对抗知识焦虑,从看懂这条开始
App 下载
数据标注员成AI导师,时薪最高八百元
模型评测|专业知识标注|AI出题老师|数据标注员|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型评测|专业知识标注|AI出题老师|数据标注员|大语言模型|人工智能
当你还以为数据标注是对着图片框选行人、给语音打字幕的“电子厂流水线”时,有些标注员已经拿着每小时800元的时薪,给大模型当起了“出题老师”。他们不再是重复机械劳动的“打工人”,而是需要用金融、医学、法律等专业知识,设计能难住AI的题目,还要像老师批改作业一样,给模型的回答做全维度点评。这种天差地别的变化,正在大模型时代悄悄重构整个数据标注行业。为什么曾经的“低端岗位”突然成了香饽饽?这背后藏着AI进化的核心密码。
你可以把大模型的成长看成一个学生的求学路:预训练阶段就像读万卷书,靠爬取互联网上的海量通用数据,学会基本的语言逻辑和常识。但互联网数据就像良莠不齐的课外书,中文语料仅占全球的1.3%,还充斥着重复、错误甚至矛盾的内容,靠这些喂不出能解决专业问题的“优等生”。
于是,大模型进入了后训练阶段——相当于找名师做针对性辅导,这时候光有书没用,得有人告诉它什么是对的、什么是好的。而最核心的辅导技术,就是**RLHF(人类反馈强化学习)**:先让标注员(也就是“老师”)对模型的多个回答做偏好排序,比如在金融尽调场景里,判断哪份分析更符合真实业务逻辑;再用这些排序数据训练一个“奖励模型”,就像给老师的打分标准做了数字化;最后用强化学习让大模型不断调整输出,直到更贴近人类的专业判断。
