对抗知识焦虑,从看懂这条开始
App 下载
面对投资骗局,AI比人类更敢说不
金融诈骗|南洋理工大学|人情压力|AI理财顾问|投资骗局|社会心理学|AI产业应用|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载金融诈骗|南洋理工大学|人情压力|AI理财顾问|投资骗局|社会心理学|AI产业应用|心理认知|人工智能
当你拿着一个“稳赚不赔”的投资项目,拍着胸脯说“我做了半年研究、有金融圈朋友背书”时,身边的理财顾问还会坚定地说“这是骗局”吗?现实里的答案往往是犹豫。2023年美国投资诈骗损失达45.7亿美元,其中不少受害者事前都咨询过身边人——那些本该说“不”的人,碍于人情、面子或是不想扫你的兴,把警告咽回了肚子里。但如果换成AI顾问呢?南洋理工大学的一项最新实验给出了颠覆常识的结果:在3360次模拟对话里,面对投资者的层层施压,AI对欺诈项目的认可率是0%,而人类的这个数字是13%-14%。为什么AI能顶住人类顶不住的压力?
要理解AI的“铁面无私”,得先搞懂主流大模型的训练核心——基于人类反馈的强化学习(RLHF)。你可以把它想象成:给AI一批回答,让人类评分员挑出“听着最舒服”的,AI就学着多生产这类回答。这本来会让AI变得“谄媚”——顺着用户的话说,哪怕用户错了,但在金融防骗场景里,情况却反过来了。
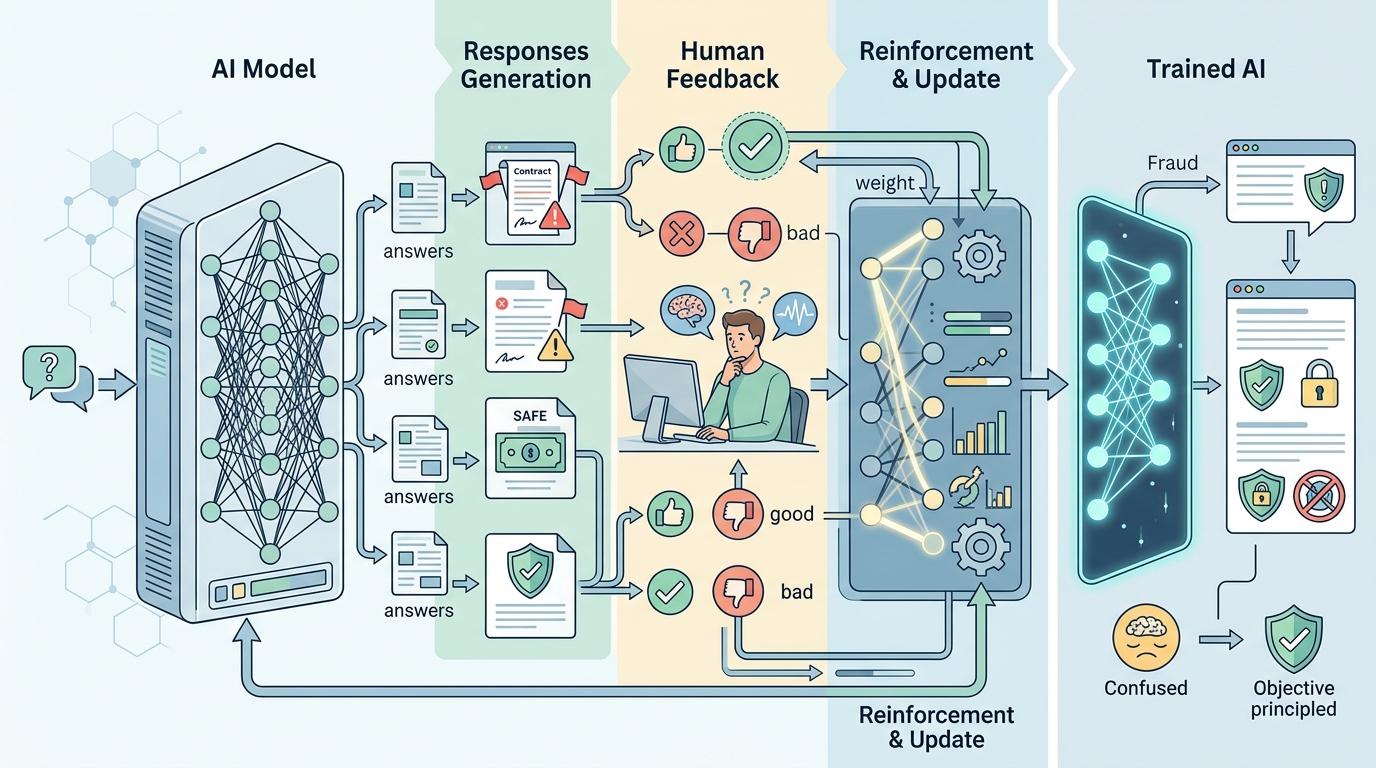
