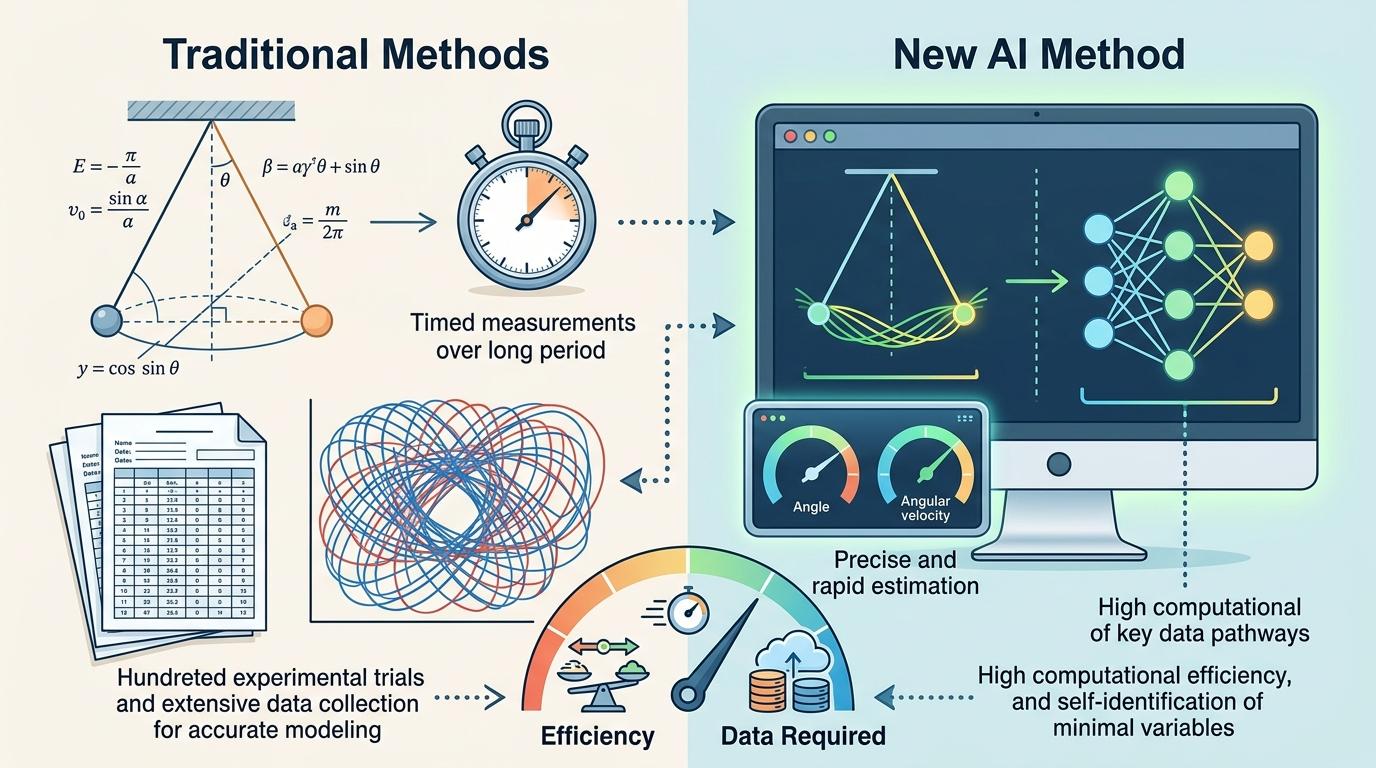
实验数据最能说明问题:AI只需要16-32条摆锤轨迹就能准确还原角度,256条轨迹就能还原角速度——这效率比传统方法高了一个数量级。更惊人的是,AI自己算出了这个系统只需要二维变量,和物理课本里的结论完全一致。
当然,现在就吹AI能取代物理学家还太早。DySIB的成功只限于像摆锤这样的简单系统,它还有三个绕不开的局限。 首先是对复杂系统的泛化能力未知。摆锤的相空间是二维的,拓扑结构简单,但如果是混沌系统比如双摆,或者多体系统比如流体,AI能不能提炼出核心变量还是个问号。 其次是对噪声的耐受度不够。实验用的是干净的实验室数据,如果是真实世界里带噪声的观测,比如监控摄像头拍的风吹树叶,AI可能就抓不住核心规律了。 最后是超参数的手动调节。现在AI还需要人类帮它设置潜在维度、时间窗口这些参数,真正的自动化科学发现,得让AI自己决定该用什么参数。 但这些局限都掩盖不了一个事实:AI已经从“识别世界”的阶段,走到了“理解世界”的门口。它不再是只会拟合数据的黑箱,而是开始像人类一样,从混乱中提炼秩序。
当AI盯着模糊的摆锤视频,自己画出和物理课本一样的相空间时,我们看到的不只是一个算法的成功,更是科学发现范式的微小偏移。过去,人类科学家靠观测、假设、实验来提炼规律;未来,AI可能会成为科学家的“新眼睛”——它能盯着人类看不懂的高维数据,快速筛出那些最核心的变量,给人类指出新的研究方向。 学习的本质是遗忘,发现的本质是筛选。AI正在用它的方式,重新定义我们理解世界的路径。