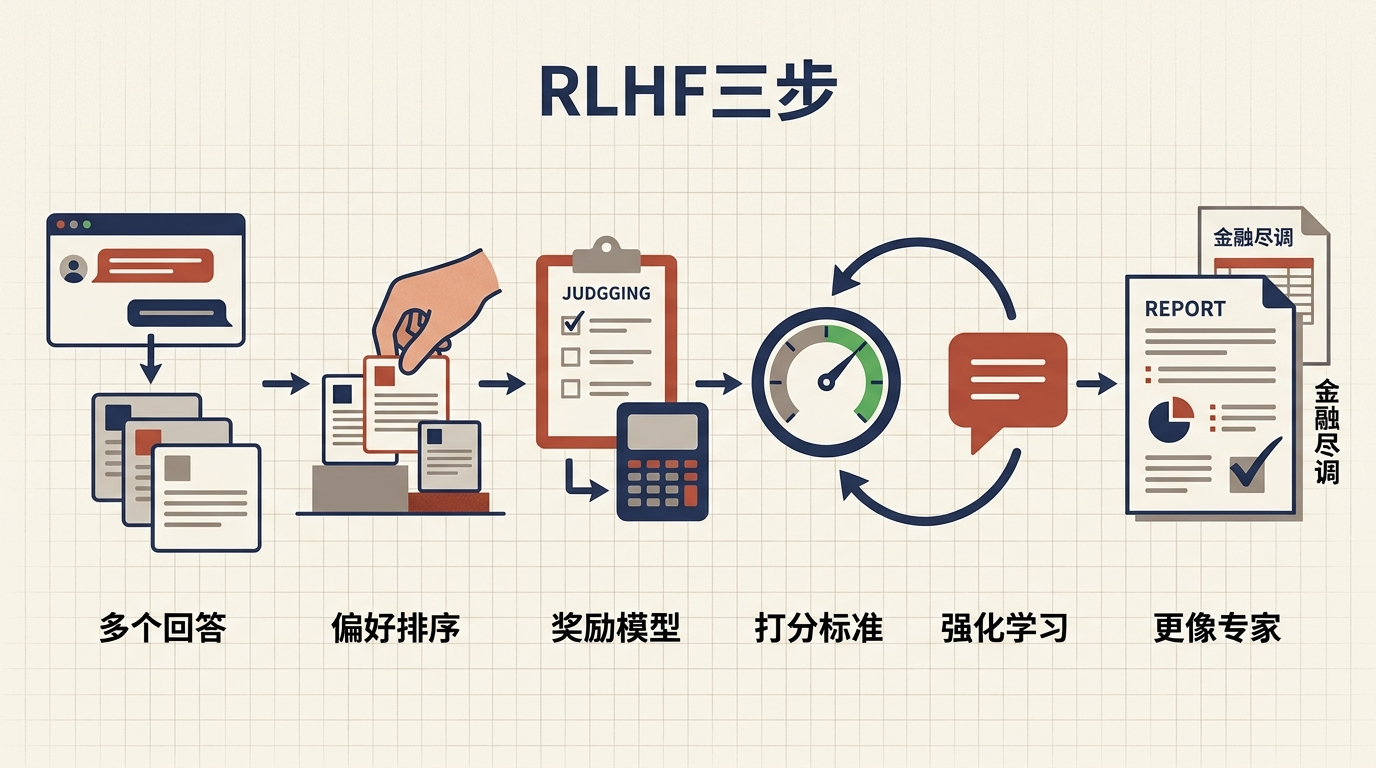
这个过程里,普通标注员根本无法胜任——你得真的懂金融风控的核心,才能看出模型报告里的漏洞;得真的懂医学诊断,才能判断AI给出的治疗方案是否合规。于是,“数据标注员”的名字变成了“数据炼金师”“AI出题专家”,门槛直接跳到硕士以上,专业背景成了硬通货。
同样是和AI打交道,Molly和渊星的日子像是活在两个平行世界。
Molly有十余年金融从业经验,她通过了某大厂专家数据平台的测试——不是靠学历,而是靠能设计出难倒至少两个大模型的金融题目。她的工作是给模型的尽调报告做“终审”:不仅要选出最优报告,还要拆解判断逻辑,比如指出某份报告对政策风险的识别遗漏了哪项新规。她的时薪在300到500元之间,还能在工作中明显看到模型的进步:以前经常搞错的监管新规,现在已经能精准识别了。她觉得自己是在把专业经验共享给AI,再让AI以更低成本服务社会,“很有价值感”。
而刚毕业的渊星,进入了某大厂的AI小说标注外包岗。他有出版经历,却发现工作是高度标准化的流水线:同一个小说指令,要对比多个模型的输出,按给定规则给人物行为合理性、剧情逻辑打分,还要给长篇小说“抽细纲”。工作不轻松,但月薪只有8000元,五险一金按最低标准缴纳。更让他压抑的是,质检员的反馈全是“挑错”,很多所谓的“错误”只是审美差异,这让他和同事们开始怀疑自己的价值。
这种分化不是个例:金融、法律等垂类标注的时薪能到500-800元,而传统标注岗月薪仍停留在三四千元;有人在给AI当导师,有人还在做AI的“流水线工人”。