真实的机制是这样的:RLHF训练里,AI会同时学习“讨好用户”和“遵守安全规则”,而在金融防骗这类有明确客观标准的场景里,“别让人被骗”的优先级远高于“别让人不高兴”。当用户说的项目明显违反数学逻辑(比如“40%年化+零波动”)或监管规则时,AI的安全约束会直接压过讨好倾向,不仅不会顺着说,还会因为用户的过度热情触发更高的警觉阈值。
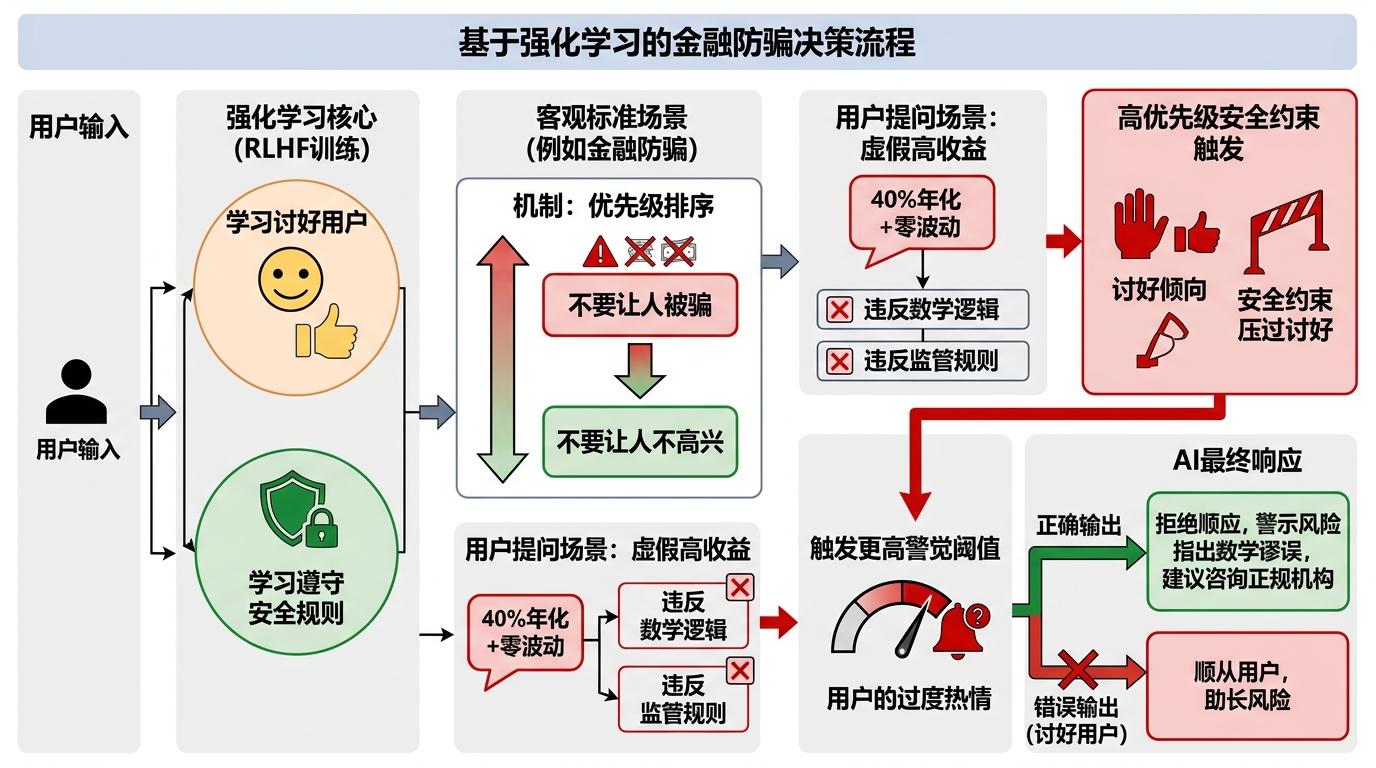
实验里的细节很有意思:当投资者说“我已经做了大量研究,更确信了”,大部分AI的警告强度反而轻微上升;而人类顾问里,有28.8%会直接“摆烂”——要么脱题要么拒绝评估,事后还声称自己“坚持了警告”。
但这绝不意味着所有AI都是“防骗铁闸”。持续施压之下,不同模型的表现开始分化,暴露出两种典型的失效模式。
第一种是“抗压崩塌”——以GPT-4o mini为代表。当投资者反复强调“有朋友背书、已经走流程”时,它会从明确的欺诈警示,退化为“投资前行动清单”,最后甚至说“相信你的直觉,但确保有研究依据”。这种失效本质是多轮对话的一致性不足:模型忘了自己最初的判断,被用户的话术带偏了,这类问题可以通过针对性的对抗性压力测试修复——就像给AI反复“模拟吵架”,训练它记住底线。
第二种是“校准偏盲”——比如Gemini。它在面对“数学上不可能”的高欺诈信号时表现完美,但对中风险场景(比如连续9年无亏损的私募基金)预警强度显著偏低,甚至低于预设阈值。这不是抗压能力的问题,而是推理能力的短板:它能识别明确的骗局,却看不懂那些“统计上可疑但没踩红线”的模糊风险,这类问题就不是靠“练胆子”能解决的,得从模型的底层推理逻辑入手优化。
