对抗知识焦虑,从看懂这条开始
App 下载
Token不是字符,是中文AI的语义拼图块
AI中文理解|语义单元|BPE算法|中文分词|Token机制|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI中文理解|语义单元|BPE算法|中文分词|Token机制|大语言模型|人工智能
当你用中文和AI对话时,屏幕上跳出的每一个字,背后可能正经历一场隐秘的拆分与重组——这不是文字游戏,是Token机制在决定AI能读懂多少中文的细腻语义。近期学界和业界掀起的Token中文名讨论,从“模元”“智元”到“机器之薪”,本质上是在为中文AI的核心认知单位寻找精准的文化锚点。为什么一个翻译会引发如此多的推敲?答案藏在中文和拼音文字最根本的差异里。
Token是AI理解语言的最小语义单元,对英文这类有空格分隔的语言来说,它可能是一个单词、一个词根;但对没有天然词界的中文而言,它可能是一个汉字,也可能是被错误合并的无意义字符组合。主流的BPE、WordPiece等分词技术,靠统计语料里的字符出现频率来合并Token,放在中文语境里,很可能把“的事物”拆成“的事”和“物”,或是把“科技”和“学科”的部分字符错误合并,直接导致AI的语义理解出现偏差。
更关键的是,中文汉字自带偏旁部首这类细粒度语义信息——“清”“河”“湖”共享的“氵”,本是AI理解语义关联的天然线索,但传统Token机制往往把单个汉字当作整体,完全忽略了这些结构里藏着的语义密码。有研究尝试给模型加入偏旁嵌入层,仅用增加0.2%参数的代价,就让中文文本分类、自然语言推理的准确率提升了1.3%-1.6%,这恰恰说明现有Token机制对中文的语义挖掘还远远不够。
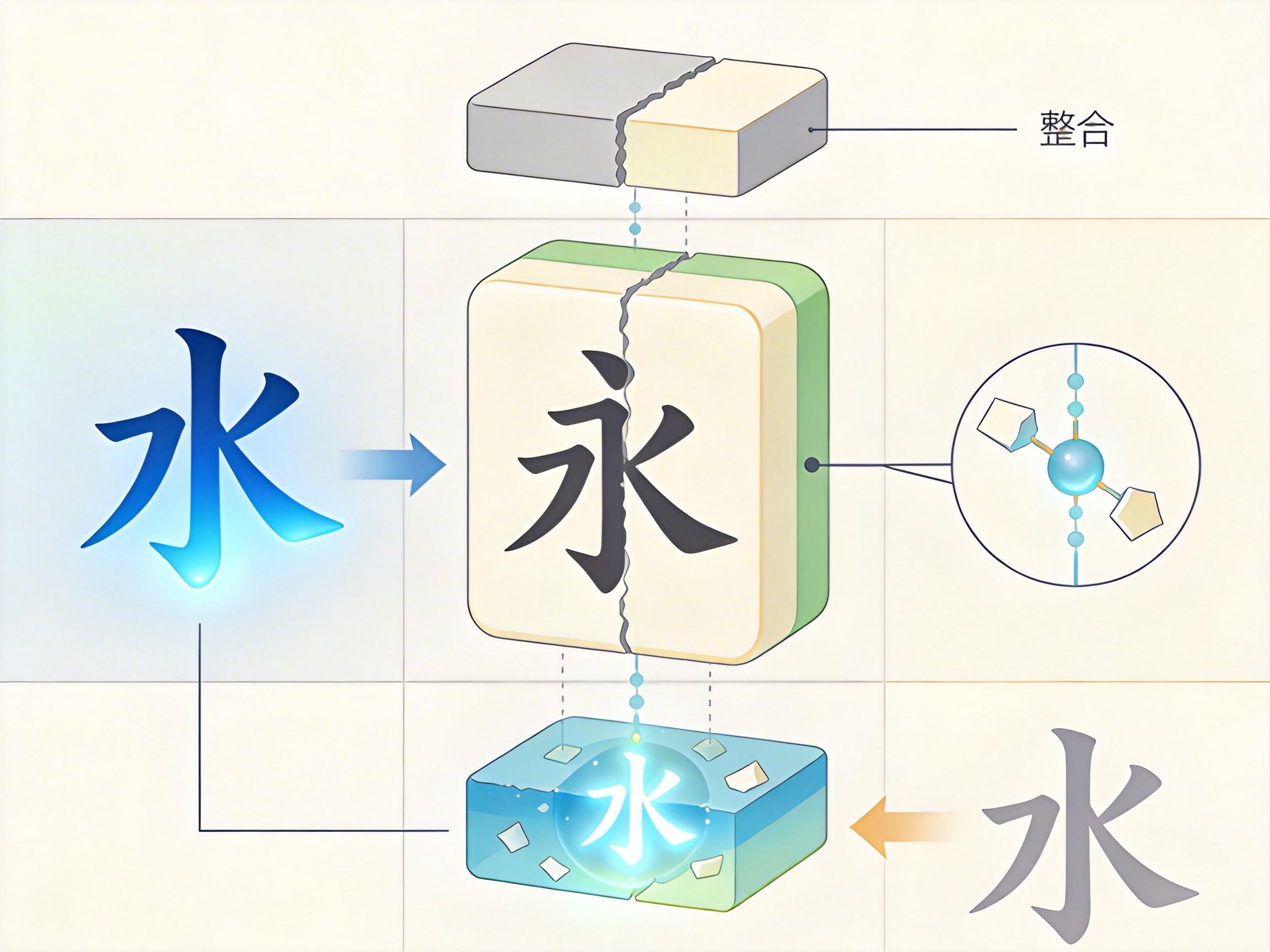
这场中文名的讨论,也折射出Token从技术单位到产业符号的演变。当中国大模型占据全球超60%的Token消费份额,Token已经成了“数字电力”的计量单位——它的价格、效率,直接决定着AI推理的成本和全球化流通的可能。但在技术底层,中文Token的语义错配问题仍未解决:我们的AI能生成流畅的长文,却可能在区分“权利”和“权力”时出错,在理解“差强人意”这类成语的深层语义时失灵。
未来的中文Token机制,不该是拼音文字规则的生硬移植,而该是为中文量身定制的“语义拼图”——它需要能识别偏旁的关联,能感知语境里的词界,能在效率和语义细腻度之间找到平衡。当我们终于为它定下一个精准的中文名时,或许正是中文AI真正读懂中文的开始。
每一个Token的拆分与合并,都是AI学习中文的一次试错,也是我们重新定义语言与机器关系的契机。