数据标注行业的专业化转型,解决了大模型的“成长瓶颈”,但也留下了不少待解的难题。
首先是劳动力分层的困境:高端岗位的高薪和价值感固然诱人,但这类岗位多是小时计酬,任务量不稳定,收入并没有看起来那么稳定;而底层标注岗不仅薪资低,还面临着被AI辅助工具替代的风险——现在AI已经能完成基础的预标注,人工只需要复核,这意味着简单重复的标注工作会越来越少,剩下的要么是高端专业岗,要么是更机械的复核岗。
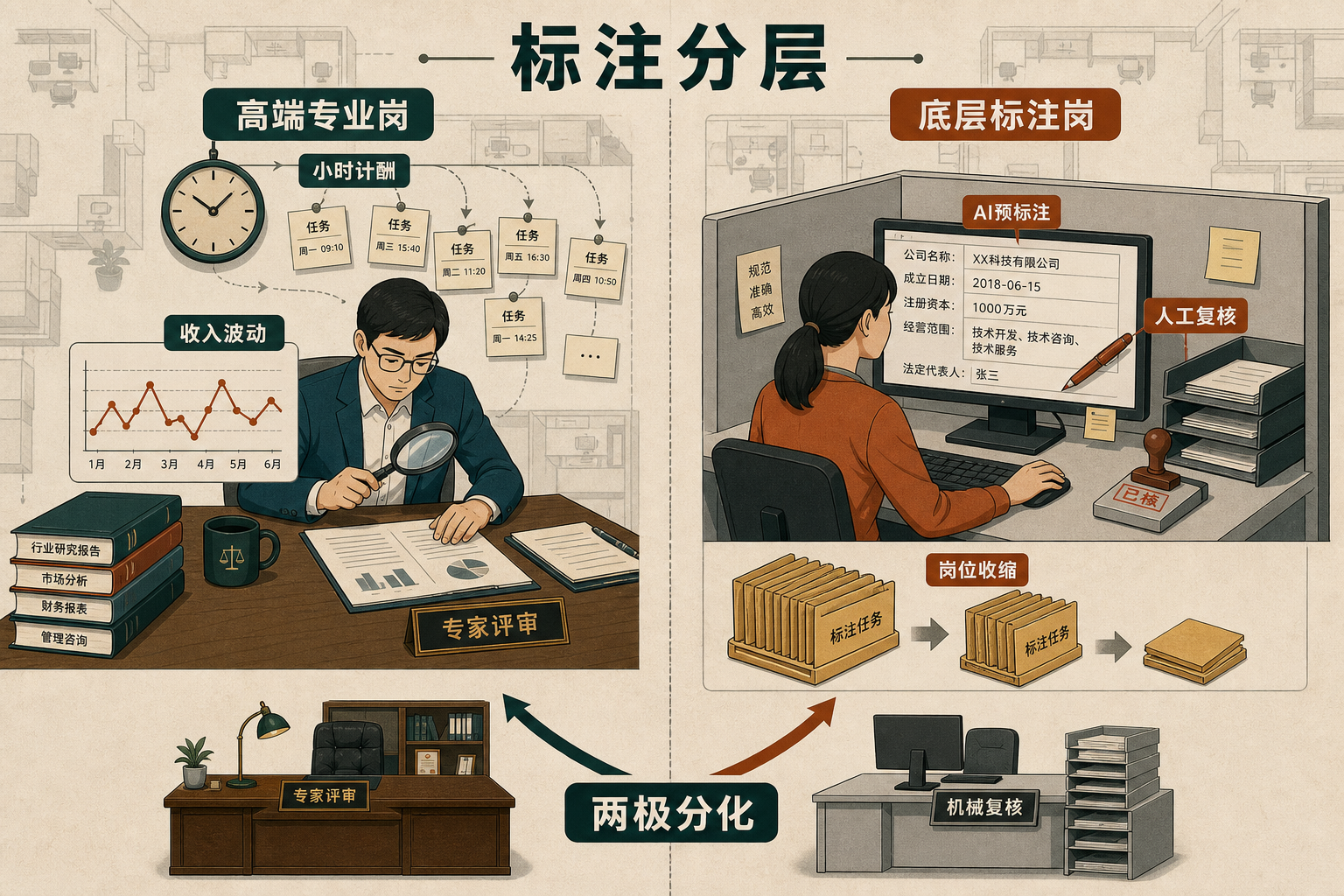
其次是行业标准的缺失:标注工作的主观性很强,比如小说的剧情合理性、法律条文的解读,不同人有不同判断,但很多项目的标注规则却模糊不清,甚至把标注员的个人理解差异当成“错误”。这不仅影响数据质量,还会打击标注员的积极性。
还有伦理与隐私的风险:医疗、金融等垂类标注涉及大量敏感数据,一旦泄露后果严重;而有些标注项目要求标注员处理暴力、色情等不良内容,对心理健康的影响也被忽视。
更关键的是,AI辅助标注的普及虽然提升了效率,但也让标注员的角色变得尴尬:以前是数据的生产者,现在成了AI的“校对工”,未来的职业发展路径在哪里?目前行业里还没有清晰的答案。
当大模型开始向人类学习专业知识,数据标注就不再是简单的“数据加工”,而是人类智慧向机器转移的关键桥梁。我们看到了专业标注员的价值被认可,也看到了底层劳动者的困境被忽视。
人类的经验,才是AI的终极燃料。未来的AI能走多远,不仅取决于技术的进步,更取决于我们如何对待那些把知识注入机器的人——让专业的判断得到应有的回报,让重复的劳动也能有尊严,这才是大模型时代该有的行业生态。毕竟,AI的智慧,终究是人类智慧的镜像。