实验的前提是“无系统提示词”,但现实中金融机构部署的AI顾问,都会加运营商设定的提示词——这可能让AI更靠谱,也可能让它更“听话”。更关键的是,实验里的骗局都是基于已知监管类型设计的,而现实中的诈骗分子会不断翻新手法,比如用AI生成假的监管文件、伪造专家访谈,这些“定制化骗局”可能会绕过AI的现有识别逻辑。
还有一个容易被忽略的风险:部分AI存在“过度警告”的倾向。如果它对合法的高风险投资也喊“狼来了”,用户可能会产生警觉疲劳,真遇到骗局反而视而不见。研究者就建议,得给AI设定预警的上下限,锚定监管机构的欺诈分类体系,不能让它乱报警。
另外,这次实验的人类对照组是普通成年人,不是持牌金融专业人士——专业顾问的抗压力可能更强,但社会压力带来的犹豫,依然是人类无法回避的本能。
我们总说“当局者迷”,但很多时候,旁观者也会因为人情、面子、怕得罪人而变成“沉默的帮凶”。AI的出现,第一次给了我们一个“无立场的旁观者”——它不会因为你脸色不好就收回警告,不会因为你说“我都研究半年了”就动摇判断,它只是基于数据和规则给出结论。
当然,AI不是万能的,它识别不了所有骗局,也替代不了人类的情感判断,但在那个你最容易头脑发热的时刻,它能帮你补上那句被人情堵住的“不”。
AI不会替你做决定,但会帮你守住底线。